 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning over Unreliable Networks
Paper and Code
Oct 17, 2018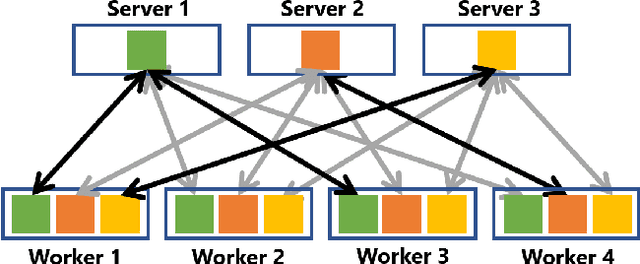
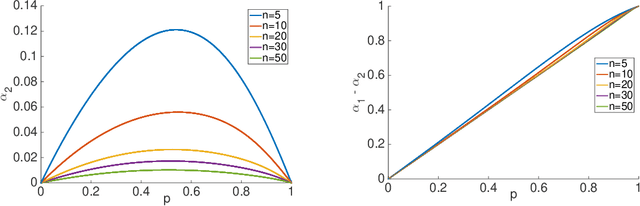
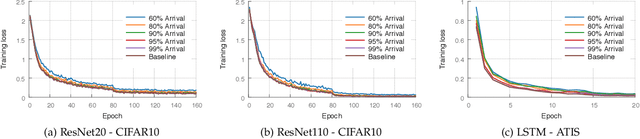
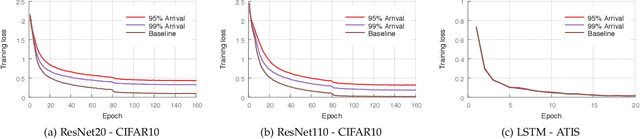
Most of today's distributed machine learning systems assume {\em reliable networks}: whenever two machines exchange information (e.g., gradients or models), the network should guarantee the delivery of the message. At the same time, recent work exhibits the impressive tolerance of machine learning algorithms to errors or noise arising from relaxed communication or synchronization. In this paper, we connect these two trends, and consider the following question: {\em Can we design machine learning systems that are tolerant to network unreliability during training?} With this motivation, we focus on a theoretical problem of independent interest---given a standard distributed parameter server architecture, if every communication between the worker and the server has a non-zero probability $p$ of being dropped, does there exist an algorithm that still converges, and at what speed? In the context of prior art, this problem can be phrased as {\em distributed learning over random topologies}. The technical contribution of this paper is a novel theoretical analysis proving that distributed learning over random topologies can achieve comparable convergence rate to centralized or distributed learning over reliable networks. Further, we prove that the influence of the packet drop rate diminishes with the growth of the number of \textcolor{black}{parameter servers}. We map this theoretical result onto a real-world scenario, training deep neural networks over an unreliable network layer, and conduct network simulation to validate the system improvement by allowing the networks to be unreliable.