 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMSeS: Robust and Adaptive Model Selection for Time-Series Anomaly Detection Algorithms
Feb 25, 2026Time-series data vary widely across domains, making a universal anomaly detector impractical. Methods that perform well on one dataset often fail to transfer because what counts as an anomaly is context dependent. The key challenge is to design a method that performs well in specific contexts while remaining adaptable across domains with varying data complexities. We present the Robust and Adaptive Model Selection for Time-Series Anomaly Detection RAMSeS framework. RAMSeS comprises two branches: (i) a stacking ensemble optimized with a genetic algorithm to leverage complementary detectors. (ii) An adaptive model-selection branch identifies the best single detector using techniques including Thompson sampling, robustness testing with generative adversarial networks, and Monte Carlo simulations. This dual strategy exploits the collective strength of multiple models and adapts to dataset-specific characteristics. We evaluate RAMSeS and show that it outperforms prior methods on F1.
RAG-E: Quantifying Retriever-Generator Alignment and Failure Modes
Jan 29, 2026Retrieval-Augmented Generation (RAG) systems combine dense retrievers and language models to ground LLM outputs in retrieved documents. However, the opacity of how these components interact creates challenges for deployment in high-stakes domains. We present RAG-E, an end-to-end explainability framework that quantifies retriever-generator alignment through mathematically grounded attribution methods. Our approach adapts Integrated Gradients for retriever analysis, introduces PMCSHAP, a Monte Carlo-stabilized Shapley Value approximation, for generator attribution, and introduces the Weighted Attribution-Relevance Gap (WARG) metric to measure how well a generator's document usage aligns with a retriever's ranking. Empirical analysis on TREC CAsT and FoodSafeSum reveals critical misalignments: for 47.4% to 66.7% of queries, generators ignore the retriever's top-ranked documents, while 48.1% to 65.9% rely on documents ranked as less relevant. These failure modes demonstrate that RAG output quality depends not solely on individual component performance but on their interplay, which can be audited via RAG-E.
Guiding Catalogue Enrichment with User Queries
Jun 11, 2024Techniques for knowledge graph (KGs) enrichment have been increasingly crucial for commercial applications that rely on evolving product catalogues. However, because of the huge search space of potential enrichment, predictions from KG completion (KGC) methods suffer from low precision, making them unreliable for real-world catalogues. Moreover, candidate facts for enrichment have varied relevance to users. While making correct predictions for incomplete triplets in KGs has been the main focus of KGC method, the relevance of when to apply such predictions has been neglected. Motivated by the product search use case, we address the angle of generating relevant completion for a catalogue using user search behaviour and the users property association with a product. In this paper, we present our intuition for identifying enrichable data points and use general-purpose KGs to show-case the performance benefits. In particular, we extract entity-predicate pairs from user queries, which are more likely to be correct and relevant, and use these pairs to guide the prediction of KGC methods. We assess our method on two popular encyclopedia KGs, DBPedia and YAGO 4. Our results from both automatic and human evaluations show that query guidance can significantly improve the correctness and relevance of prediction.
AutoML in Heavily Constrained Applications
Jun 29, 2023Optimizing a machine learning pipeline for a task at hand requires careful configuration of various hyperparameters, typically supported by an AutoML system that optimizes the hyperparameters for the given training dataset. Yet, depending on the AutoML system's own second-order meta-configuration, the performance of the AutoML process can vary significantly. Current AutoML systems cannot automatically adapt their own configuration to a specific use case. Further, they cannot compile user-defined application constraints on the effectiveness and efficiency of the pipeline and its generation. In this paper, we propose Caml, which uses meta-learning to automatically adapt its own AutoML parameters, such as the search strategy, the validation strategy, and the search space, for a task at hand. The dynamic AutoML strategy of Caml takes user-defined constraints into account and obtains constraint-satisfying pipelines with high predictive performance.
Learning Action Embeddings for Off-Policy Evaluation
May 06, 2023Off-policy evaluation (OPE) methods allow us to compute the expected reward of a policy by using the logged data collected by a different policy. OPE is a viable alternative to running expensive online A/B tests: it can speed up the development of new policies, and reduces the risk of exposing customers to suboptimal treatments. However, when the number of actions is large, or certain actions are under-explored by the logging policy, existing estimators based on inverse-propensity scoring (IPS) can have a high or even infinite variance. Saito and Joachims (arXiv:2202.06317v2 [cs.LG]) propose marginalized IPS (MIPS) that uses action embeddings instead, which reduces the variance of IPS in large action spaces. MIPS assumes that good action embeddings can be defined by the practitioner, which is difficult to do in many real-world applications. In this work, we explore learning action embeddings from logged data. In particular, we use intermediate outputs of a trained reward model to define action embeddings for MIPS. This approach extends MIPS to more applications, and in our experiments improves upon MIPS with pre-defined embeddings, as well as standard baselines, both on synthetic and real-world data. Our method does not make assumptions about the reward model class, and supports using additional action information to further improve the estimates. The proposed approach presents an appealing alternative to DR for combining the low variance of DM with the low bias of IPS.
ED2: Two-stage Active Learning for Error Detection -- Technical Report
Aug 17, 2019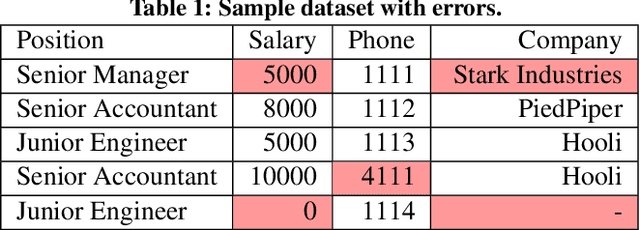
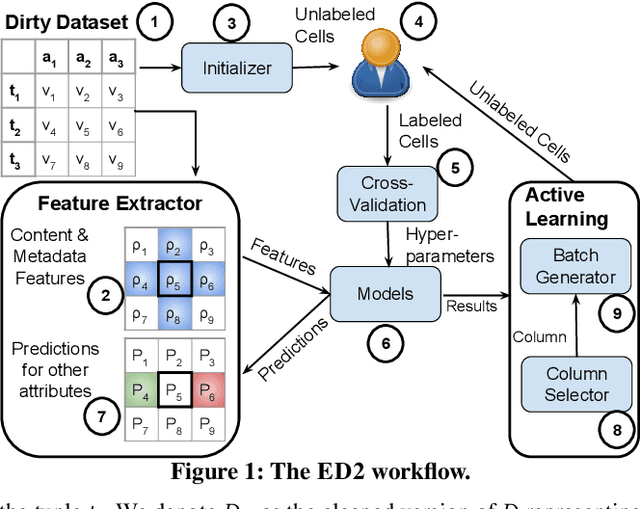
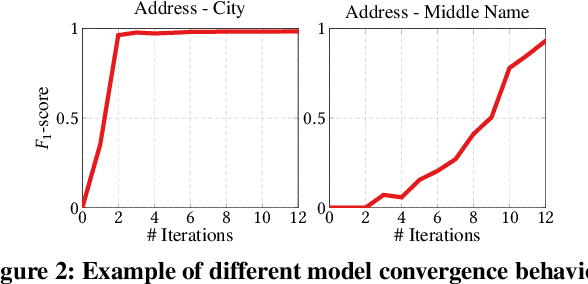
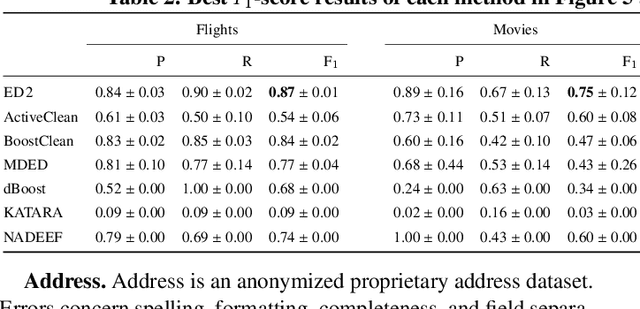
Traditional error detection approaches require user-defined parameters and rules. Thus, the user has to know both the error detection system and the data. However, we can also formulate error detection as a semi-supervised classification problem that only requires domain expertise. The challenges for such an approach are twofold: (1) to represent the data in a way that enables a classification model to identify various kinds of data errors, and (2) to pick the most promising data values for learning. In this paper, we address these challenges with ED2, our new example-driven error detection method. First, we present a new two-dimensional multi-classifier sampling strategy for active learning. Second, we propose novel multi-column features. The combined application of these techniques provides fast convergence of the classification task with high detection accuracy. On several real-world datasets, ED2 requires, on average, less than 1% labels to outperform existing error detection approaches. This report extends the peer-reviewed paper "ED2: A Case for Active Learning in Error Detection". All source code related to this project is available on GitHub.