 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Construction and Natural-Language Description of Nonparametric Regression Models
Apr 24, 2014
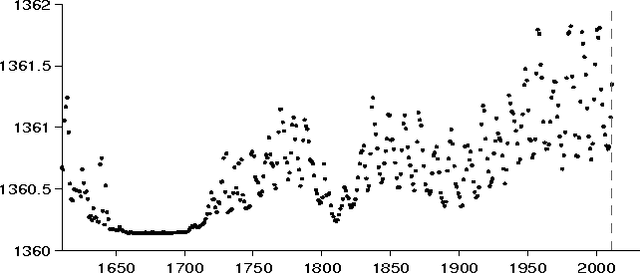

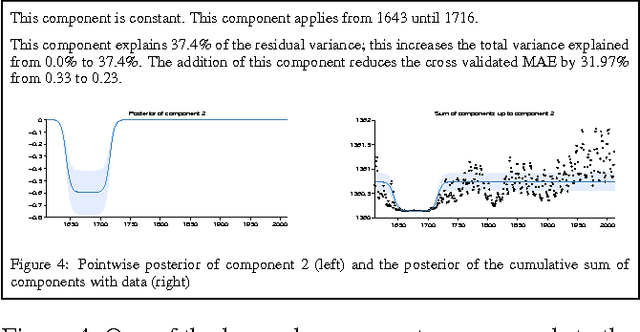
This paper presents the beginnings of an automatic statistician, focusing on regression problems. Our system explores an open-ended space of statistical models to discover a good explanation of a data set, and then produces a detailed report with figures and natural-language text. Our approach treats unknown regression functions nonparametrically using Gaussian processes, which has two important consequences. First, Gaussian processes can model functions in terms of high-level properties (e.g. smoothness, trends, periodicity, changepoints). Taken together with the compositional structure of our language of models this allows us to automatically describe functions in simple terms. Second, the use of flexible nonparametric models and a rich language for composing them in an open-ended manner also results in state-of-the-art extrapolation performance evaluated over 13 real time series data sets from various domains.
A reversible infinite HMM using normalised random measures
Mar 17, 2014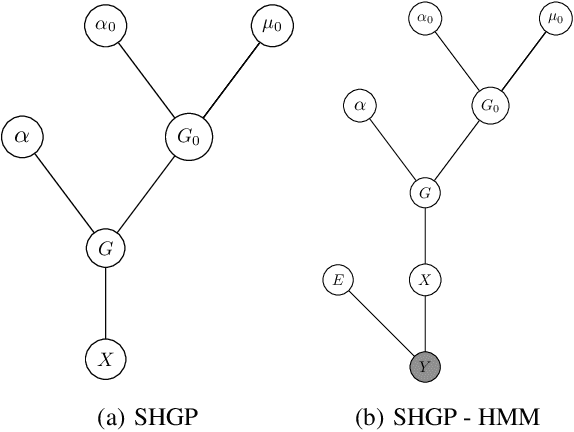
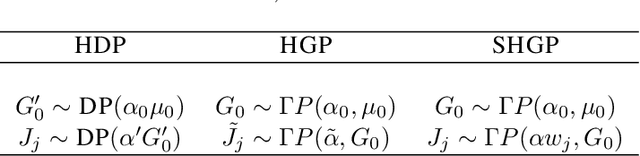
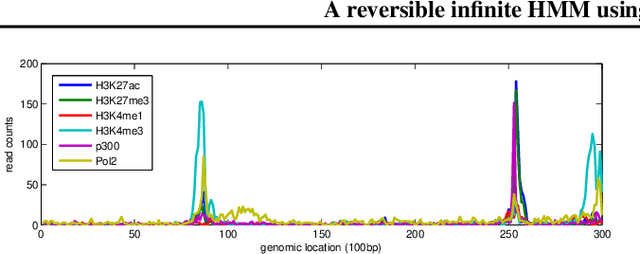

We present a nonparametric prior over reversible Markov chains. We use completely random measures, specifically gamma processes, to construct a countably infinite graph with weighted edges. By enforcing symmetry to make the edges undirected we define a prior over random walks on graphs that results in a reversible Markov chain. The resulting prior over infinite transition matrices is closely related to the hierarchical Dirichlet process but enforces reversibility. A reinforcement scheme has recently been proposed with similar properties, but the de Finetti measure is not well characterised. We take the alternative approach of explicitly constructing the mixing measure, which allows more straightforward and efficient inference at the cost of no longer having a closed form predictive distribution. We use our process to construct a reversible infinite HMM which we apply to two real datasets, one from epigenomics and one ion channel recording.
Student-t Processes as Alternatives to Gaussian Processes
Feb 19, 2014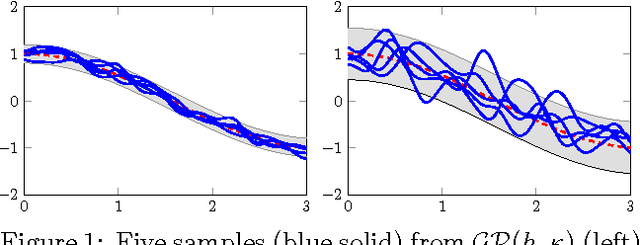

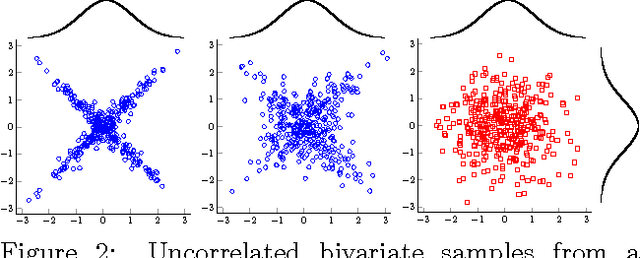
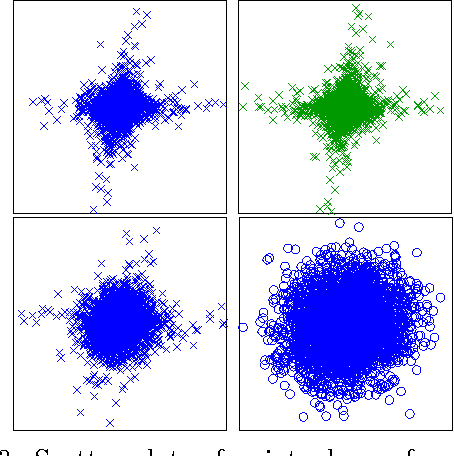
We investigate the Student-t process as an alternative to the Gaussian process as a nonparametric prior over functions. We derive closed form expressions for the marginal likelihood and predictive distribution of a Student-t process, by integrating away an inverse Wishart process prior over the covariance kernel of a Gaussian process model. We show surprising equivalences between different hierarchical Gaussian process models leading to Student-t processes, and derive a new sampling scheme for the inverse Wishart process, which helps elucidate these equivalences. Overall, we show that a Student-t process can retain the attractive properties of a Gaussian process -- a nonparametric representation, analytic marginal and predictive distributions, and easy model selection through covariance kernels -- but has enhanced flexibility, and predictive covariances that, unlike a Gaussian process, explicitly depend on the values of training observations. We verify empirically that a Student-t process is especially useful in situations where there are changes in covariance structure, or in applications like Bayesian optimization, where accurate predictive covariances are critical for good performance. These advantages come at no additional computational cost over Gaussian processes.
The Random Forest Kernel and other kernels for big data from random partitions
Feb 18, 2014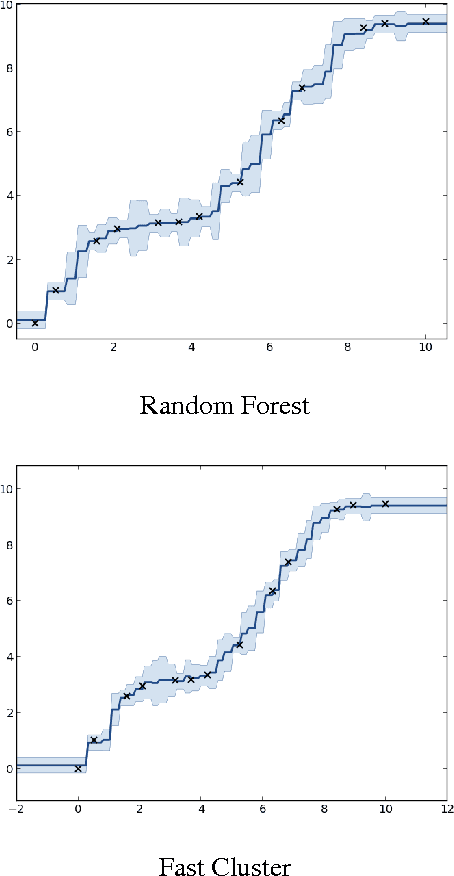
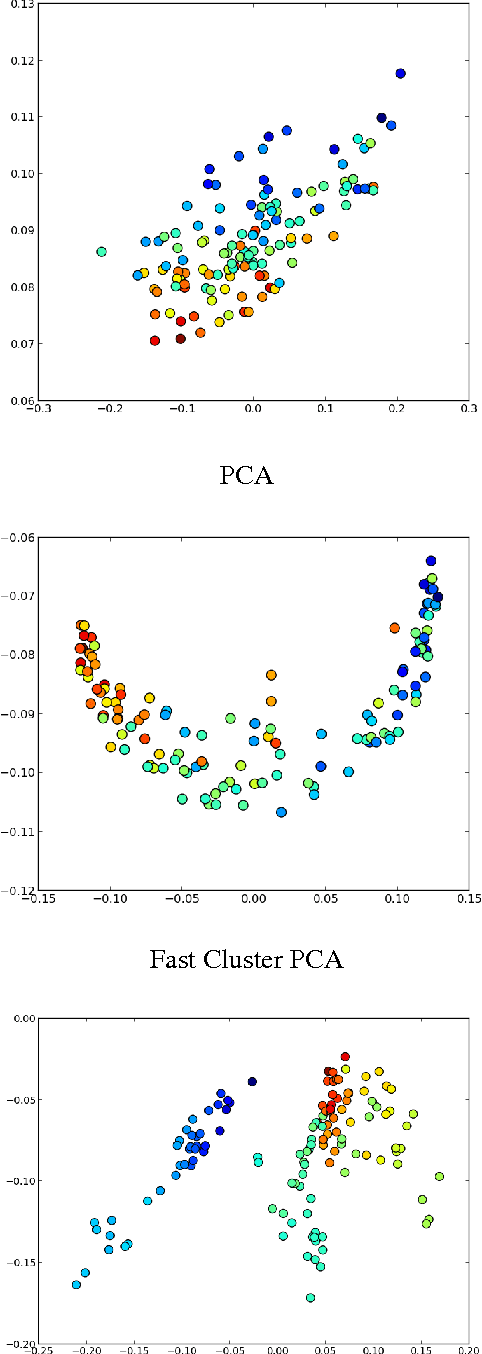
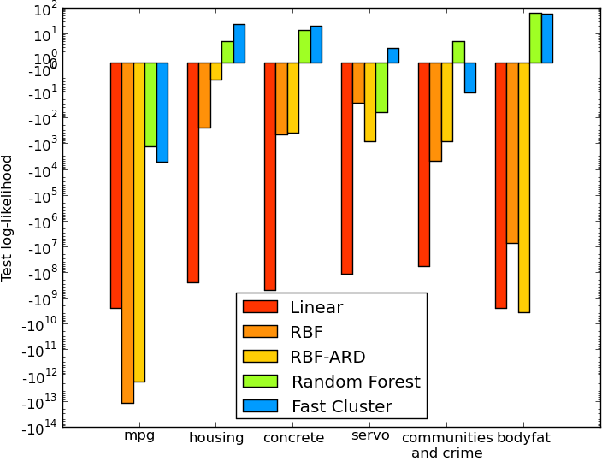
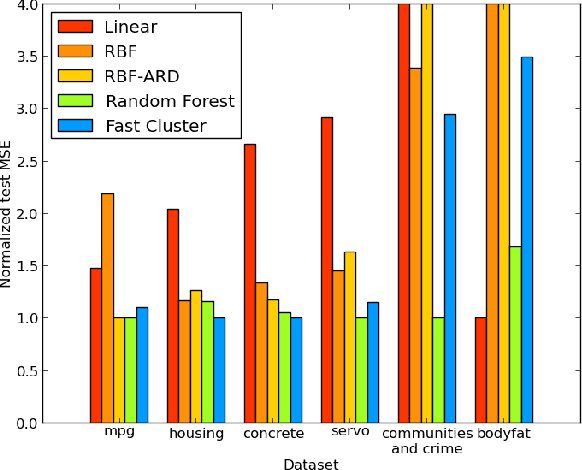
We present Random Partition Kernels, a new class of kernels derived by demonstrating a natural connection between random partitions of objects and kernels between those objects. We show how the construction can be used to create kernels from methods that would not normally be viewed as random partitions, such as Random Forest. To demonstrate the potential of this method, we propose two new kernels, the Random Forest Kernel and the Fast Cluster Kernel, and show that these kernels consistently outperform standard kernels on problems involving real-world datasets. Finally, we show how the form of these kernels lend themselves to a natural approximation that is appropriate for certain big data problems, allowing $O(N)$ inference in methods such as Gaussian Processes, Support Vector Machines and Kernel PCA.
Gaussian Process Volatility Model
Feb 13, 2014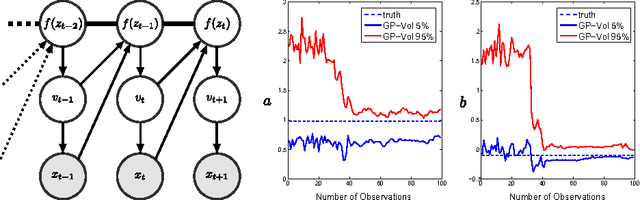
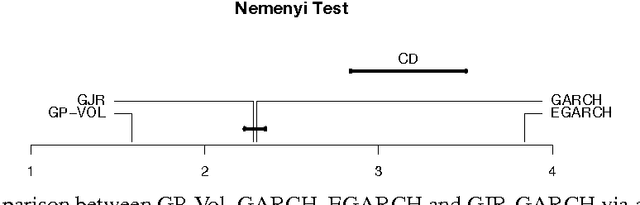
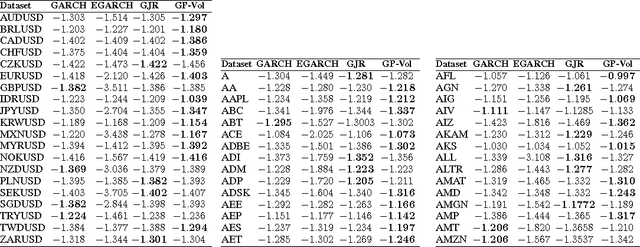
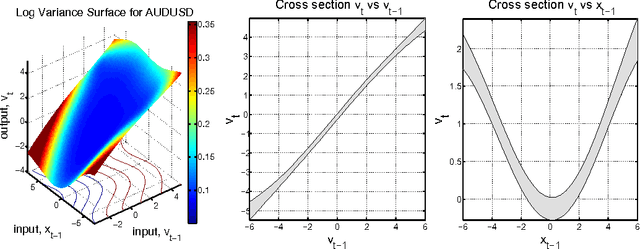
The accurate prediction of time-changing variances is an important task in the modeling of financial data. Standard econometric models are often limited as they assume rigid functional relationships for the variances. Moreover, function parameters are usually learned using maximum likelihood, which can lead to overfitting. To address these problems we introduce a novel model for time-changing variances using Gaussian Processes. A Gaussian Process (GP) defines a distribution over functions, which allows us to capture highly flexible functional relationships for the variances. In addition, we develop an online algorithm to perform inference. The algorithm has two main advantages. First, it takes a Bayesian approach, thereby avoiding overfitting. Second, it is much quicker than current offline inference procedures. Finally, our new model was evaluated on financial data and showed significant improvement in predictive performance over current standard models.
A dependent partition-valued process for multitask clustering and time evolving network modelling
Oct 31, 2013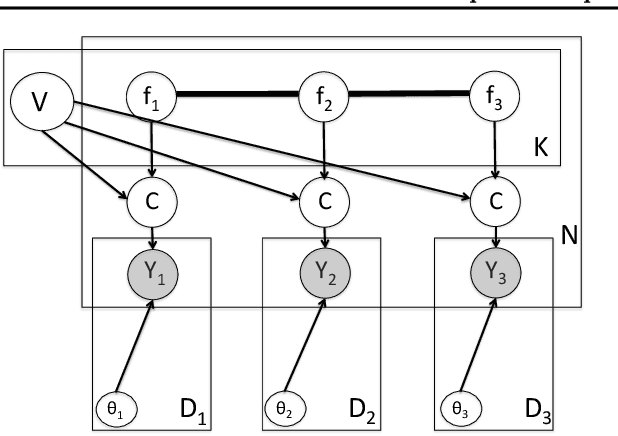
The fundamental aim of clustering algorithms is to partition data points. We consider tasks where the discovered partition is allowed to vary with some covariate such as space or time. One approach would be to use fragmentation-coagulation processes, but these, being Markov processes, are restricted to linear or tree structured covariate spaces. We define a partition-valued process on an arbitrary covariate space using Gaussian processes. We use the process to construct a multitask clustering model which partitions datapoints in a similar way across multiple data sources, and a time series model of network data which allows cluster assignments to vary over time. We describe sampling algorithms for inference and apply our method to defining cancer subtypes based on different types of cellular characteristics, finding regulatory modules from gene expression data from multiple human populations, and discovering time varying community structure in a social network.
Determinantal Clustering Processes - A Nonparametric Bayesian Approach to Kernel Based Semi-Supervised Clustering
Sep 26, 2013
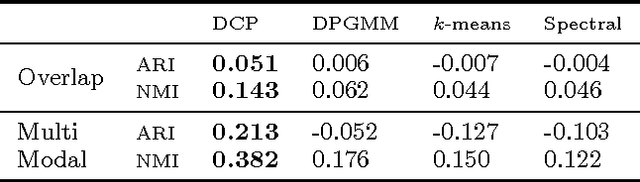
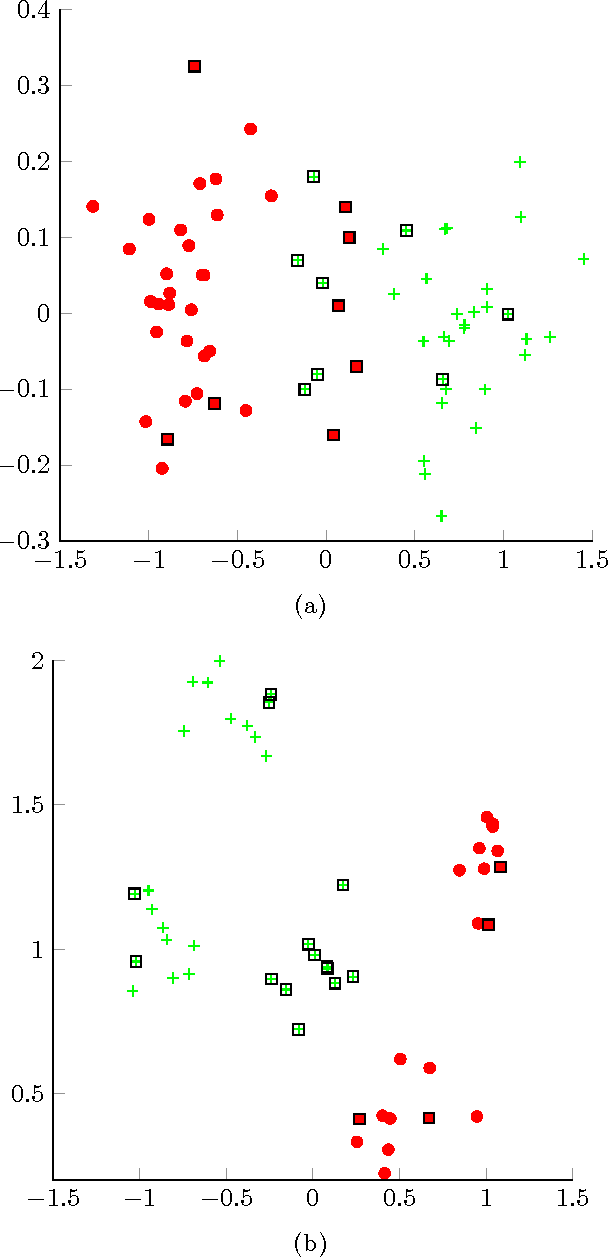
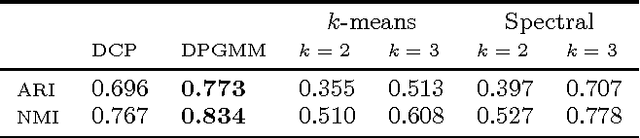
Semi-supervised clustering is the task of clustering data points into clusters where only a fraction of the points are labelled. The true number of clusters in the data is often unknown and most models require this parameter as an input. Dirichlet process mixture models are appealing as they can infer the number of clusters from the data. However, these models do not deal with high dimensional data well and can encounter difficulties in inference. We present a novel nonparameteric Bayesian kernel based method to cluster data points without the need to prespecify the number of clusters or to model complicated densities from which data points are assumed to be generated from. The key insight is to use determinants of submatrices of a kernel matrix as a measure of how close together a set of points are. We explore some theoretical properties of the model and derive a natural Gibbs based algorithm with MCMC hyperparameter learning. The model is implemented on a variety of synthetic and real world data sets.
The Supervised IBP: Neighbourhood Preserving Infinite Latent Feature Models
Sep 26, 2013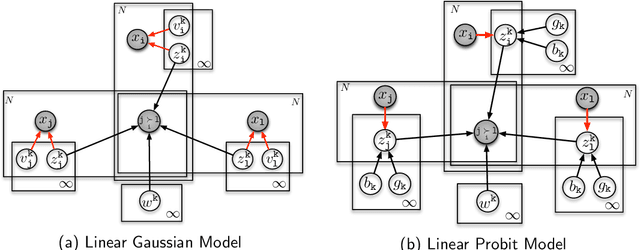
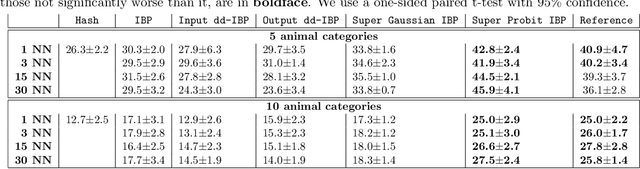
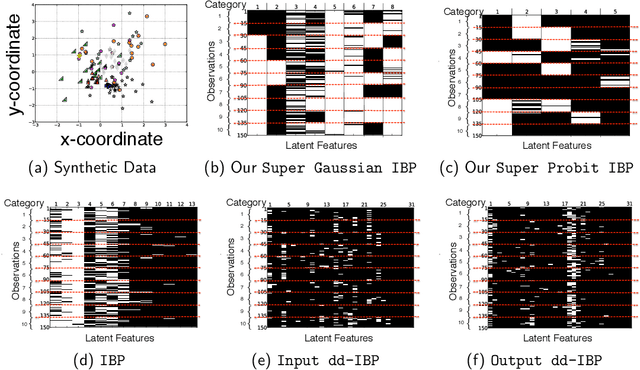
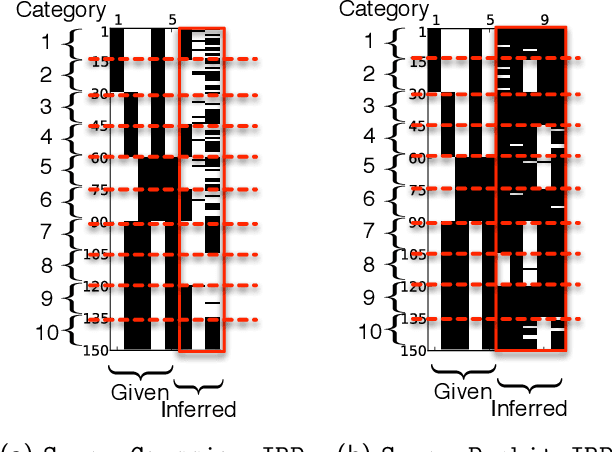
We propose a probabilistic model to infer supervised latent variables in the Hamming space from observed data. Our model allows simultaneous inference of the number of binary latent variables, and their values. The latent variables preserve neighbourhood structure of the data in a sense that objects in the same semantic concept have similar latent values, and objects in different concepts have dissimilar latent values. We formulate the supervised infinite latent variable problem based on an intuitive principle of pulling objects together if they are of the same type, and pushing them apart if they are not. We then combine this principle with a flexible Indian Buffet Process prior on the latent variables. We show that the inferred supervised latent variables can be directly used to perform a nearest neighbour search for the purpose of retrieval. We introduce a new application of dynamically extending hash codes, and show how to effectively couple the structure of the hash codes with continuously growing structure of the neighbourhood preserving infinite latent feature space.
Ranking relations using analogies in biological and information networks
Aug 29, 2013
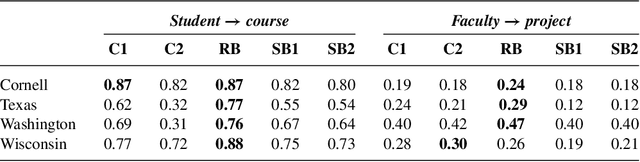

Analogical reasoning depends fundamentally on the ability to learn and generalize about relations between objects. We develop an approach to relational learning which, given a set of pairs of objects $\mathbf{S}=\{A^{(1)}:B^{(1)},A^{(2)}:B^{(2)},\ldots,A^{(N)}:B ^{(N)}\}$, measures how well other pairs A:B fit in with the set $\mathbf{S}$. Our work addresses the following question: is the relation between objects A and B analogous to those relations found in $\mathbf{S}$? Such questions are particularly relevant in information retrieval, where an investigator might want to search for analogous pairs of objects that match the query set of interest. There are many ways in which objects can be related, making the task of measuring analogies very challenging. Our approach combines a similarity measure on function spaces with Bayesian analysis to produce a ranking. It requires data containing features of the objects of interest and a link matrix specifying which relationships exist; no further attributes of such relationships are necessary. We illustrate the potential of our method on text analysis and information networks. An application on discovering functional interactions between pairs of proteins is discussed in detail, where we show that our approach can work in practice even if a small set of protein pairs is provided.
* Published in at http://dx.doi.org/10.1214/09-AOAS321 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Scaling the Indian Buffet Process via Submodular Maximization
Jul 24, 2013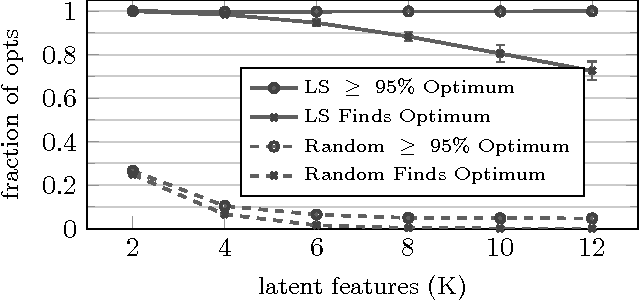
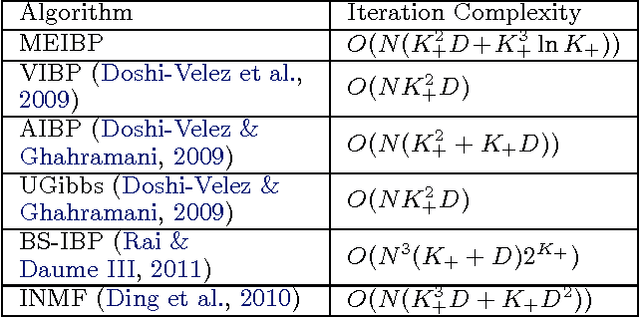
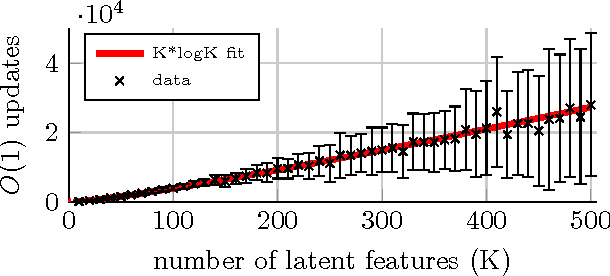
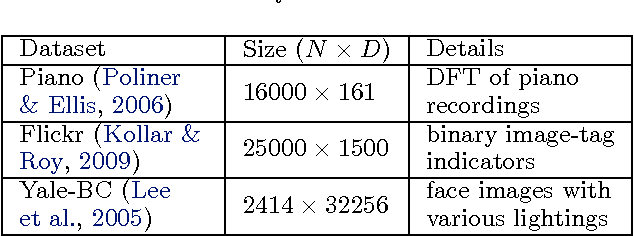
Inference for latent feature models is inherently difficult as the inference space grows exponentially with the size of the input data and number of latent features. In this work, we use Kurihara & Welling (2008)'s maximization-expectation framework to perform approximate MAP inference for linear-Gaussian latent feature models with an Indian Buffet Process (IBP) prior. This formulation yields a submodular function of the features that corresponds to a lower bound on the model evidence. By adding a constant to this function, we obtain a nonnegative submodular function that can be maximized via a greedy algorithm that obtains at least a one-third approximation to the optimal solution. Our inference method scales linearly with the size of the input data, and we show the efficacy of our method on the largest datasets currently analyzed using an IBP model.
* 13 pages, 8 figures