 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parallel Translating Embedding For Knowledge Graphs
Paper and Code

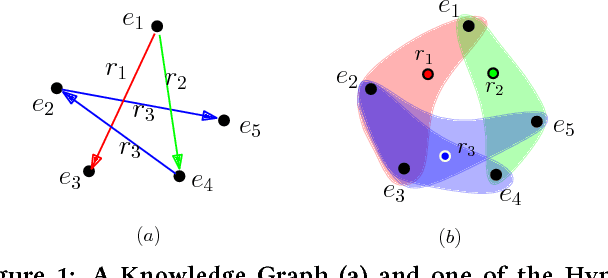
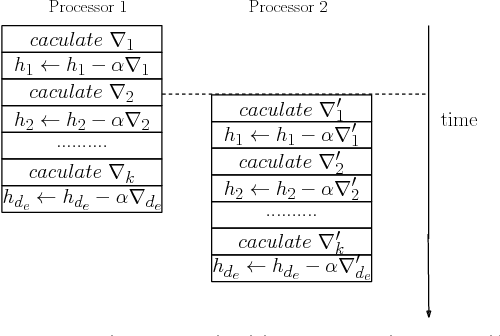

Knowledge graph embedding aims to embed entities and relations of knowledge graphs into low-dimensional vector spaces. Translating embedding methods regard relations as the translation from head entities to tail entities, which achieve the state-of-the-art results among knowledge graph embedding methods. However, a major limitation of these methods is the time consuming training process, which may take several days or even weeks for large knowledge graphs, and result in great difficulty in practical applications. In this paper, we propose an efficient parallel framework for translating embedding methods, called ParTrans-X, which enables the methods to be paralleled without locks by utilizing the distinguished structures of knowledge graphs. Experiments on two datasets with three typical translating embedding methods, i.e., TransE [3], TransH [17], and a more efficient variant TransE- AdaGrad [10] validate that ParTrans-X can speed up the training process by more than an order of magnitude.