 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-effective Object Detection: Active Sample Mining with Switchable Selection Criteria
Paper and Code
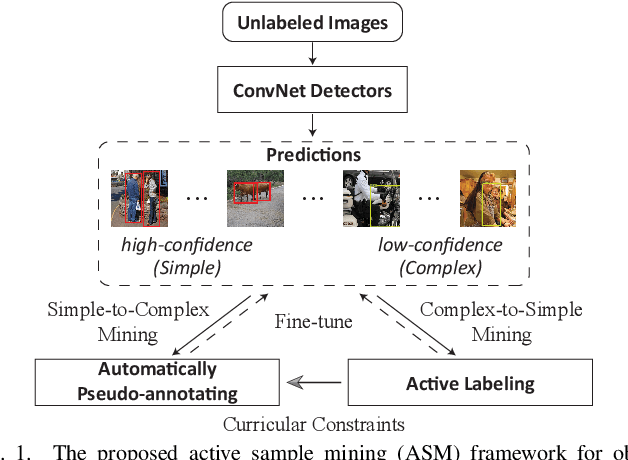
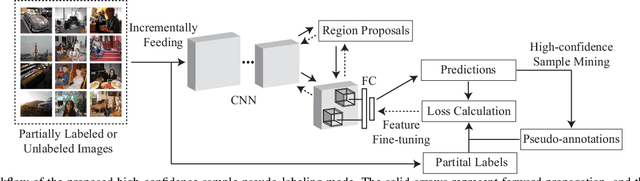
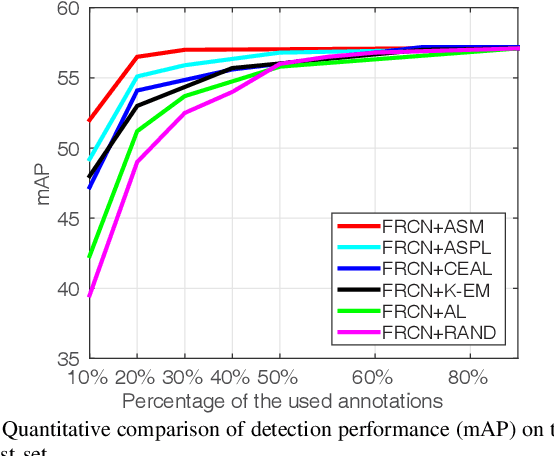

Though quite challenging, the training of object detectors using large-scale unlabeled or partially labeled datasets has attracted increasing interests from researchers due to its fundamental importance for applications of neural networks and learning systems. To address this problem, many active learning (AL) methods have been proposed that employ up-to-date detectors to retrieve representative minority samples according to predefined confidence or uncertainty thresholds. However, these AL methods cause the detectors to ignore the remaining majority samples (i.e., those with low uncertainty or high prediction confidence). In this work, by developing a principled active sample mining (ASM) framework, we demonstrate that cost-effectively mining samples from these unlabeled majority data is key to training more powerful object detectors while minimizing user effort. Specifically, our ASM framework involves a selectively switchable sample selection mechanism for determining whether an unlabeled sample should be manually annotated via AL or automatically pseudo-labeled via a novel self-learning process. The proposed process can be compatible with mini-batch based training (i.e., using a batch of unlabeled or partially labeled data as a one-time input) for object detection. Extensive experiments on two public benchmarks clearly demonstrate that our ASM framework can achieve performance comparable to that of alternative methods but with significantly fewer annotations.