 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Scale Up Kernel Methods to Be As Good As Deep Neural Nets
Paper and Code
Jun 17, 2015
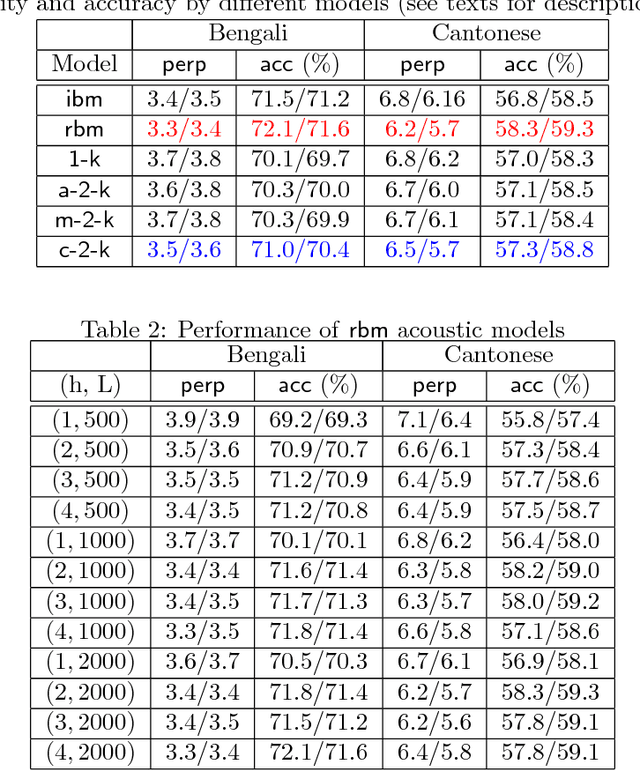
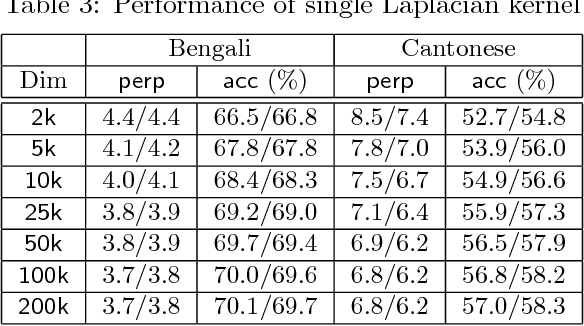
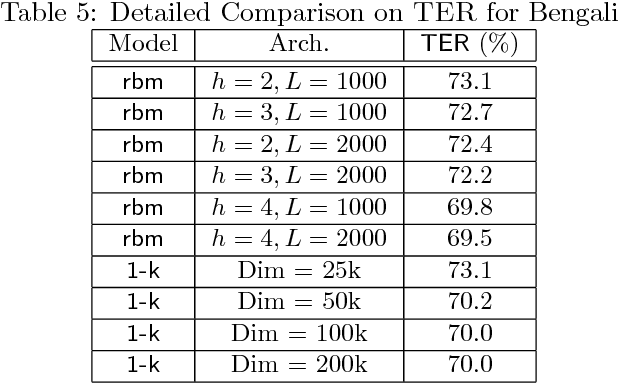
The computational complexity of kernel methods has often been a major barrier for applying them to large-scale learning problems. We argue that this barrier can be effectively overcome. In particular, we develop methods to scale up kernel models to successfully tackle large-scale learning problems that are so far only approachable by deep learning architectures. Based on the seminal work by Rahimi and Recht on approximating kernel functions with features derived from random projections, we advance the state-of-the-art by proposing methods that can efficiently train models with hundreds of millions of parameters, and learn optimal representations from multiple kernels. We conduct extensive empirical studies on problems from image recognition and automatic speech recognition, and show that the performance of our kernel models matches that of well-engineered deep neural nets (DNNs). To the best of our knowledge, this is the first time that a direct comparison between these two methods on large-scale problems is reported. Our kernel methods have several appealing properties: training with convex optimization, cost for training a single model comparable to DNNs, and significantly reduced total cost due to fewer hyperparameters to tune for model selection. Our contrastive study between these two very different but equally competitive models sheds light on fundamental questions such as how to learn good representations.