 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Pose Estimation from Depth Images via Inference Embedded Multi-task Learning
Paper and Code
Aug 13, 2016
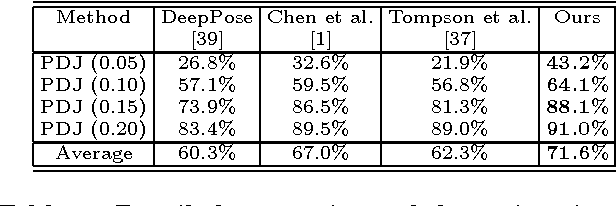
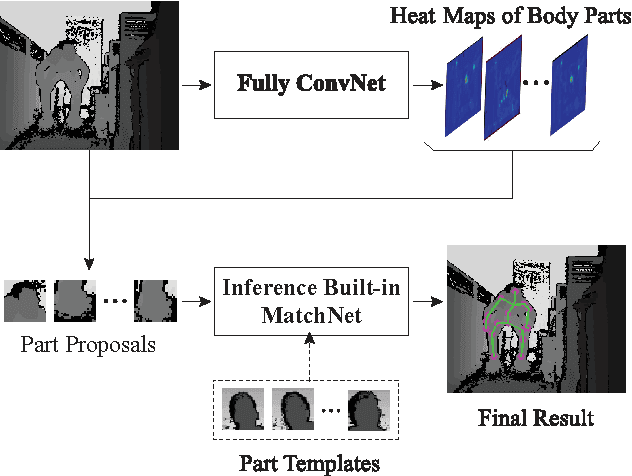

Human pose estimation (i.e., locating the body parts / joints of a person) is a fundamental problem in human-computer interaction and multimedia applications. Significant progress has been made based on the development of depth sensors, i.e., accessible human pose prediction from still depth images [32]. However, most of the existing approaches to this problem involve several components/models that are independently designed and optimized, leading to suboptimal performances. In this paper, we propose a novel inference-embedded multi-task learning framework for predicting human pose from still depth images, which is implemented with a deep architecture of neural networks. Specifically, we handle two cascaded tasks: i) generating the heat (confidence) maps of body parts via a fully convolutional network (FCN); ii) seeking the optimal configuration of body parts based on the detected body part proposals via an inference built-in MatchNet [10], which measures the appearance and geometric kinematic compatibility of body parts and embodies the dynamic programming inference as an extra network layer. These two tasks are jointly optimized. Our extensive experiments show that the proposed deep model significantly improves the accuracy of human pose estimation over other several state-of-the-art methods or SDKs. We also release a large-scale dataset for comparison, which includes 100K depth images under challenging scenarios.