 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Convolutional Neural Networks with Bernoulli Approximate Variational Inference
Jan 18, 2016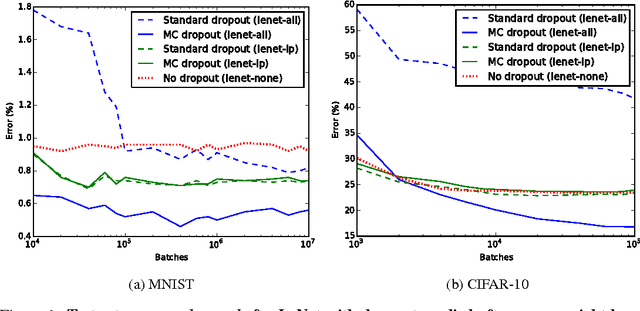
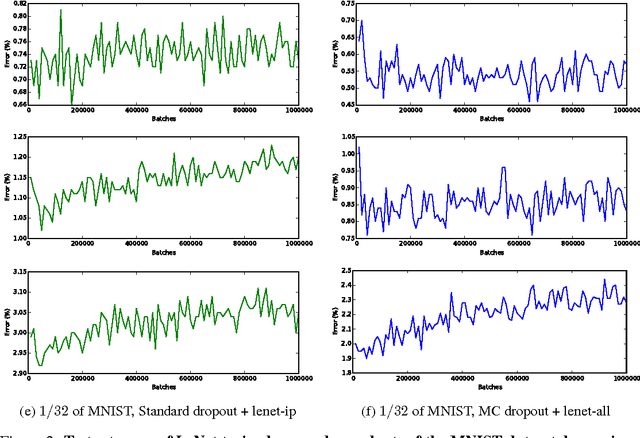
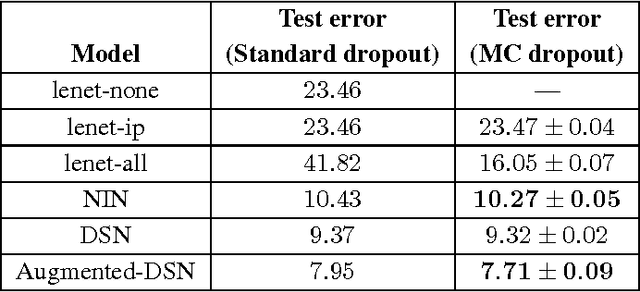
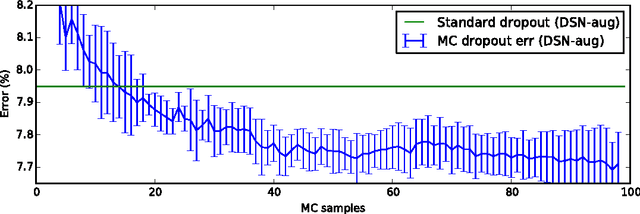
Convolutional neural networks (CNNs) work well on large datasets. But labelled data is hard to collect, and in some applications larger amounts of data are not available. The problem then is how to use CNNs with small data -- as CNNs overfit quickly. We present an efficient Bayesian CNN, offering better robustness to over-fitting on small data than traditional approaches. This is by placing a probability distribution over the CNN's kernels. We approximate our model's intractable posterior with Bernoulli variational distributions, requiring no additional model parameters. On the theoretical side, we cast dropout network training as approximate inference in Bayesian neural networks. This allows us to implement our model using existing tools in deep learning with no increase in time complexity, while highlighting a negative result in the field. We show a considerable improvement in classification accuracy compared to standard techniques and improve on published state-of-the-art results for CIFAR-10.
On Sparse variational methods and the Kullback-Leibler divergence between stochastic processes
Dec 04, 2015The variational framework for learning inducing variables (Titsias, 2009a) has had a large impact on the Gaussian process literature. The framework may be interpreted as minimizing a rigorously defined Kullback-Leibler divergence between the approximating and posterior processes. To our knowledge this connection has thus far gone unremarked in the literature. In this paper we give a substantial generalization of the literature on this topic. We give a new proof of the result for infinite index sets which allows inducing points that are not data points and likelihoods that depend on all function values. We then discuss augmented index sets and show that, contrary to previous works, marginal consistency of augmentation is not enough to guarantee consistency of variational inference with the original model. We then characterize an extra condition where such a guarantee is obtainable. Finally we show how our framework sheds light on interdomain sparse approximations and sparse approximations for Cox processes.
Parallel Predictive Entropy Search for Batch Global Optimization of Expensive Objective Functions
Nov 23, 2015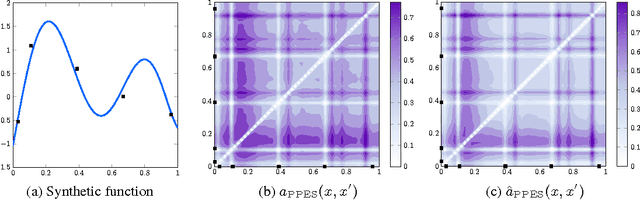
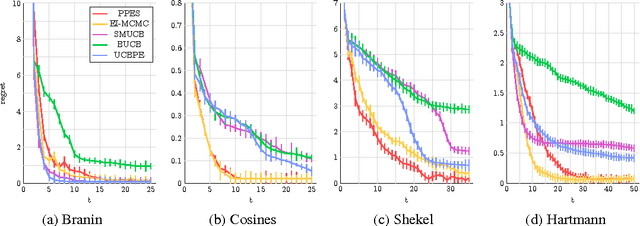
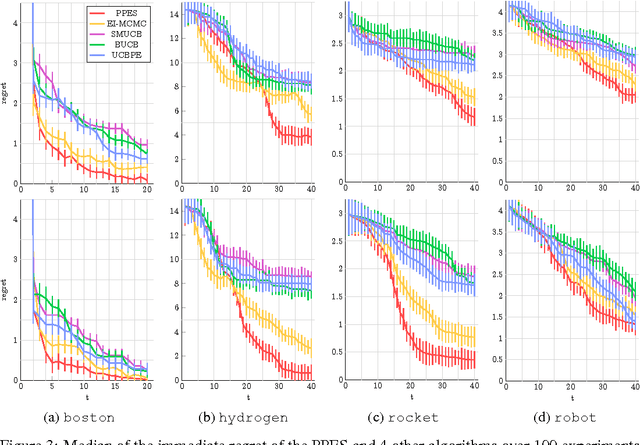
We develop parallel predictive entropy search (PPES), a novel algorithm for Bayesian optimization of expensive black-box objective functions. At each iteration, PPES aims to select a batch of points which will maximize the information gain about the global maximizer of the objective. Well known strategies exist for suggesting a single evaluation point based on previous observations, while far fewer are known for selecting batches of points to evaluate in parallel. The few batch selection schemes that have been studied all resort to greedy methods to compute an optimal batch. To the best of our knowledge, PPES is the first non-greedy batch Bayesian optimization strategy. We demonstrate the benefit of this approach in optimization performance on both synthetic and real world applications, including problems in machine learning, rocket science and robotics.
Neural Adaptive Sequential Monte Carlo
Nov 16, 2015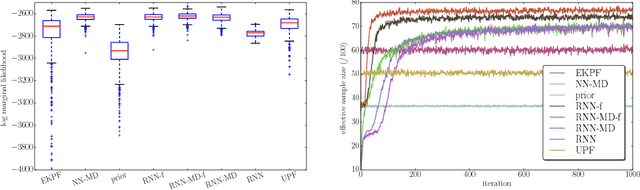
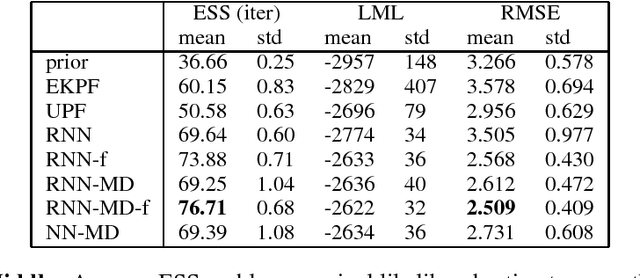
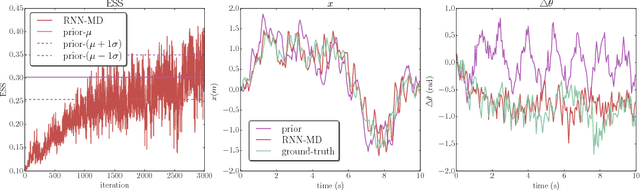

Sequential Monte Carlo (SMC), or particle filtering, is a popular class of methods for sampling from an intractable target distribution using a sequence of simpler intermediate distributions. Like other importance sampling-based methods, performance is critically dependent on the proposal distribution: a bad proposal can lead to arbitrarily inaccurate estimates of the target distribution. This paper presents a new method for automatically adapting the proposal using an approximation of the Kullback-Leibler divergence between the true posterior and the proposal distribution. The method is very flexible, applicable to any parameterized proposal distribution and it supports online and batch variants. We use the new framework to adapt powerful proposal distributions with rich parameterizations based upon neural networks leading to Neural Adaptive Sequential Monte Carlo (NASMC). Experiments indicate that NASMC significantly improves inference in a non-linear state space model outperforming adaptive proposal methods including the Extended Kalman and Unscented Particle Filters. Experiments also indicate that improved inference translates into improved parameter learning when NASMC is used as a subroutine of Particle Marginal Metropolis Hastings. Finally we show that NASMC is able to train a latent variable recurrent neural network (LV-RNN) achieving results that compete with the state-of-the-art for polymorphic music modelling. NASMC can be seen as bridging the gap between adaptive SMC methods and the recent work in scalable, black-box variational inference.
Sandwiching the marginal likelihood using bidirectional Monte Carlo
Nov 08, 2015

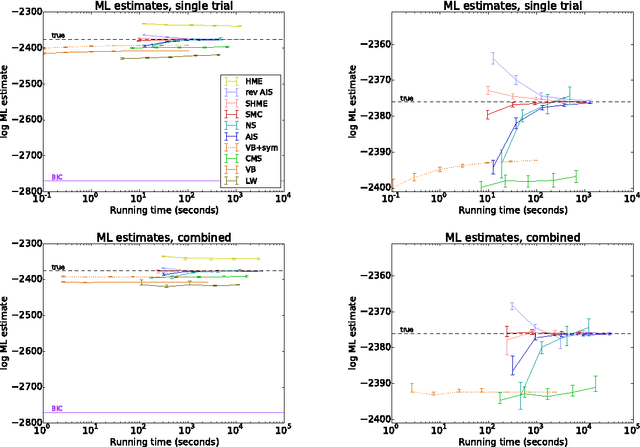
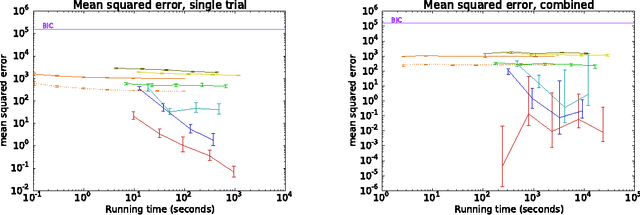
Computing the marginal likelihood (ML) of a model requires marginalizing out all of the parameters and latent variables, a difficult high-dimensional summation or integration problem. To make matters worse, it is often hard to measure the accuracy of one's ML estimates. We present bidirectional Monte Carlo, a technique for obtaining accurate log-ML estimates on data simulated from a model. This method obtains stochastic lower bounds on the log-ML using annealed importance sampling or sequential Monte Carlo, and obtains stochastic upper bounds by running these same algorithms in reverse starting from an exact posterior sample. The true value can be sandwiched between these two stochastic bounds with high probability. Using the ground truth log-ML estimates obtained from our method, we quantitatively evaluate a wide variety of existing ML estimators on several latent variable models: clustering, a low rank approximation, and a binary attributes model. These experiments yield insights into how to accurately estimate marginal likelihoods.
Dirichlet Fragmentation Processes
Sep 16, 2015
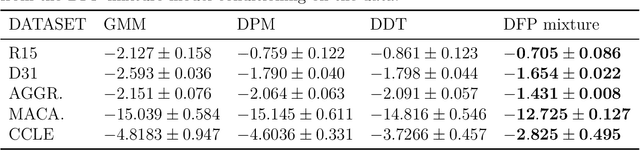
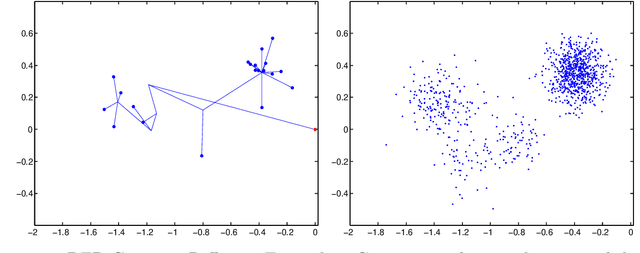
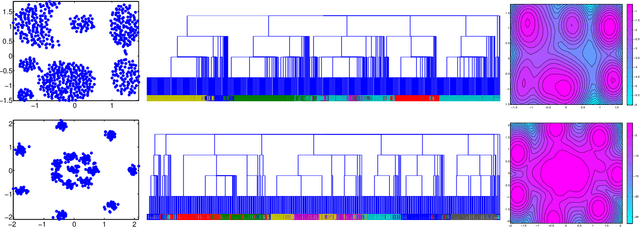
Tree structures are ubiquitous in data across many domains, and many datasets are naturally modelled by unobserved tree structures. In this paper, first we review the theory of random fragmentation processes [Bertoin, 2006], and a number of existing methods for modelling trees, including the popular nested Chinese restaurant process (nCRP). Then we define a general class of probability distributions over trees: the Dirichlet fragmentation process (DFP) through a novel combination of the theory of Dirichlet processes and random fragmentation processes. This DFP presents a stick-breaking construction, and relates to the nCRP in the same way the Dirichlet process relates to the Chinese restaurant process. Furthermore, we develop a novel hierarchical mixture model with the DFP, and empirically compare the new model to similar models in machine learning. Experiments show the DFP mixture model to be convincingly better than existing state-of-the-art approaches for hierarchical clustering and density modelling.
Predictive Entropy Search for Bayesian Optimization with Unknown Constraints
Jul 15, 2015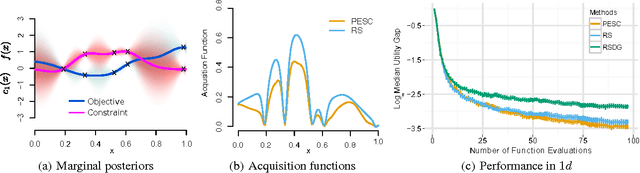
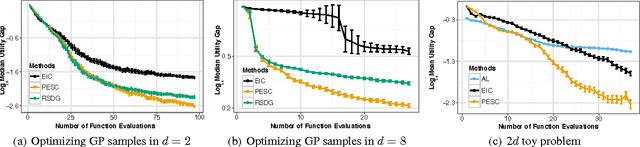
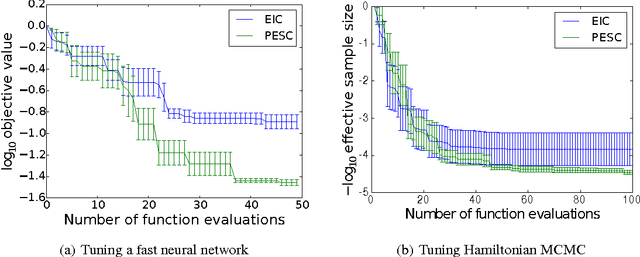
Unknown constraints arise in many types of expensive black-box optimization problems. Several methods have been proposed recently for performing Bayesian optimization with constraints, based on the expected improvement (EI) heuristic. However, EI can lead to pathologies when used with constraints. For example, in the case of decoupled constraints---i.e., when one can independently evaluate the objective or the constraints---EI can encounter a pathology that prevents exploration. Additionally, computing EI requires a current best solution, which may not exist if none of the data collected so far satisfy the constraints. By contrast, information-based approaches do not suffer from these failure modes. In this paper, we present a new information-based method called Predictive Entropy Search with Constraints (PESC). We analyze the performance of PESC and show that it compares favorably to EI-based approaches on synthetic and benchmark problems, as well as several real-world examples. We demonstrate that PESC is an effective algorithm that provides a promising direction towards a unified solution for constrained Bayesian optimization.
An Empirical Study of Stochastic Variational Algorithms for the Beta Bernoulli Process
Jun 26, 2015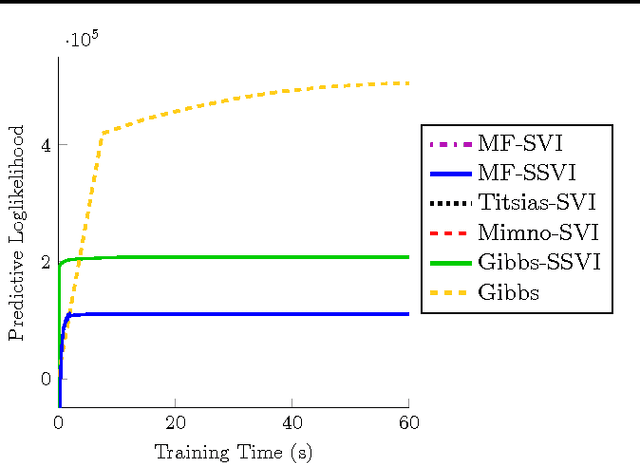
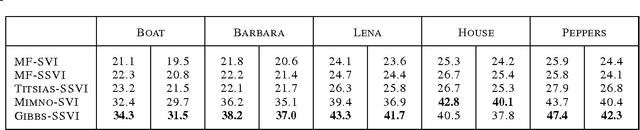
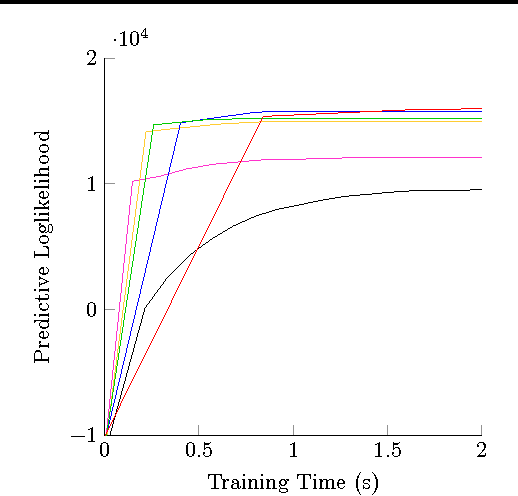
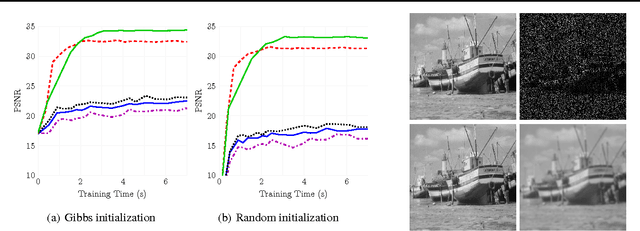
Stochastic variational inference (SVI) is emerging as the most promising candidate for scaling inference in Bayesian probabilistic models to large datasets. However, the performance of these methods has been assessed primarily in the context of Bayesian topic models, particularly latent Dirichlet allocation (LDA). Deriving several new algorithms, and using synthetic, image and genomic datasets, we investigate whether the understanding gleaned from LDA applies in the setting of sparse latent factor models, specifically beta process factor analysis (BPFA). We demonstrate that the big picture is consistent: using Gibbs sampling within SVI to maintain certain posterior dependencies is extremely effective. However, we find that different posterior dependencies are important in BPFA relative to LDA. Particularly, approximations able to model intra-local variable dependence perform best.
MCMC for Variationally Sparse Gaussian Processes
Jun 12, 2015
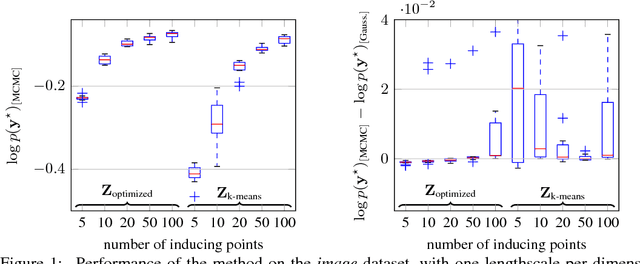
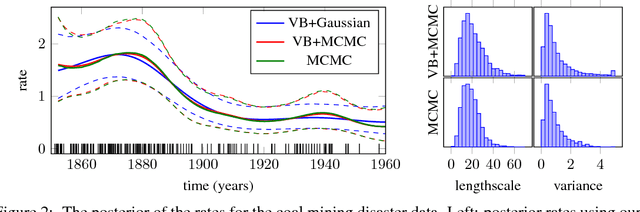
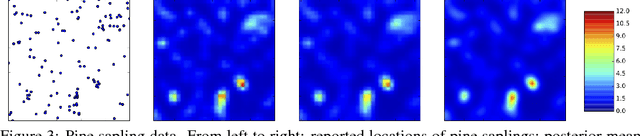
Gaussian process (GP) models form a core part of probabilistic machine learning. Considerable research effort has been made into attacking three issues with GP models: how to compute efficiently when the number of data is large; how to approximate the posterior when the likelihood is not Gaussian and how to estimate covariance function parameter posteriors. This paper simultaneously addresses these, using a variational approximation to the posterior which is sparse in support of the function but otherwise free-form. The result is a Hybrid Monte-Carlo sampling scheme which allows for a non-Gaussian approximation over the function values and covariance parameters simultaneously, with efficient computations based on inducing-point sparse GPs. Code to replicate each experiment in this paper will be available shortly.
A Linear-Time Particle Gibbs Sampler for Infinite Hidden Markov Models
Jun 09, 2015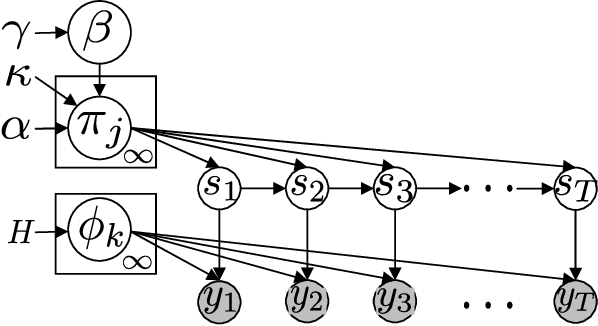
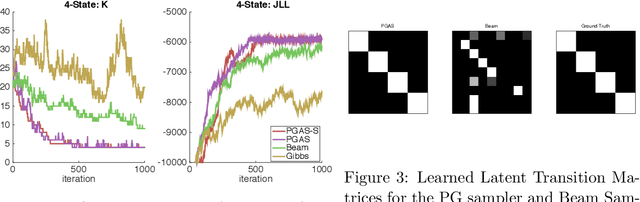
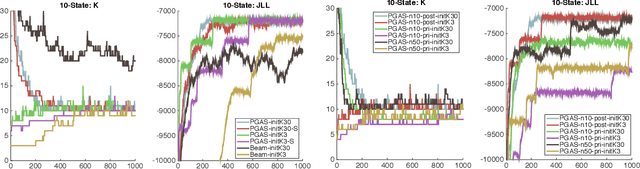
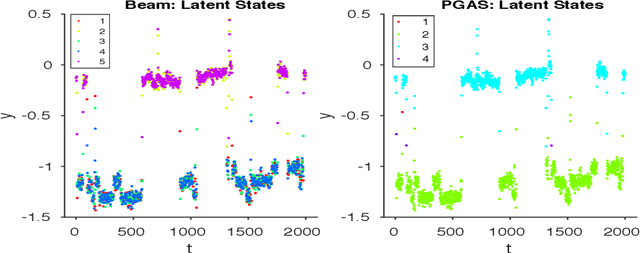
Infinite Hidden Markov Models (iHMM's) are an attractive, nonparametric generalization of the classical Hidden Markov Model which can automatically infer the number of hidden states in the system. However, due to the infinite-dimensional nature of transition dynamics performing inference in the iHMM is difficult. In this paper, we present an infinite-state Particle Gibbs (PG) algorithm to resample state trajectories for the iHMM. The proposed algorithm uses an efficient proposal optimized for iHMMs and leverages ancestor sampling to suppress degeneracy of the standard PG algorithm. Our algorithm demonstrates significant convergence improvements on synthetic and real world data sets. Additionally, the infinite-state PG algorithm has linear-time complexity in the number of states in the sampler, while competing methods scale quadratically.