 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergent Learning: Do different neural networks learn the same representations?
Paper and Code

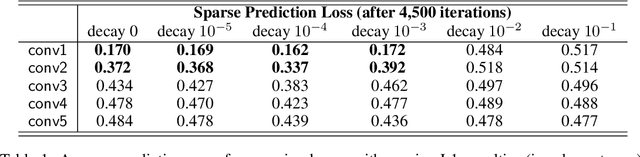

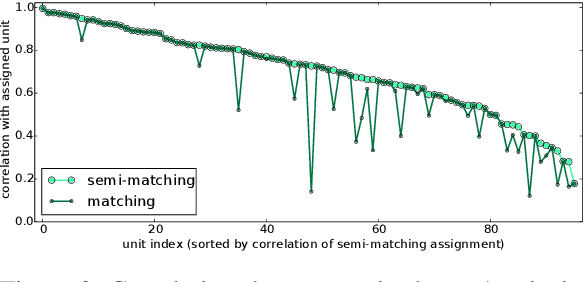
Recent success in training deep neural networks have prompted active investigation into the features learned on their intermediate layers. Such research is difficult because it requires making sense of non-linear computations performed by millions of parameters, but valuable because it increases our ability to understand current models and create improved versions of them. In this paper we investigate the extent to which neural networks exhibit what we call convergent learning, which is when the representations learned by multiple nets converge to a set of features which are either individually similar between networks or where subsets of features span similar low-dimensional spaces. We propose a specific method of probing representations: training multiple networks and then comparing and contrasting their individual, learned representations at the level of neurons or groups of neurons. We begin research into this question using three techniques to approximately align different neural networks on a feature level: a bipartite matching approach that makes one-to-one assignments between neurons, a sparse prediction approach that finds one-to-many mappings, and a spectral clustering approach that finds many-to-many mappings. This initial investigation reveals a few previously unknown properties of neural networks, and we argue that future research into the question of convergent learning will yield many more. The insights described here include (1) that some features are learned reliably in multiple networks, yet other features are not consistently learned; (2) that units learn to span low-dimensional subspaces and, while these subspaces are common to multiple networks, the specific basis vectors learned are not; (3) that the representation codes show evidence of being a mix between a local code and slightly, but not fully, distributed codes across multiple units.