 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEGCloud: Semantic Segmentation of 3D Point Clouds
Paper and Code
Oct 20, 2017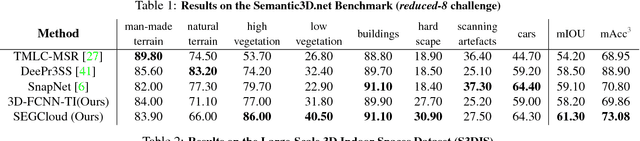
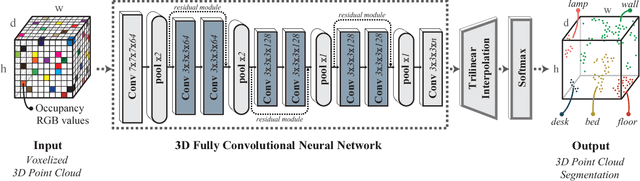
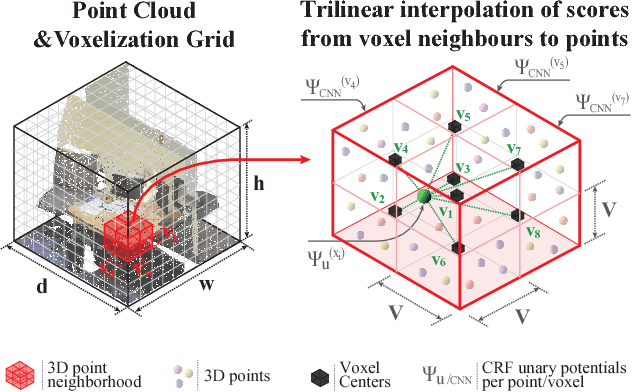

3D semantic scene labeling is fundamental to agents operating in the real world. In particular, labeling raw 3D point sets from sensors provides fine-grained semantics. Recent works leverage the capabilities of Neural Networks (NNs), but are limited to coarse voxel predictions and do not explicitly enforce global consistency. We present SEGCloud, an end-to-end framework to obtain 3D point-level segmentation that combines the advantages of NNs, trilinear interpolation(TI) and fully connected Conditional Random Fields (FC-CRF). Coarse voxel predictions from a 3D Fully Convolutional NN are transferred back to the raw 3D points via trilinear interpolation. Then the FC-CRF enforces global consistency and provides fine-grained semantics on the points. We implement the latter as a differentiable Recurrent NN to allow joint optimization. We evaluate the framework on two indoor and two outdoor 3D datasets (NYU V2, S3DIS, KITTI, Semantic3D.net), and show performance comparable or superior to the state-of-the-art on all datasets.