Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum a Posteriori Policy Optimisation
Paper and Code
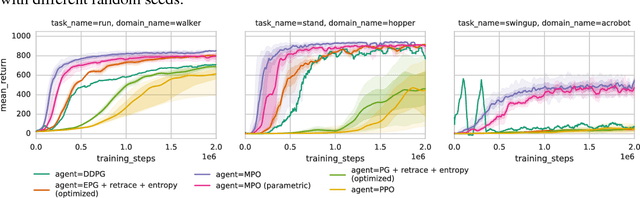
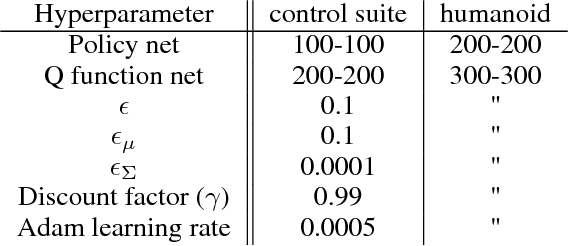
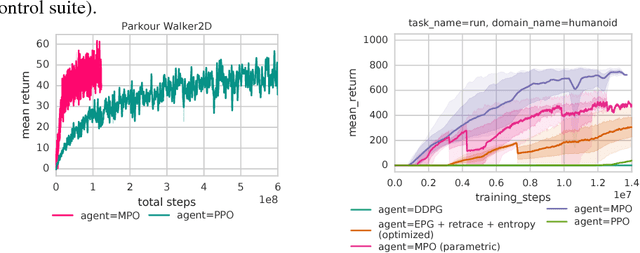
We introduce a new algorithm for reinforcement learning called Maximum aposteriori Policy Optimisation (MPO) based on coordinate ascent on a relative entropy objective. We show that several existing methods can directly be related to our derivation. We develop two off-policy algorithms and demonstrate that they are competitive with the state-of-the-art in deep reinforcement learning. In particular, for continuous control, our method outperforms existing methods with respect to sample efficiency, premature convergence and robustness to hyperparameter settings while achieving similar or better final performance.
View paper on
 OpenReview
OpenReview