 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Structured Reinforcement Learning for Topically Coherent Visual Story Generation
Paper and Code
Sep 07, 2018
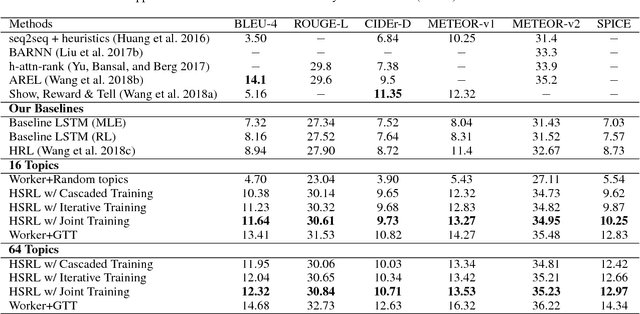

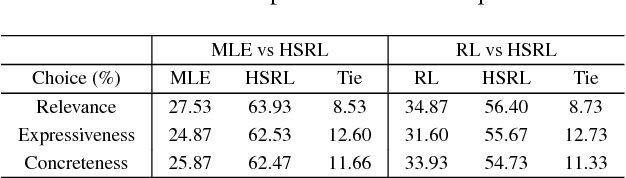
We propose a hierarchically structured reinforcement learning approach to address the challenges of planning for generating coherent multi-sentence stories for the visual storytelling task. Within our framework, the task of generating a story given a sequence of images is divided across a two-level hierarchical decoder. The high-level decoder constructs a plan by generating a semantic concept (i.e., topic) for each image in sequence. The low-level decoder generates a sentence for each image using a semantic compositional network, which effectively grounds the sentence generation conditioned on the topic. The two decoders are jointly trained end-to-end using reinforcement learning. We evaluate our model on the visual storytelling (VIST) dataset. Empirical results from both automatic and human evaluations demonstrate that the proposed hierarchically structured reinforced training achieves significantly better performance compared to a strong flat deep reinforcement learning baseline.