 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of Online Neural Transducer Models
Paper and Code
Dec 05, 2017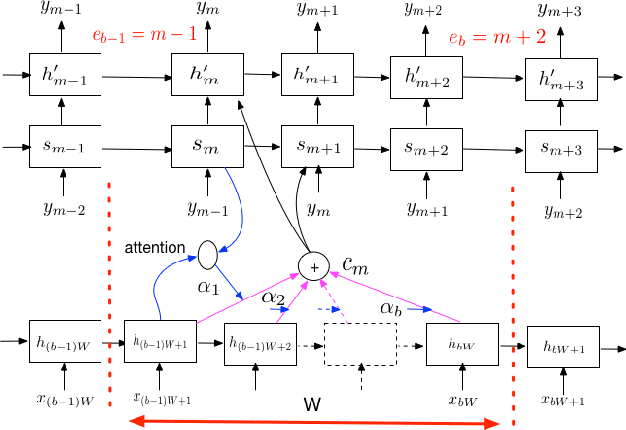
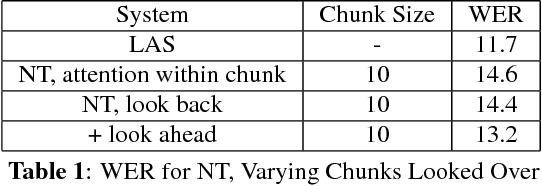
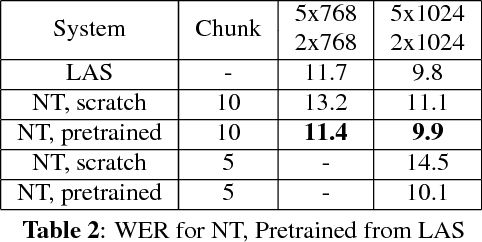
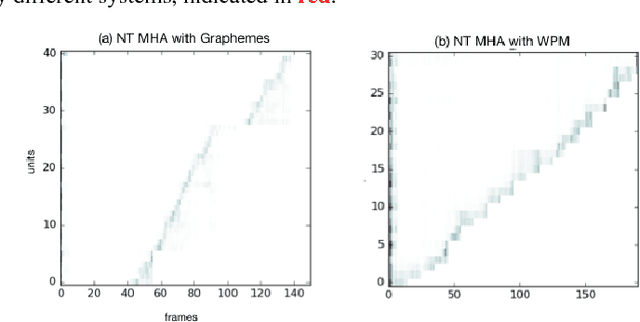
Having a sequence-to-sequence model which can operate in an online fashion is important for streaming applications such as Voice Search. Neural transducer is a streaming sequence-to-sequence model, but has shown a significant degradation in performance compared to non-streaming models such as Listen, Attend and Spell (LAS). In this paper, we present various improvements to NT. Specifically, we look at increasing the window over which NT computes attention, mainly by looking backwards in time so the model still remains online. In addition, we explore initializing a NT model from a LAS-trained model so that it is guided with a better alignment. Finally, we explore including stronger language models such as using wordpiece models, and applying an external LM during the beam search. On a Voice Search task, we find with these improvements we can get NT to match the performance of LAS.