 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiresolution Recurrent Neural Networks: An Application to Dialogue Response Generation
Paper and Code
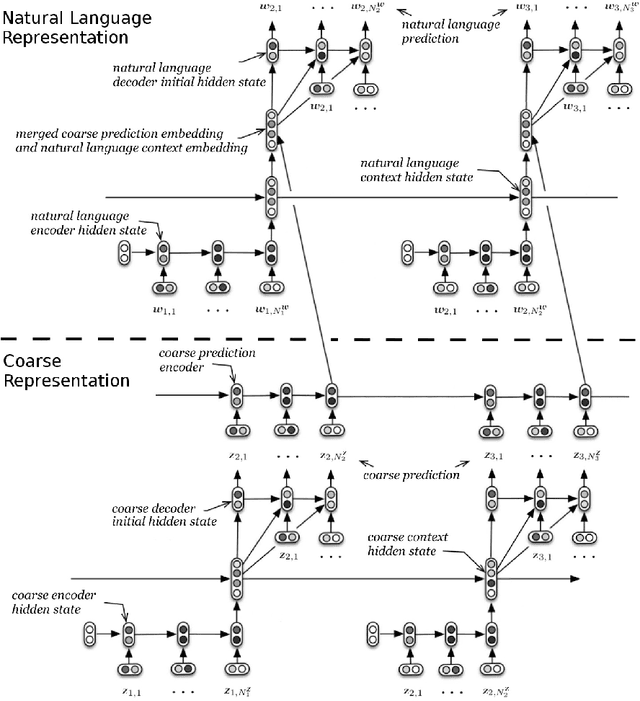
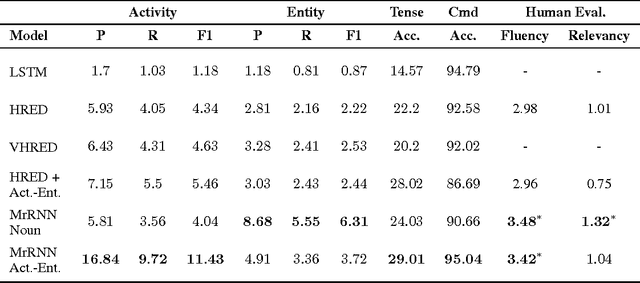

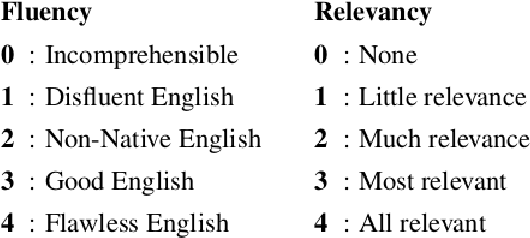
We introduce the multiresolution recurrent neural network, which extends the sequence-to-sequence framework to model natural language generation as two parallel discrete stochastic processes: a sequence of high-level coarse tokens, and a sequence of natural language tokens. There are many ways to estimate or learn the high-level coarse tokens, but we argue that a simple extraction procedure is sufficient to capture a wealth of high-level discourse semantics. Such procedure allows training the multiresolution recurrent neural network by maximizing the exact joint log-likelihood over both sequences. In contrast to the standard log- likelihood objective w.r.t. natural language tokens (word perplexity), optimizing the joint log-likelihood biases the model towards modeling high-level abstractions. We apply the proposed model to the task of dialogue response generation in two challenging domains: the Ubuntu technical support domain, and Twitter conversations. On Ubuntu, the model outperforms competing approaches by a substantial margin, achieving state-of-the-art results according to both automatic evaluation metrics and a human evaluation study. On Twitter, the model appears to generate more relevant and on-topic responses according to automatic evaluation metrics. Finally, our experiments demonstrate that the proposed model is more adept at overcoming the sparsity of natural language and is better able to capture long-term structure.