 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigendecomposition-free Training of Deep Networks with Zero Eigenvalue-based Losses
Paper and Code
Mar 26, 2018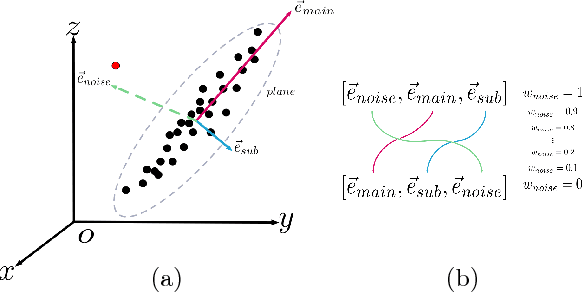
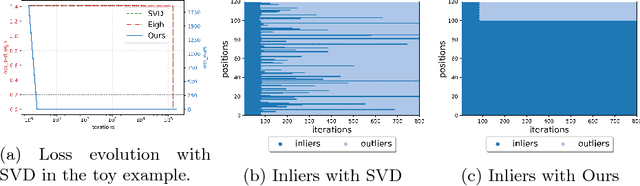
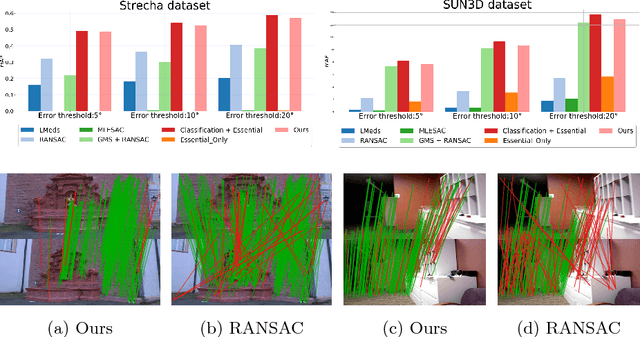
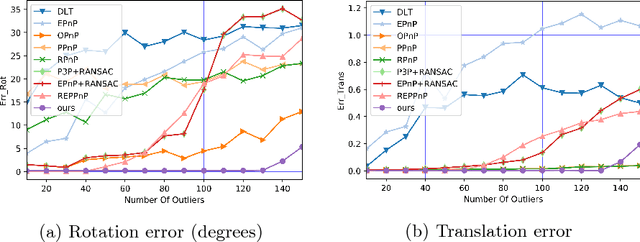
Many classical Computer Vision problems, such as essential matrix computation and pose estimation from 3D to 2D correspondences, can be solved by finding the eigenvector corresponding to the smallest, or zero, eigenvalue of a matrix representing a linear system. Incorporating this in deep learning frameworks would allow us to explicitly encode known notions of geometry, instead of having the network implicitly learn them from data. However, performing eigendecomposition within a network requires the ability to differentiate this operation. Unfortunately, while theoretically doable, this introduces numerical instability in the optimization process in practice. In this paper, we introduce an eigendecomposition-free approach to training a deep network whose loss depends on the eigenvector corresponding to a zero eigenvalue of a matrix predicted by the network. We demonstrate on several tasks, including keypoint matching and 3D pose estimation, that our approach is much more robust than explicit differentiation of the eigendecomposition, It has better convergence properties and yields state-of-the-art results on both tasks.