 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Diffusion LLMs via Temporal-Spatial Parallel Decoding and Confidence Extrapolation
May 29, 2026Diffusion-based large language models (dLLMs) support parallel text generation via iterative denoising, yet inference remains latency-heavy because many steps are spent on redundant refinement and repeated remasking of tokens whose final values are already determined. Prior acceleration methods mainly depend on step-local confidence heuristics or fixed schedules, which are sensitive to prompt and task variation and ignore strong positional effects within a sequence. We cast diffusion decoding as a dynamic control problem and show that token-wise denoising trajectories provide the key signal for reliable control. We propose a trace-aware decoding framework with two components. First, Temporal-Spatial Parallel Decoding (TSPD) uses a lightweight temporalspatial controller that consumes per-token trajectory features, including confidence, entropy, and momentum, together with token position, to decide when a token has converged and can be safely fixed. Second, we introduce Confidence Extrapolation (CE), a training-free state-space module that forecasts future logit trends with uncertainty to support proactive decisions, including safe look-ahead and targeted stabilization when trajectories are oscillatory or underconfident. Together, TSPD and CE reduce unnecessary denoising iterations while preserving output quality, and they compose cleanly with system optimizations such as KV caching.
DiffSparse: Accelerating Diffusion Transformers with Learned Token Sparsity
Apr 04, 2026Diffusion models demonstrate outstanding performance in image generation, but their multi-step inference mechanism requires immense computational cost. Previous works accelerate inference by leveraging layer or token cache techniques to reduce computational cost. However, these methods fail to achieve superior acceleration performance in few-step diffusion transformer models due to inefficient feature caching strategies, manually designed sparsity allocation, and the practice of retaining complete forward computations in several steps in these token cache methods. To tackle these challenges, we propose a differentiable layer-wise sparsity optimization framework for diffusion transformer models, leveraging token caching to reduce token computation costs and enhance acceleration. Our method optimizes layer-wise sparsity allocation in an end-to-end manner through a learnable network combined with a dynamic programming solver. Additionally, our proposed two-stage training strategy eliminates the need for full-step processing in existing methods, further improving efficiency. We conducted extensive experiments on a range of diffusion-transformer models, including DiT-XL/2, PixArt-$α$, FLUX, and Wan2.1. Across these architectures, our method consistently improves efficiency without degrading sample quality. For example, on PixArt-$α$ with 20 sampling steps, we reduce computational cost by $54\%$ while achieving generation metrics that surpass those of the original model, substantially outperforming prior approaches. These results demonstrate that our method delivers large efficiency gains while often improving generation quality.
Learnable Permutation for Structured Sparsity on Transformer Models
Jan 30, 2026Structured sparsity has emerged as a popular model pruning technique, widely adopted in various architectures, including CNNs, Transformer models, and especially large language models (LLMs) in recent years. A promising direction to further improve post-pruning performance is weight permutation, which reorders model weights into patterns more amenable to pruning. However, the exponential growth of the permutation search space with the scale of Transformer architectures forces most methods to rely on greedy or heuristic algorithms, limiting the effectiveness of reordering. In this work, we propose a novel end-to-end learnable permutation framework. Our method introduces a learnable permutation cost matrix to quantify the cost of swapping any two input channels of a given weight matrix, a differentiable bipartite matching solver to obtain the optimal binary permutation matrix given a cost matrix, and a sparsity optimization loss function to directly optimize the permutation operator. We extensively validate our approach on vision and language Transformers, demonstrating that our method achieves state-of-the-art permutation results for structured sparsity.
DiffBench Meets DiffAgent: End-to-End LLM-Driven Diffusion Acceleration Code Generation
Jan 06, 2026Diffusion models have achieved remarkable success in image and video generation. However, their inherently multiple step inference process imposes substantial computational overhead, hindering real-world deployment. Accelerating diffusion models is therefore essential, yet determining how to combine multiple model acceleration techniques remains a significant challenge. To address this issue, we introduce a framework driven by large language models (LLMs) for automated acceleration code generation and evaluation. First, we present DiffBench, a comprehensive benchmark that implements a three stage automated evaluation pipeline across diverse diffusion architectures, optimization combinations and deployment scenarios. Second, we propose DiffAgent, an agent that generates optimal acceleration strategies and codes for arbitrary diffusion models. DiffAgent employs a closed-loop workflow in which a planning component and a debugging component iteratively refine the output of a code generation component, while a genetic algorithm extracts performance feedback from the execution environment to guide subsequent code refinements. We provide a detailed explanation of the DiffBench construction and the design principles underlying DiffAgent. Extensive experiments show that DiffBench offers a thorough evaluation of generated codes and that DiffAgent significantly outperforms existing LLMs in producing effective diffusion acceleration strategies.
Progressive Conditioned Scale-Shift Recalibration of Self-Attention for Online Test-time Adaptation
Dec 14, 2025



Online test-time adaptation aims to dynamically adjust a network model in real-time based on sequential input samples during the inference stage. In this work, we find that, when applying a transformer network model to a new target domain, the Query, Key, and Value features of its self-attention module often change significantly from those in the source domain, leading to substantial performance degradation of the transformer model. To address this important issue, we propose to develop a new approach to progressively recalibrate the self-attention at each layer using a local linear transform parameterized by conditioned scale and shift factors. We consider the online model adaptation from the source domain to the target domain as a progressive domain shift separation process. At each transformer network layer, we learn a Domain Separation Network to extract the domain shift feature, which is used to predict the scale and shift parameters for self-attention recalibration using a Factor Generator Network. These two lightweight networks are adapted online during inference. Experimental results on benchmark datasets demonstrate that the proposed progressive conditioned scale-shift recalibration (PCSR) method is able to significantly improve the online test-time domain adaptation performance by a large margin of up to 3.9\% in classification accuracy on the ImageNet-C dataset.
Open-World Test-Time Adaptation with Hierarchical Feature Aggregation and Attention Affine
Nov 16, 2025Test-time adaptation (TTA) refers to adjusting the model during the testing phase to cope with changes in sample distribution and enhance the model's adaptability to new environments. In real-world scenarios, models often encounter samples from unseen (out-of-distribution, OOD) categories. Misclassifying these as known (in-distribution, ID) classes not only degrades predictive accuracy but can also impair the adaptation process, leading to further errors on subsequent ID samples. Many existing TTA methods suffer substantial performance drops under such conditions. To address this challenge, we propose a Hierarchical Ladder Network that extracts OOD features from class tokens aggregated across all Transformer layers. OOD detection performance is enhanced by combining the original model prediction with the output of the Hierarchical Ladder Network (HLN) via weighted probability fusion. To improve robustness under domain shift, we further introduce an Attention Affine Network (AAN) that adaptively refines the self-attention mechanism conditioned on the token information to better adapt to domain drift, thereby improving the classification performance of the model on datasets with domain shift. Additionally, a weighted entropy mechanism is employed to dynamically suppress the influence of low-confidence samples during adaptation. Experimental results on benchmark datasets show that our method significantly improves the performance on the most widely used classification datasets.
PARD: Accelerating LLM Inference with Low-Cost PARallel Draft Model Adaptation
Apr 29, 2025



The autoregressive nature of large language models (LLMs) limits inference speed. Each forward pass generates only a single token and is often bottlenecked by memory bandwidth. Speculative decoding alleviates this issue using a draft-then-verify approach to accelerate token generation. However, the overhead introduced during the draft phase and the training cost of the draft model limit the efficiency and adaptability of speculative decoding. In this work, we introduce PARallel Draft (PARD), a novel speculative decoding method that enables low-cost adaptation of autoregressive draft models into parallel draft models. PARD enhances inference efficiency by predicting multiple future tokens in a single forward pass of the draft phase, and incorporates a conditional drop token method to accelerate training. Its target-independence property allows a single draft model to be applied to an entire family of different models, minimizing the adaptation cost. Our proposed conditional drop token method can improves draft model training efficiency by 3x. On our optimized inference framework, PARD accelerates LLaMA3.1-8B inference by 4.08x, achieving 311.5 tokens per second.
Visual Reranking with Improved Image Graph
Jun 03, 2014
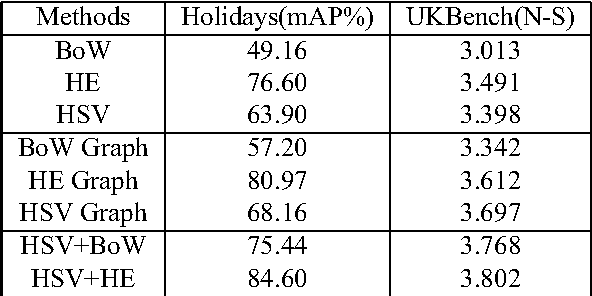


This paper introduces an improved reranking method for the Bag-of-Words (BoW) based image search. Built on [1], a directed image graph robust to outlier distraction is proposed. In our approach, the relevance among images is encoded in the image graph, based on which the initial rank list is refined. Moreover, we show that the rank-level feature fusion can be adopted in this reranking method as well. Taking advantage of the complementary nature of various features, the reranking performance is further enhanced. Particularly, we exploit the reranking method combining the BoW and color information. Experiments on two benchmark datasets demonstrate that ourmethod yields significant improvements and the reranking results are competitive to the state-of-the-art methods.
Packing and Padding: Coupled Multi-index for Accurate Image Retrieval
Apr 13, 2014
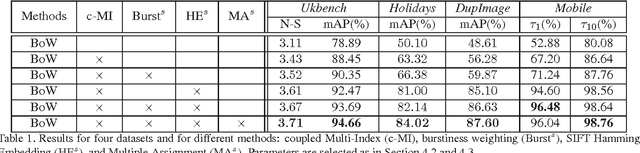
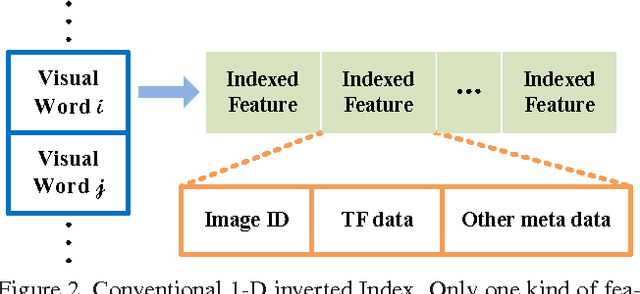

In Bag-of-Words (BoW) based image retrieval, the SIFT visual word has a low discriminative power, so false positive matches occur prevalently. Apart from the information loss during quantization, another cause is that the SIFT feature only describes the local gradient distribution. To address this problem, this paper proposes a coupled Multi-Index (c-MI) framework to perform feature fusion at indexing level. Basically, complementary features are coupled into a multi-dimensional inverted index. Each dimension of c-MI corresponds to one kind of feature, and the retrieval process votes for images similar in both SIFT and other feature spaces. Specifically, we exploit the fusion of local color feature into c-MI. While the precision of visual match is greatly enhanced, we adopt Multiple Assignment to improve recall. The joint cooperation of SIFT and color features significantly reduces the impact of false positive matches. Extensive experiments on several benchmark datasets demonstrate that c-MI improves the retrieval accuracy significantly, while consuming only half of the query time compared to the baseline. Importantly, we show that c-MI is well complementary to many prior techniques. Assembling these methods, we have obtained an mAP of 85.8% and N-S score of 3.85 on Holidays and Ukbench datasets, respectively, which compare favorably with the state-of-the-arts.