 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Generation with Guider Network
Paper and Code
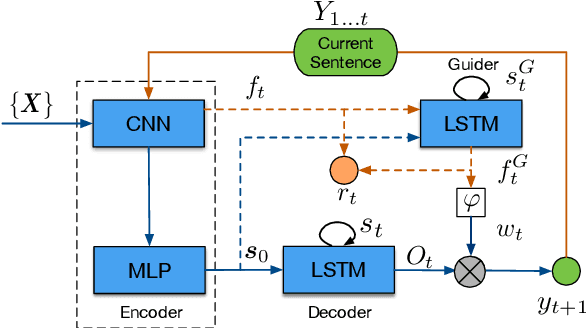
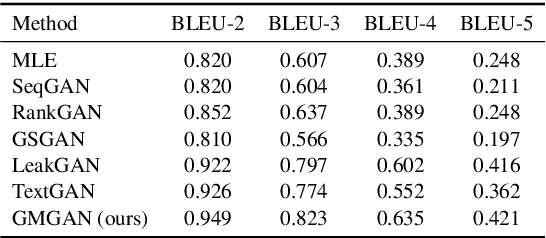
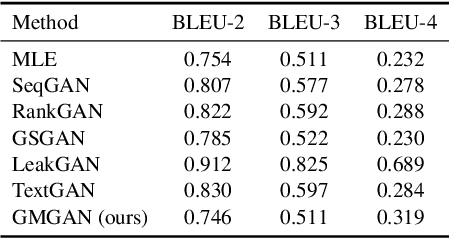
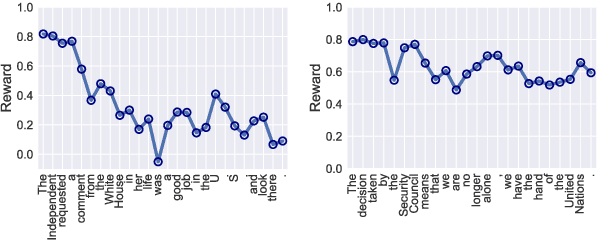
Sequence generation with reinforcement learning (RL) has received significant attention recently. However, a challenge with such methods is the sparse-reward problem in the RL training process, in which a scalar guiding signal is often only available after an entire sequence has been generated. This type of sparse reward tends to ignore the global structural information of a sequence, causing generation of sequences that are semantically inconsistent. In this paper, we present a model-based RL approach to overcome this issue. Specifically, we propose a novel guider network to model the sequence-generation environment, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments show that the proposed method leads to improved performance for both unconditional and conditional sequence-generation tasks.