 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Aggregated Network for Face Video Representation
Paper and Code
Mar 22, 2016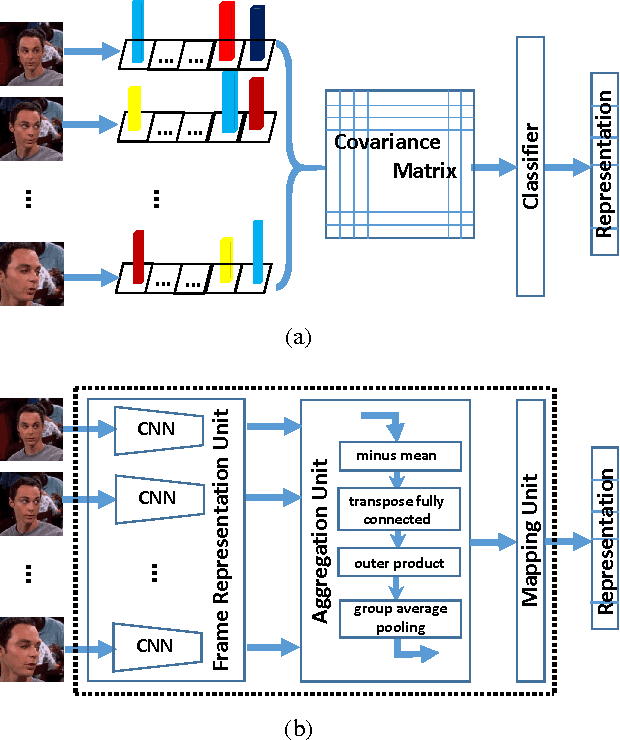

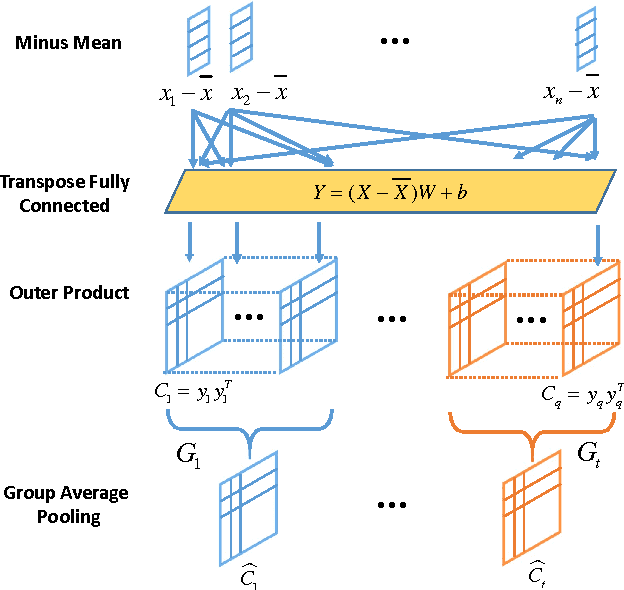
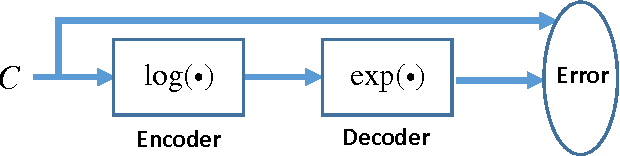
Recently, deep neural network has shown promising performance in face image recognition. The inputs of most networks are face images, and there is hardly any work reported in literature on network with face videos as input. To sufficiently discover the useful information contained in face videos, we present a novel network architecture called input aggregated network which is able to learn fixed-length representations for variable-length face videos. To accomplish this goal, an aggregation unit is designed to model a face video with various frames as a point on a Riemannian manifold, and the mapping unit aims at mapping the point into high-dimensional space where face videos belonging to the same subject are close-by and others are distant. These two units together with the frame representation unit build an end-to-end learning system which can learn representations of face videos for the specific tasks. Experiments on two public face video datasets demonstrate the effectiveness of the proposed network.