 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Encoding for Semantic Segmentation
Paper and Code

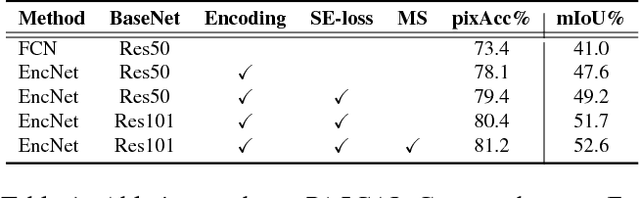
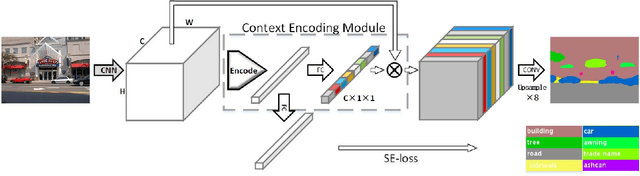
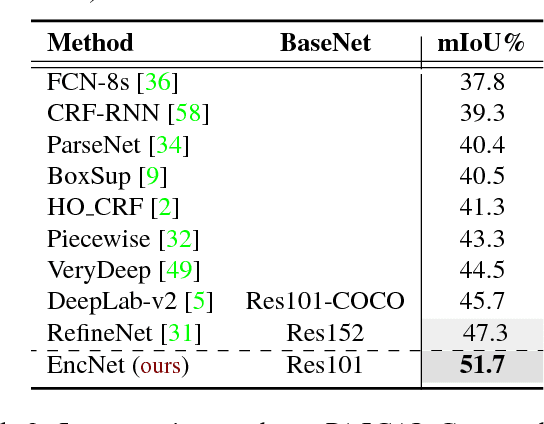
Recent work has made significant progress in improving spatial resolution for pixelwise labeling with Fully Convolutional Network (FCN) framework by employing Dilated/Atrous convolution, utilizing multi-scale features and refining boundaries. In this paper, we explore the impact of global contextual information in semantic segmentation by introducing the Context Encoding Module, which captures the semantic context of scenes and selectively highlights class-dependent featuremaps. The proposed Context Encoding Module significantly improves semantic segmentation results with only marginal extra computation cost over FCN. Our approach has achieved new state-of-the-art results 51.7% mIoU on PASCAL-Context, 85.9% mIoU on PASCAL VOC 2012. Our single model achieves a final score of 0.5567 on ADE20K test set, which surpass the winning entry of COCO-Place Challenge in 2017. In addition, we also explore how the Context Encoding Module can improve the feature representation of relatively shallow networks for the image classification on CIFAR-10 dataset. Our 14 layer network has achieved an error rate of 3.45%, which is comparable with state-of-the-art approaches with over 10 times more layers. The source code for the complete system are publicly available.