 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSE-ens: Visual-Semantic Embeddings with Efficient Negative Sampling
Paper and Code
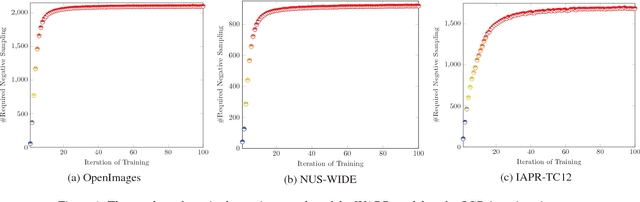
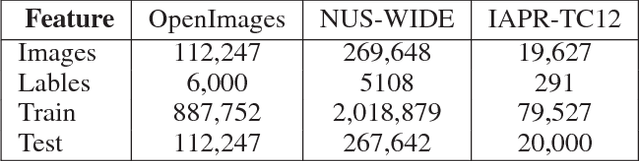
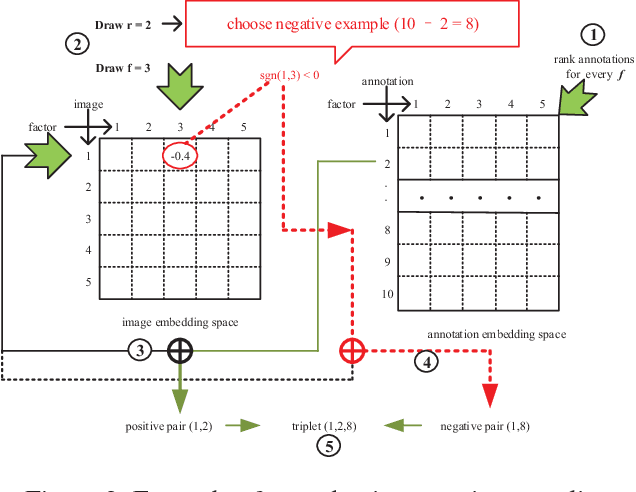
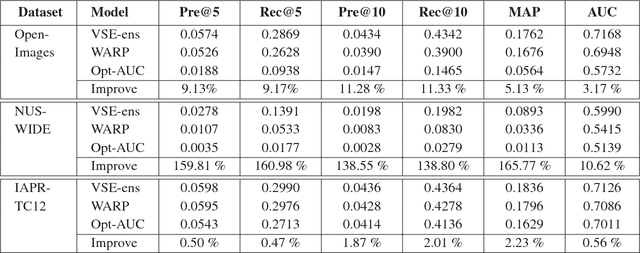
Jointing visual-semantic embeddings (VSE) have become a research hotpot for the task of image annotation, which suffers from the issue of semantic gap, i.e., the gap between images' visual features (low-level) and labels' semantic features (high-level). This issue will be even more challenging if visual features cannot be retrieved from images, that is, when images are only denoted by numerical IDs as given in some real datasets. The typical way of existing VSE methods is to perform a uniform sampling method for negative examples that violate the ranking order against positive examples, which requires a time-consuming search in the whole label space. In this paper, we propose a fast adaptive negative sampler that can work well in the settings of no figure pixels available. Our sampling strategy is to choose the negative examples that are most likely to meet the requirements of violation according to the latent factors of images. In this way, our approach can linearly scale up to large datasets. The experiments demonstrate that our approach converges 5.02x faster than the state-of-the-art approaches on OpenImages, 2.5x on IAPR-TCI2 and 2.06x on NUS-WIDE datasets, as well as better ranking accuracy across datasets.