 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analysis of incorporating an external language model into a sequence-to-sequence model
Paper and Code
Dec 06, 2017

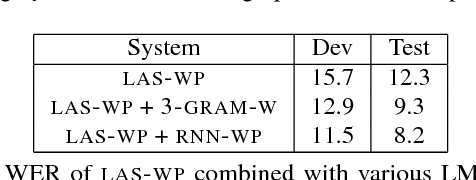

Attention-based sequence-to-sequence models for automatic speech recognition jointly train an acoustic model, language model, and alignment mechanism. Thus, the language model component is only trained on transcribed audio-text pairs. This leads to the use of shallow fusion with an external language model at inference time. Shallow fusion refers to log-linear interpolation with a separately trained language model at each step of the beam search. In this work, we investigate the behavior of shallow fusion across a range of conditions: different types of language models, different decoding units, and different tasks. On Google Voice Search, we demonstrate that the use of shallow fusion with a neural LM with wordpieces yields a 9.1% relative word error rate reduction (WERR) over our competitive attention-based sequence-to-sequence model, obviating the need for second-pass rescoring.