 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Blind Video Temporal Consistency
Paper and Code
Aug 01, 2018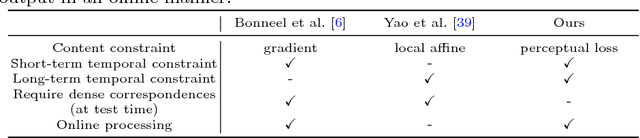
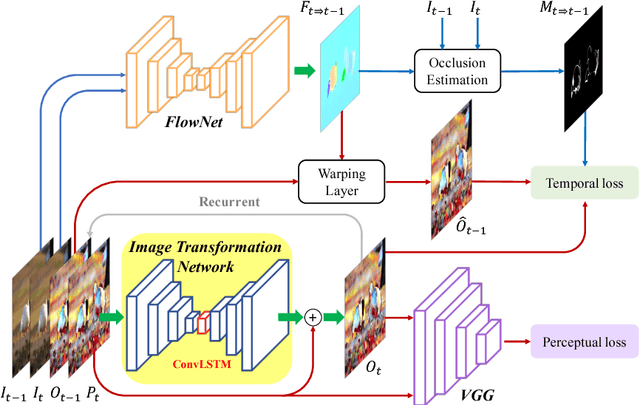
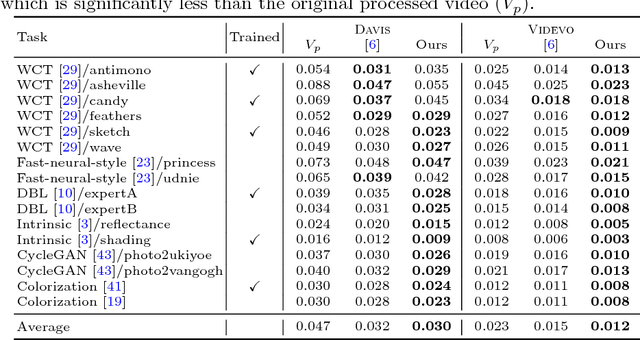
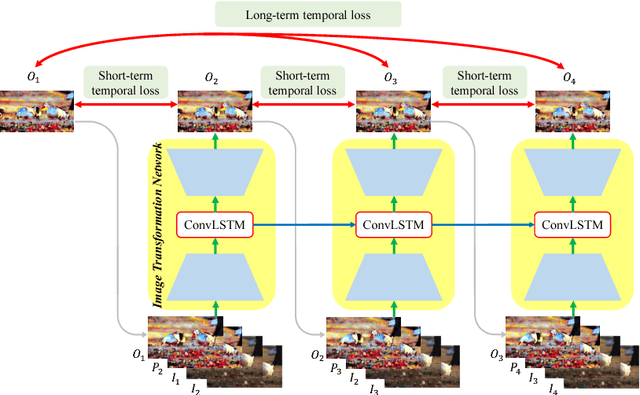
Applying image processing algorithms independently to each frame of a video often leads to undesired inconsistent results over time. Developing temporally consistent video-based extensions, however, requires domain knowledge for individual tasks and is unable to generalize to other applications. In this paper, we present an efficient end-to-end approach based on deep recurrent network for enforcing temporal consistency in a video. Our method takes the original unprocessed and per-frame processed videos as inputs to produce a temporally consistent video. Consequently, our approach is agnostic to specific image processing algorithms applied on the original video. We train the proposed network by minimizing both short-term and long-term temporal losses as well as the perceptual loss to strike a balance between temporal stability and perceptual similarity with the processed frames. At test time, our model does not require computing optical flow and thus achieves real-time speed even for high-resolution videos. We show that our single model can handle multiple and unseen tasks, including but not limited to artistic style transfer, enhancement, colorization, image-to-image translation and intrinsic image decomposition. Extensive objective evaluation and subject study demonstrate that the proposed approach performs favorably against the state-of-the-art methods on various types of videos.