 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Neural Network Policies with Continuous Memory States
Paper and Code
Sep 23, 2015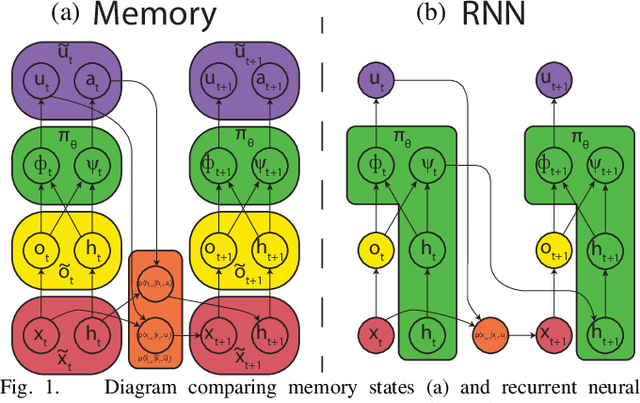
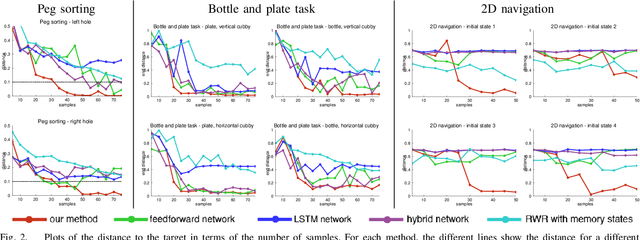
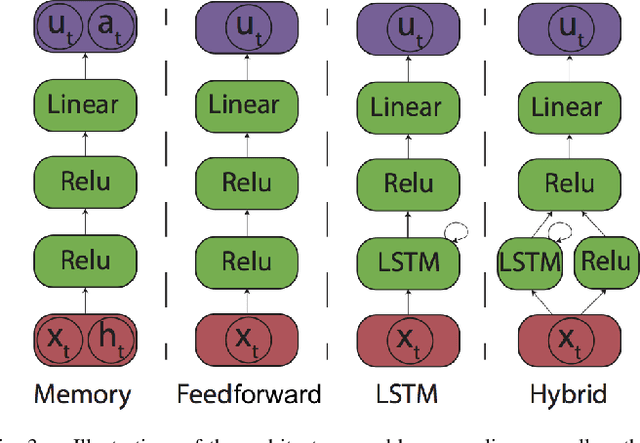
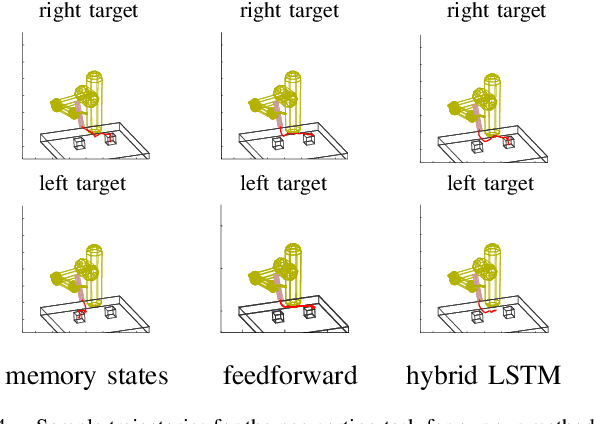
Policy learning for partially observed control tasks requires policies that can remember salient information from past observations. In this paper, we present a method for learning policies with internal memory for high-dimensional, continuous systems, such as robotic manipulators. Our approach consists of augmenting the state and action space of the system with continuous-valued memory states that the policy can read from and write to. Learning general-purpose policies with this type of memory representation directly is difficult, because the policy must automatically figure out the most salient information to memorize at each time step. We show that, by decomposing this policy search problem into a trajectory optimization phase and a supervised learning phase through a method called guided policy search, we can acquire policies with effective memorization and recall strategies. Intuitively, the trajectory optimization phase chooses the values of the memory states that will make it easier for the policy to produce the right action in future states, while the supervised learning phase encourages the policy to use memorization actions to produce those memory states. We evaluate our method on tasks involving continuous control in manipulation and navigation settings, and show that our method can learn complex policies that successfully complete a range of tasks that require memory.