 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralised Wishart Processes
Dec 31, 2010
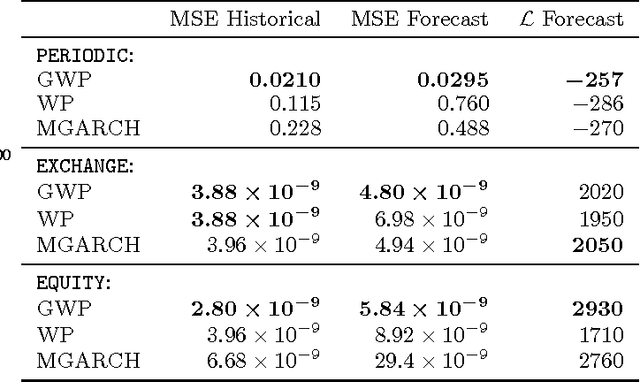
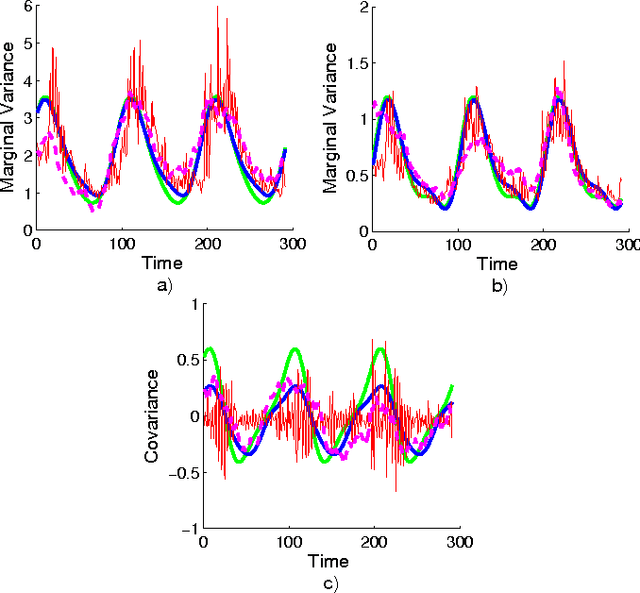
We introduce a stochastic process with Wishart marginals: the generalised Wishart process (GWP). It is a collection of positive semi-definite random matrices indexed by any arbitrary dependent variable. We use it to model dynamic (e.g. time varying) covariance matrices. Unlike existing models, it can capture a diverse class of covariance structures, it can easily handle missing data, the dependent variable can readily include covariates other than time, and it scales well with dimension; there is no need for free parameters, and optional parameters are easy to interpret. We describe how to construct the GWP, introduce general procedures for inference and predictions, and show that it outperforms its main competitor, multivariate GARCH, even on financial data that especially suits GARCH. We also show how to predict the mean of a multivariate process while accounting for dynamic correlations.
Learning the Structure of Deep Sparse Graphical Models
Aug 19, 2010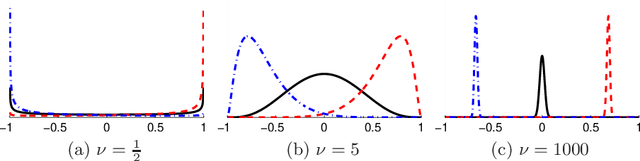
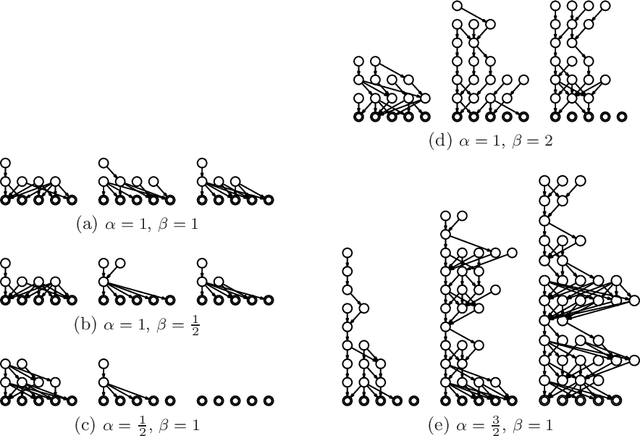
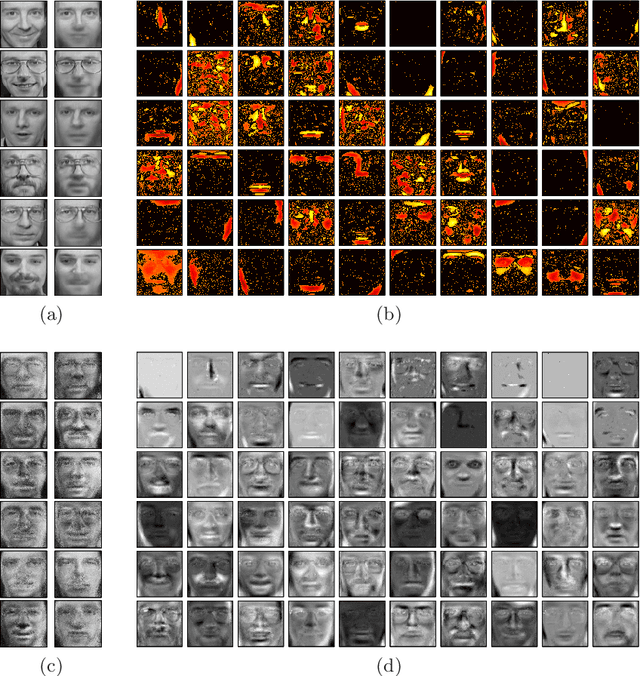
Deep belief networks are a powerful way to model complex probability distributions. However, learning the structure of a belief network, particularly one with hidden units, is difficult. The Indian buffet process has been used as a nonparametric Bayesian prior on the directed structure of a belief network with a single infinitely wide hidden layer. In this paper, we introduce the cascading Indian buffet process (CIBP), which provides a nonparametric prior on the structure of a layered, directed belief network that is unbounded in both depth and width, yet allows tractable inference. We use the CIBP prior with the nonlinear Gaussian belief network so each unit can additionally vary its behavior between discrete and continuous representations. We provide Markov chain Monte Carlo algorithms for inference in these belief networks and explore the structures learned on several image data sets.
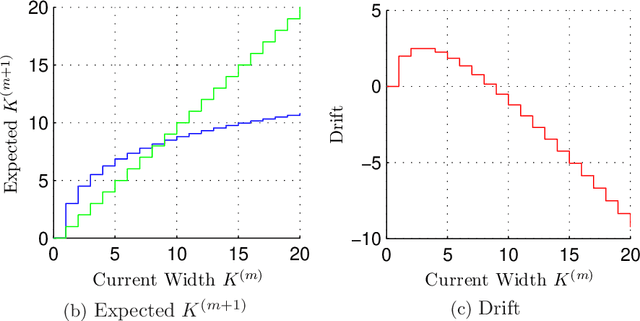
Copula Processes
Jun 09, 2010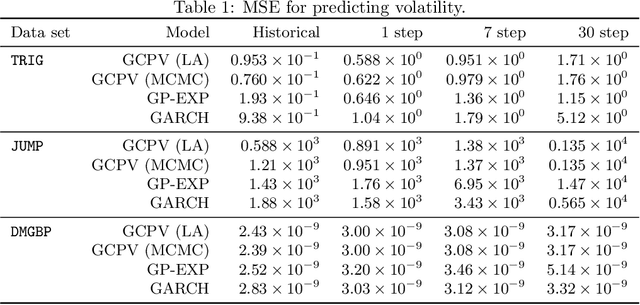
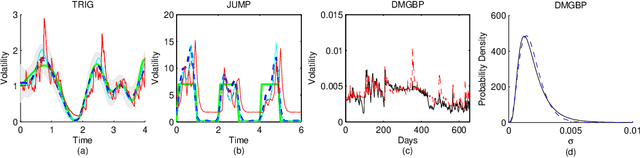
We define a copula process which describes the dependencies between arbitrarily many random variables independently of their marginal distributions. As an example, we develop a stochastic volatility model, Gaussian Copula Process Volatility (GCPV), to predict the latent standard deviations of a sequence of random variables. To make predictions we use Bayesian inference, with the Laplace approximation, and with Markov chain Monte Carlo as an alternative. We find both methods comparable. We also find our model can outperform GARCH on simulated and financial data. And unlike GARCH, GCPV can easily handle missing data, incorporate covariates other than time, and model a rich class of covariance structures.
Tree-Structured Stick Breaking Processes for Hierarchical Data
Jun 05, 2010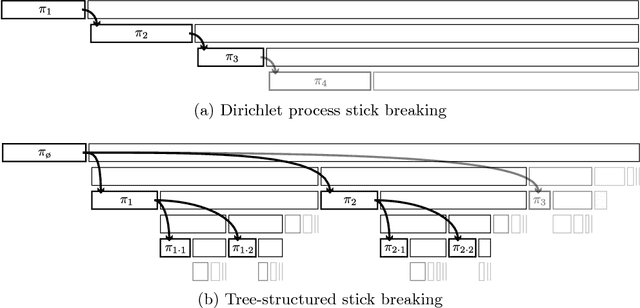
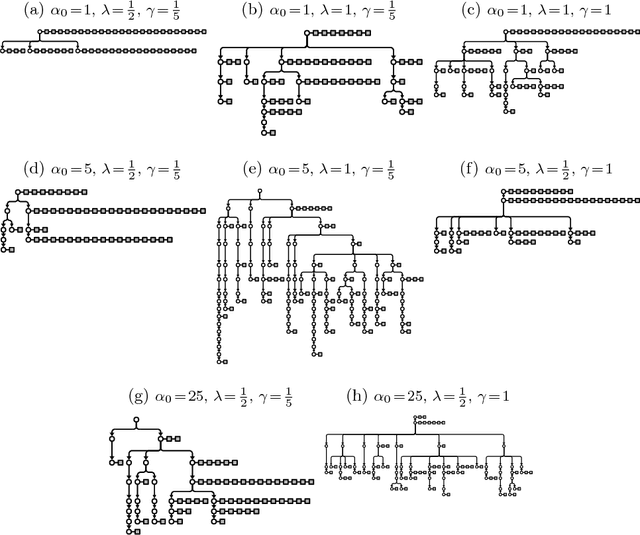
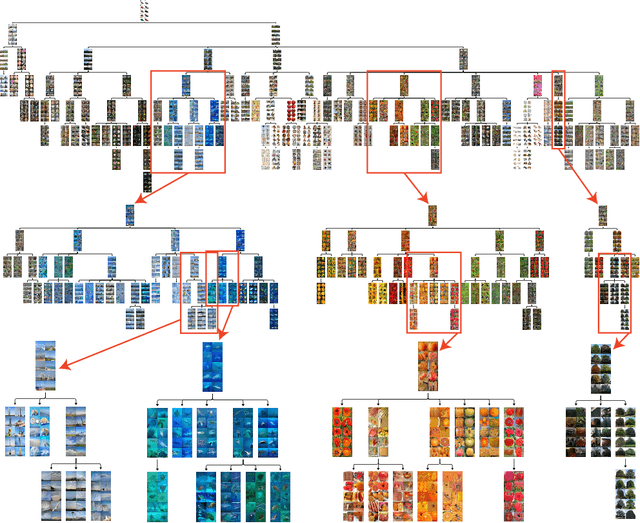
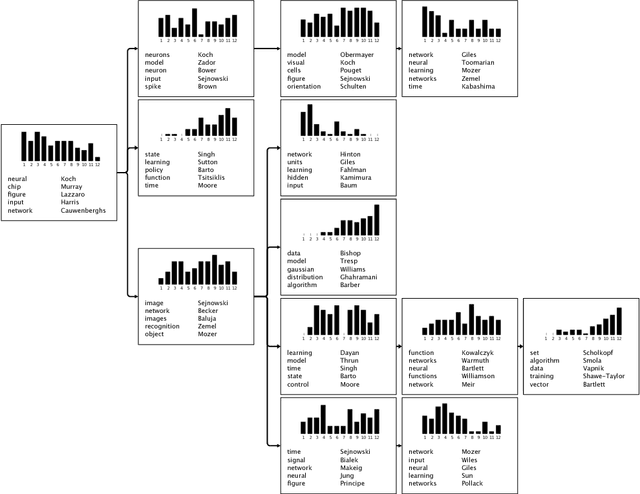
Many data are naturally modeled by an unobserved hierarchical structure. In this paper we propose a flexible nonparametric prior over unknown data hierarchies. The approach uses nested stick-breaking processes to allow for trees of unbounded width and depth, where data can live at any node and are infinitely exchangeable. One can view our model as providing infinite mixtures where the components have a dependency structure corresponding to an evolutionary diffusion down a tree. By using a stick-breaking approach, we can apply Markov chain Monte Carlo methods based on slice sampling to perform Bayesian inference and simulate from the posterior distribution on trees. We apply our method to hierarchical clustering of images and topic modeling of text data.
Kronecker Graphs: An Approach to Modeling Networks
Aug 21, 2009
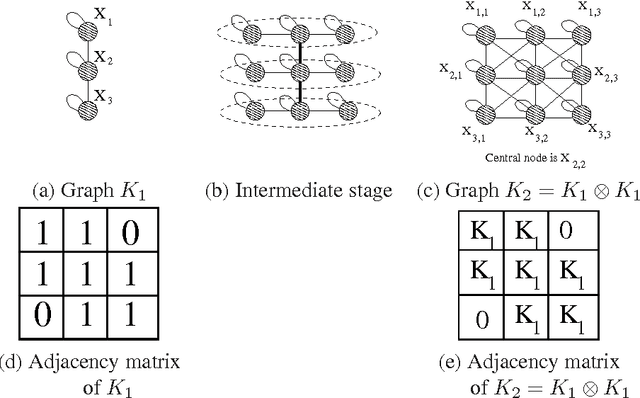
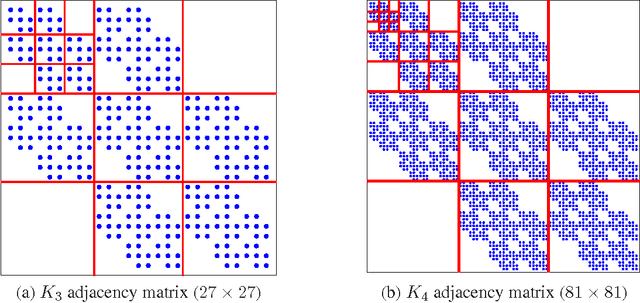
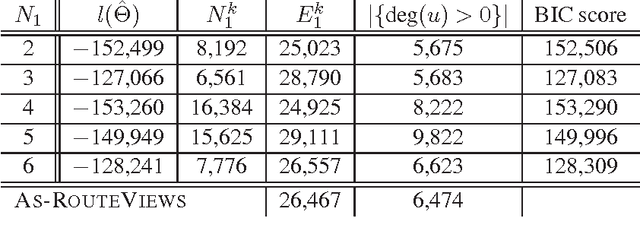
How can we model networks with a mathematically tractable model that allows for rigorous analysis of network properties? Networks exhibit a long list of surprising properties: heavy tails for the degree distribution; small diameters; and densification and shrinking diameters over time. Most present network models either fail to match several of the above properties, are complicated to analyze mathematically, or both. In this paper we propose a generative model for networks that is both mathematically tractable and can generate networks that have the above mentioned properties. Our main idea is to use the Kronecker product to generate graphs that we refer to as "Kronecker graphs". First, we prove that Kronecker graphs naturally obey common network properties. We also provide empirical evidence showing that Kronecker graphs can effectively model the structure of real networks. We then present KronFit, a fast and scalable algorithm for fitting the Kronecker graph generation model to large real networks. A naive approach to fitting would take super- exponential time. In contrast, KronFit takes linear time, by exploiting the structure of Kronecker matrix multiplication and by using statistical simulation techniques. Experiments on large real and synthetic networks show that KronFit finds accurate parameters that indeed very well mimic the properties of target networks. Once fitted, the model parameters can be used to gain insights about the network structure, and the resulting synthetic graphs can be used for null- models, anonymization, extrapolations, and graph summarization.
Bayesian two-sample tests
Jun 22, 2009In this paper, we present two classes of Bayesian approaches to the two-sample problem. Our first class of methods extends the Bayesian t-test to include all parametric models in the exponential family and their conjugate priors. Our second class of methods uses Dirichlet process mixtures (DPM) of such conjugate-exponential distributions as flexible nonparametric priors over the unknown distributions.