 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerson Re-Identification by Unsupervised Video Matching
Paper and Code
Nov 28, 2016
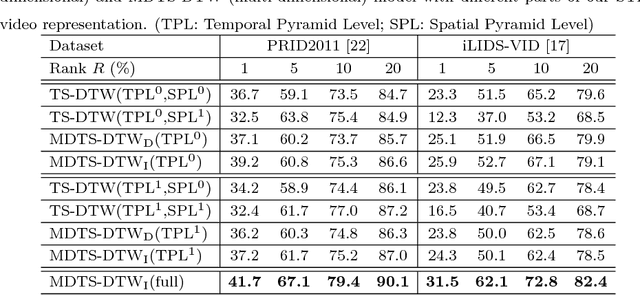

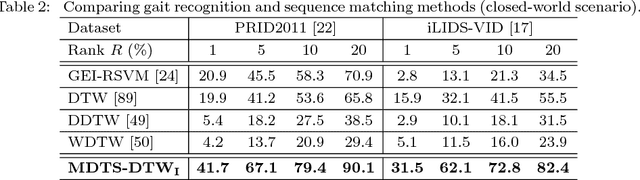
Most existing person re-identification (ReID) methods rely only on the spatial appearance information from either one or multiple person images, whilst ignore the space-time cues readily available in video or image-sequence data. Moreover, they often assume the availability of exhaustively labelled cross-view pairwise data for every camera pair, making them non-scalable to ReID applications in real-world large scale camera networks. In this work, we introduce a novel video based person ReID method capable of accurately matching people across views from arbitrary unaligned image-sequences without any labelled pairwise data. Specifically, we introduce a new space-time person representation by encoding multiple granularities of spatio-temporal dynamics in form of time series. Moreover, a Time Shift Dynamic Time Warping (TS-DTW) model is derived for performing automatically alignment whilst achieving data selection and matching between inherently inaccurate and incomplete sequences in a unified way. We further extend the TS-DTW model for accommodating multiple feature-sequences of an image-sequence in order to fuse information from different descriptions. Crucially, this model does not require pairwise labelled training data (i.e. unsupervised) therefore readily scalable to large scale camera networks of arbitrary camera pairs without the need for exhaustive data annotation for every camera pair. We show the effectiveness and advantages of the proposed method by extensive comparisons with related state-of-the-art approaches using two benchmarking ReID datasets, PRID2011 and iLIDS-VID.