 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Output Distribution of Abstractive Chinese Social Media Text Summarization for Improved Semantic Consistency
Paper and Code
May 10, 2018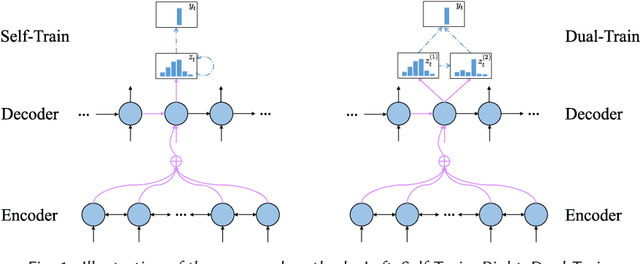
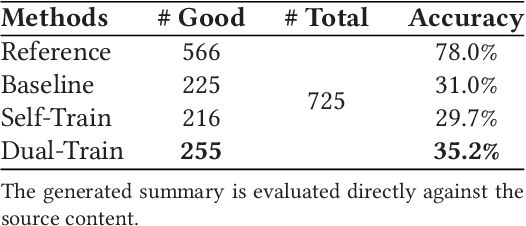
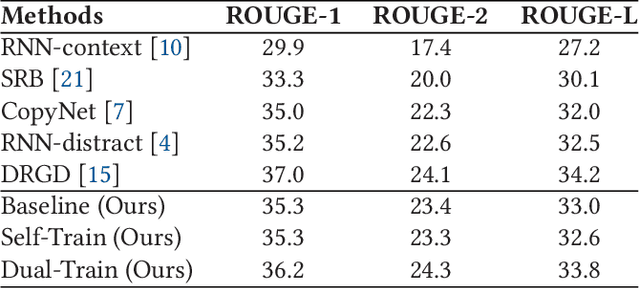
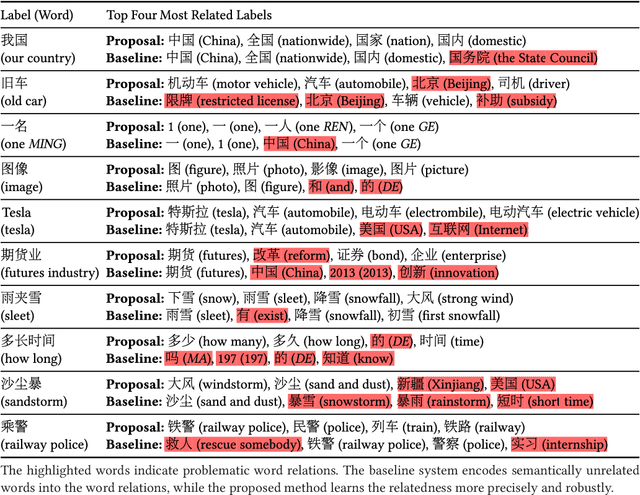
Abstractive text summarization is a highly difficult problem, and the sequence-to-sequence model has shown success in improving the performance on the task. However, the generated summaries are often inconsistent with the source content in semantics. In such cases, when generating summaries, the model selects semantically unrelated words with respect to the source content as the most probable output. The problem can be attributed to heuristically constructed training data, where summaries can be unrelated to the source content, thus containing semantically unrelated words and spurious word correspondence. In this paper, we propose a regularization approach for the sequence-to-sequence model and make use of what the model has learned to regularize the learning objective to alleviate the effect of the problem. In addition, we propose a practical human evaluation method to address the problem that the existing automatic evaluation method does not evaluate the semantic consistency with the source content properly. Experimental results demonstrate the effectiveness of the proposed approach, which outperforms almost all the existing models. Especially, the proposed approach improves the semantic consistency by 4\% in terms of human evaluation.