 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Robust Bias Reduction in Infinite Horizon Off-Policy Estimation
Oct 16, 2019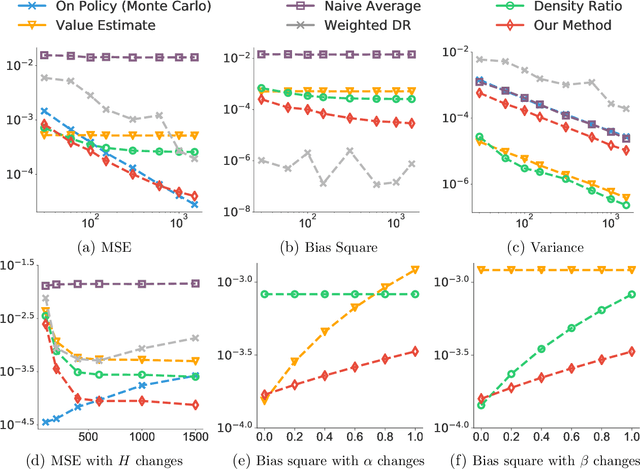
Infinite horizon off-policy policy evaluation is a highly challenging task due to the excessively large variance of typical importance sampling (IS) estimators. Recently, Liu et al. (2018a) proposed an approach that significantly reduces the variance of infinite-horizon off-policy evaluation by estimating the stationary density ratio, but at the cost of introducing potentially high biases due to the error in density ratio estimation. In this paper, we develop a bias-reduced augmentation of their method, which can take advantage of a learned value function to obtain higher accuracy. Our method is doubly robust in that the bias vanishes when either the density ratio or the value function estimation is perfect. In general, when either of them is accurate, the bias can also be reduced. Both theoretical and empirical results show that our method yields significant advantages over previous methods.
Multiple Learning for Regression in big data
Mar 03, 2019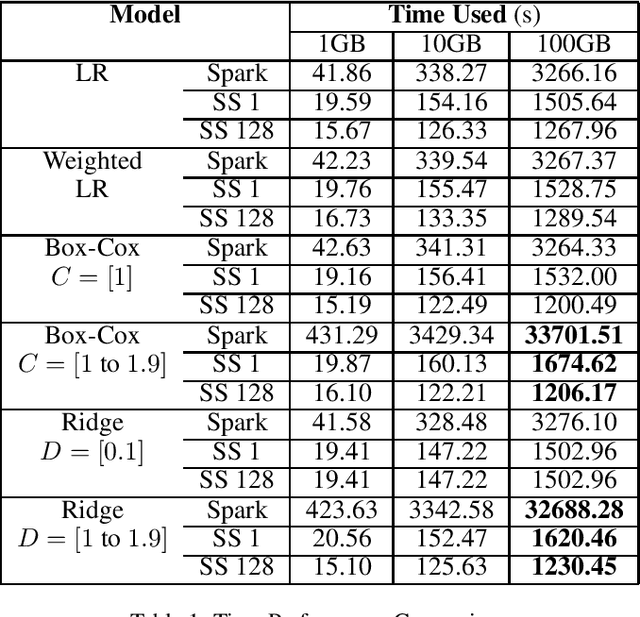
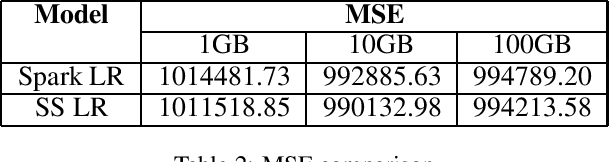
Regression problems that have closed-form solutions are well understood and can be easily implemented when the dataset is small enough to be all loaded into the RAM. Challenges arise when data is too big to be stored in RAM to compute the closed form solutions. Many techniques were proposed to overcome or alleviate the memory barrier problem but the solutions are often local optimal. In addition, most approaches require accessing the raw data again when updating the models. Parallel computing clusters are also expected if multiple models need to be computed simultaneously. We propose multiple learning approaches that utilize an array of sufficient statistics (SS) to address this big data challenge. This memory oblivious approach breaks the memory barrier when computing regressions with closed-form solutions, including but not limited to linear regression, weighted linear regression, linear regression with Box-Cox transformation (Box-Cox regression) and ridge regression models. The computation and update of the SS array can be handled at per row level or per mini-batch level. And updating a model is as easy as matrix addition and subtraction. Furthermore, multiple SS arrays for different models can be easily computed simultaneously to obtain multiple models at one pass through the dataset. We implemented our approaches on Spark and evaluated over the simulated datasets. Results showed our approaches can achieve closed-form solutions of multiple models at the cost of half training time of the traditional methods for a single model.
Breaking the Curse of Horizon: Infinite-Horizon Off-Policy Estimation
Oct 29, 2018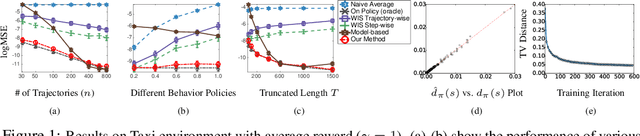
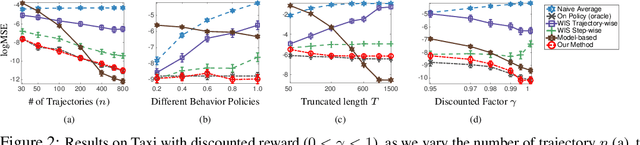
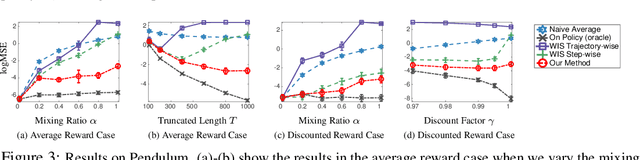

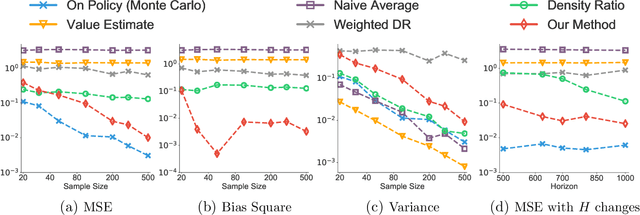
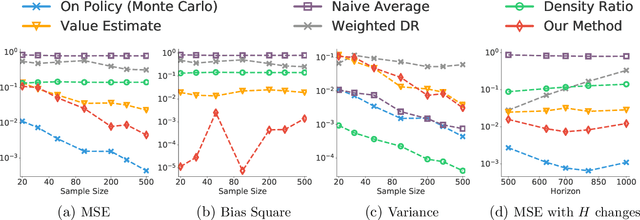
We consider the off-policy estimation problem of estimating the expected reward of a target policy using samples collected by a different behavior policy. Importance sampling (IS) has been a key technique to derive (nearly) unbiased estimators, but is known to suffer from an excessively high variance in long-horizon problems. In the extreme case of in infinite-horizon problems, the variance of an IS-based estimator may even be unbounded. In this paper, we propose a new off-policy estimation method that applies IS directly on the stationary state-visitation distributions to avoid the exploding variance issue faced by existing estimators.Our key contribution is a novel approach to estimating the density ratio of two stationary distributions, with trajectories sampled from only the behavior distribution. We develop a mini-max loss function for the estimation problem, and derive a closed-form solution for the case of RKHS. We support our method with both theoretical and empirical analyses.