 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Neural Machine Translation with Joint Textual and Phonetic Embedding
Paper and Code

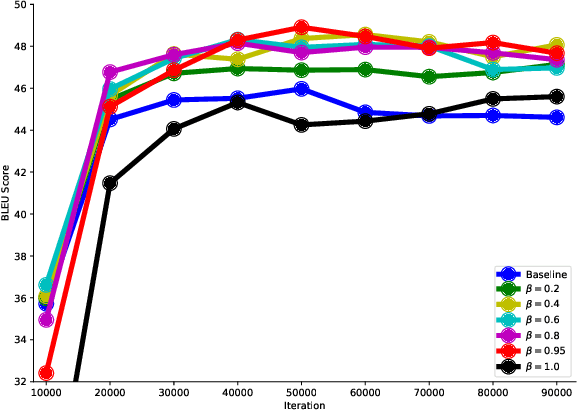
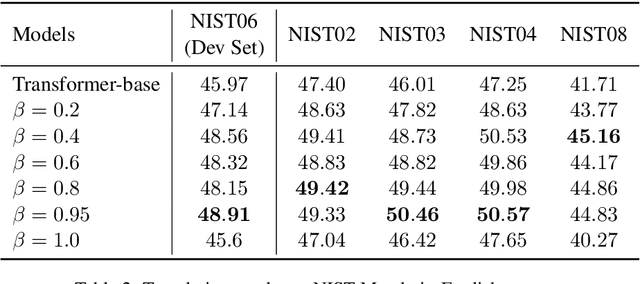
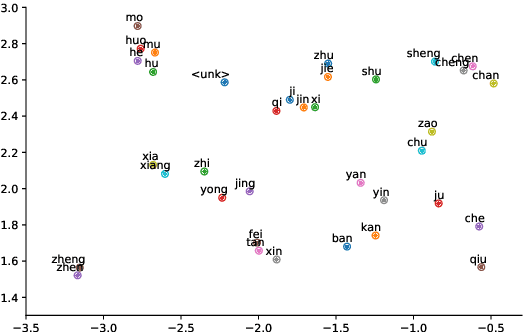
Neural machine translation (NMT) is notoriously sensitive to noises, but noises are almost inevitable in practice. One special kind of noise is the homophone noise, where words are replaced by other words with the same (or similar) pronunciations. Homophone noise arises frequently from many real-world scenarios upstream to translation, such as automatic speech recognition (ASR) or phonetic-based input systems. We propose to improve the robustness of NMT to homophone noise by 1) jointly embedding both textual and phonetic information of source sentences, and 2) augmenting the training dataset with homophone noise. Interestingly, we found that in order to achieve the best translation quality, most (though not all) weights should be put on the phonetic rather than textual information, where the latter is only used as auxiliary information. Experiments show that our method not only significantly improves the robustness of NMT to homophone noise, which is expected but also surprisingly improves the translation quality on clean test sets.