 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-Downward and Ambient Video based Person Location Association
Dec 02, 2018
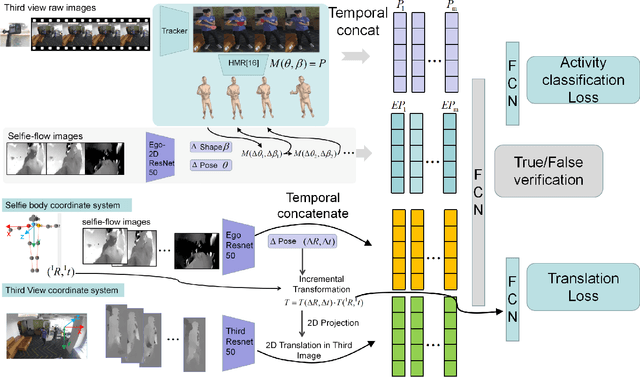
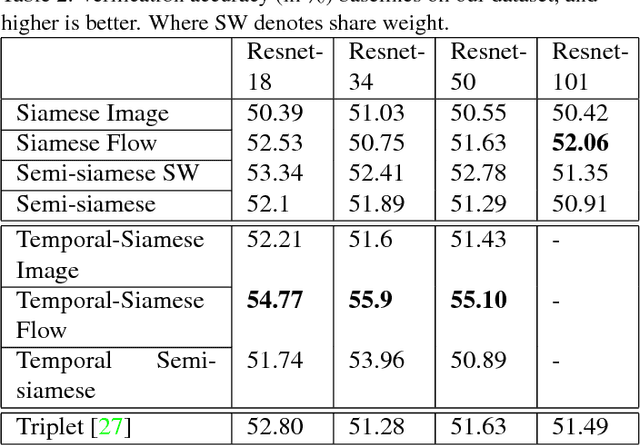
Using an ego-centric camera to do localization and tracking is highly needed for urban navigation and indoor assistive system when GPS is not available or not accurate enough. The traditional hand-designed feature tracking and estimation approach would fail without visible features. Recently, there are several works exploring to use context features to do localization. However, all of these suffer severe accuracy loss if given no visual context information. To provide a possible solution to this problem, this paper proposes a camera system with both ego-downward and third-static view to perform localization and tracking in a learning approach. Besides, we also proposed a novel action and motion verification model for cross-view verification and localization. We performed comparative experiments based on our collected dataset which considers the same dressing, gender, and background diversity. Results indicate that the proposed model can achieve $18.32 \%$ improvement in accuracy performance. Eventually, we tested the model on multi-people scenarios and obtained an average $67.767 \%$ accuracy.
Training Neural Networks Using Features Replay
Oct 27, 2018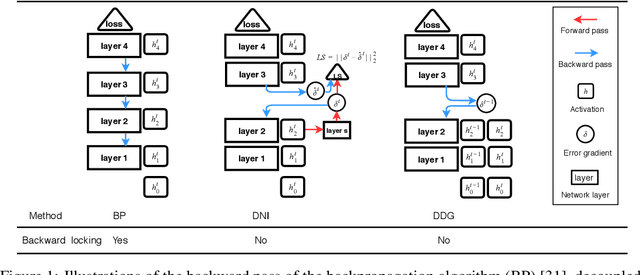

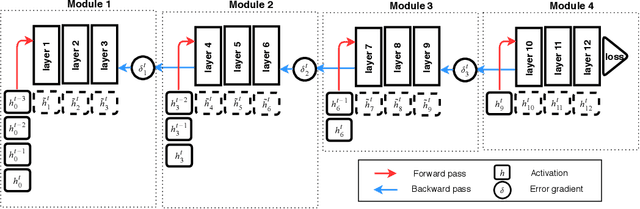
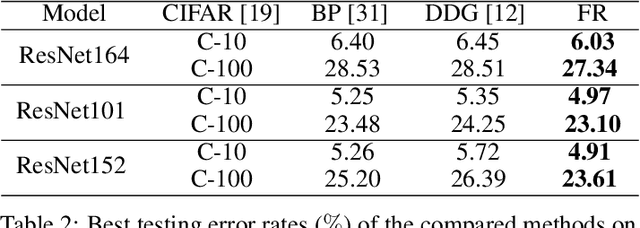
Training a neural network using backpropagation algorithm requires passing error gradients sequentially through the network. The backward locking prevents us from updating network layers in parallel and fully leveraging the computing resources. Recently, there are several works trying to decouple and parallelize the backpropagation algorithm. However, all of them suffer from severe accuracy loss or memory explosion when the neural network is deep. To address these challenging issues, we propose a novel parallel-objective formulation for the objective function of the neural network. After that, we introduce features replay algorithm and prove that it is guaranteed to converge to critical points for the non-convex problem under certain conditions. Finally, we apply our method to training deep convolutional neural networks, and the experimental results show that the proposed method achieves {faster} convergence, {lower} memory consumption, and {better} generalization error than compared methods.
Inexact Proximal Gradient Methods for Non-convex and Non-smooth Optimization
Sep 08, 2018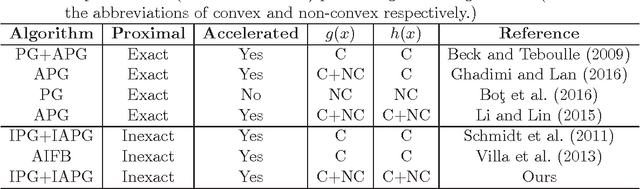
In machine learning research, the proximal gradient methods are popular for solving various optimization problems with non-smooth regularization. Inexact proximal gradient methods are extremely important when exactly solving the proximal operator is time-consuming, or the proximal operator does not have an analytic solution. However, existing inexact proximal gradient methods only consider convex problems. The knowledge of inexact proximal gradient methods in the non-convex setting is very limited. % Moreover, for some machine learning models, there is still no proposed solver for exactly solving the proximal operator. To address this challenge, in this paper, we first propose three inexact proximal gradient algorithms, including the basic version and Nesterov's accelerated version. After that, we provide the theoretical analysis to the basic and Nesterov's accelerated versions. The theoretical results show that our inexact proximal gradient algorithms can have the same convergence rates as the ones of exact proximal gradient algorithms in the non-convex setting. Finally, we show the applications of our inexact proximal gradient algorithms on three representative non-convex learning problems. All experimental results confirm the superiority of our new inexact proximal gradient algorithms.
Decoupled Parallel Backpropagation with Convergence Guarantee
Jul 21, 2018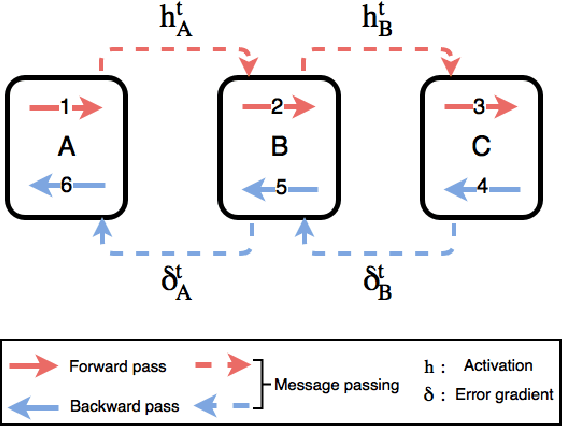
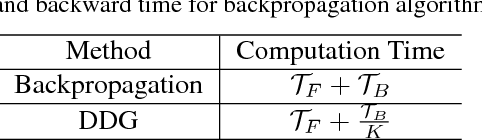
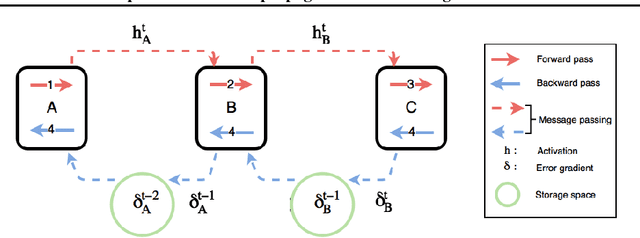
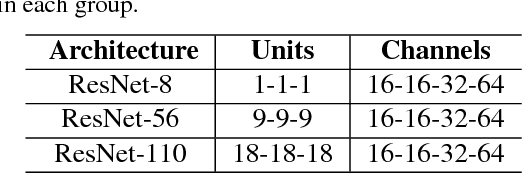
Backpropagation algorithm is indispensable for the training of feedforward neural networks. It requires propagating error gradients sequentially from the output layer all the way back to the input layer. The backward locking in backpropagation algorithm constrains us from updating network layers in parallel and fully leveraging the computing resources. Recently, several algorithms have been proposed for breaking the backward locking. However, their performances degrade seriously when networks are deep. In this paper, we propose decoupled parallel backpropagation algorithm for deep learning optimization with convergence guarantee. Firstly, we decouple the backpropagation algorithm using delayed gradients, and show that the backward locking is removed when we split the networks into multiple modules. Then, we utilize decoupled parallel backpropagation in two stochastic methods and prove that our method guarantees convergence to critical points for the non-convex problem. Finally, we perform experiments for training deep convolutional neural networks on benchmark datasets. The experimental results not only confirm our theoretical analysis, but also demonstrate that the proposed method can achieve significant speedup without loss of accuracy.
Accelerated Method for Stochastic Composition Optimization with Nonsmooth Regularization
Dec 29, 2017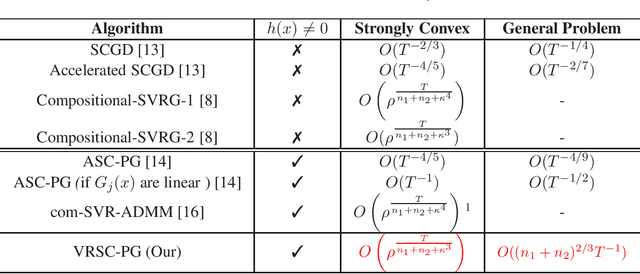
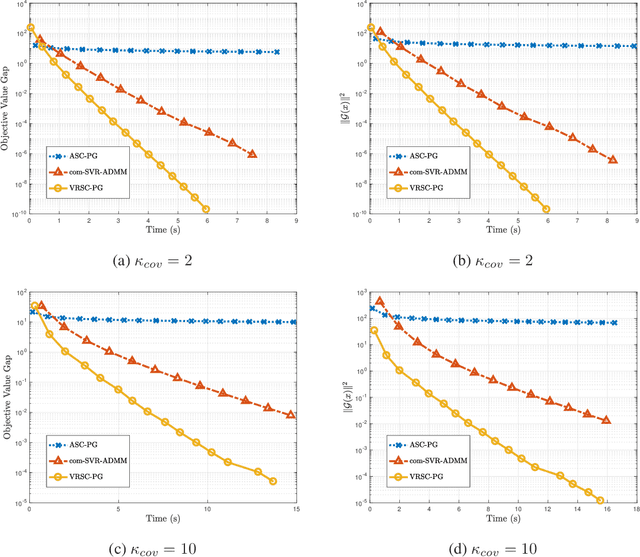
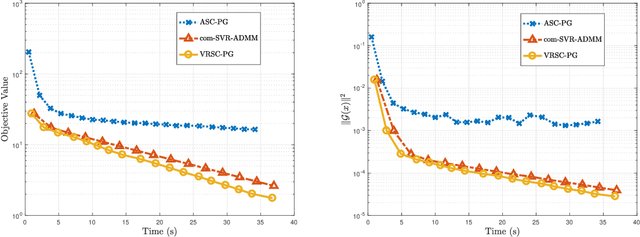
Stochastic composition optimization draws much attention recently and has been successful in many emerging applications of machine learning, statistical analysis, and reinforcement learning. In this paper, we focus on the composition problem with nonsmooth regularization penalty. Previous works either have slow convergence rate or do not provide complete convergence analysis for the general problem. In this paper, we tackle these two issues by proposing a new stochastic composition optimization method for composition problem with nonsmooth regularization penalty. In our method, we apply variance reduction technique to accelerate the speed of convergence. To the best of our knowledge, our method admits the fastest convergence rate for stochastic composition optimization: for strongly convex composition problem, our algorithm is proved to admit linear convergence; for general composition problem, our algorithm significantly improves the state-of-the-art convergence rate from $O(T^{-1/2})$ to $O((n_1+n_2)^{{2}/{3}}T^{-1})$. Finally, we apply our proposed algorithm to portfolio management and policy evaluation in reinforcement learning. Experimental results verify our theoretical analysis.
Distributed Asynchronous Dual Free Stochastic Dual Coordinate Ascent
Oct 27, 2017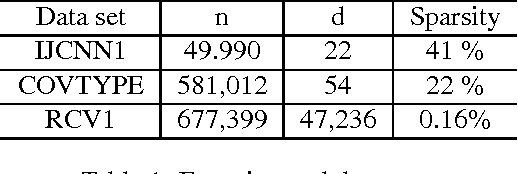
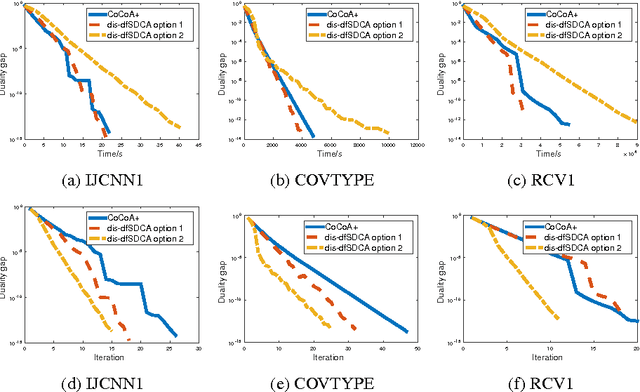
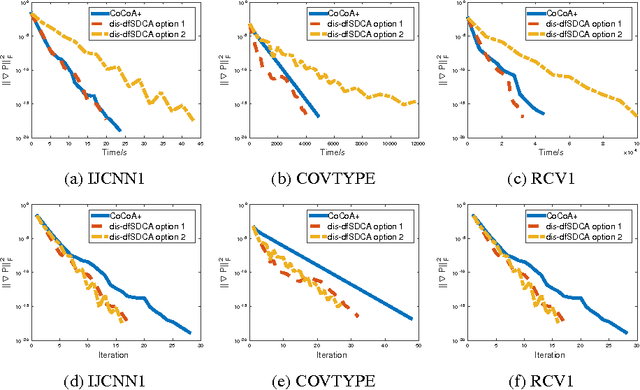
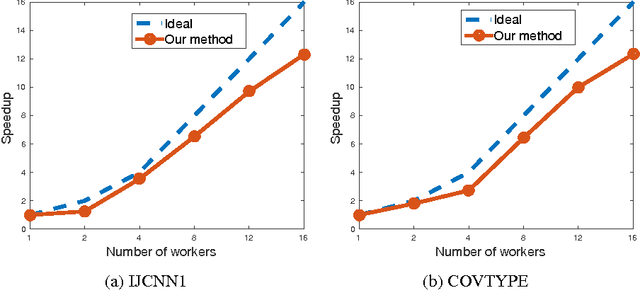
The primal-dual distributed optimization methods have broad large-scale machine learning applications. Previous primal-dual distributed methods are not applicable when the dual formulation is not available, e.g. the sum-of-non-convex objectives. Moreover, these algorithms and theoretical analysis are based on the fundamental assumption that the computing speeds of multiple machines in a cluster are similar. However, the straggler problem is an unavoidable practical issue in the distributed system because of the existence of slow machines. Therefore, the total computational time of the distributed optimization methods is highly dependent on the slowest machine. In this paper, we address these two issues by proposing distributed asynchronous dual free stochastic dual coordinate ascent algorithm for distributed optimization. Our method does not need the dual formulation of the target problem in the optimization. We tackle the straggler problem through asynchronous communication and the negative effect of slow machines is significantly alleviated. We also analyze the convergence rate of our method and prove the linear convergence rate even if the individual functions in objective are non-convex. Experiments on both convex and non-convex loss functions are used to validate our statements.
Asynchronous Stochastic Gradient Descent with Variance Reduction for Non-Convex Optimization
Dec 20, 2016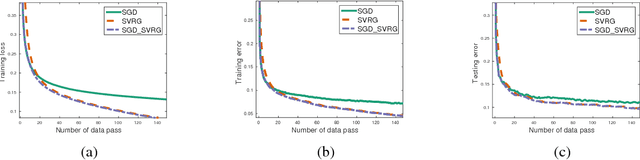
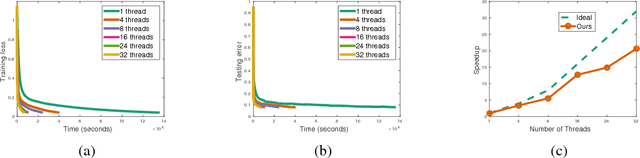

We provide the first theoretical analysis on the convergence rate of the asynchronous stochastic variance reduced gradient (SVRG) descent algorithm on non-convex optimization. Recent studies have shown that the asynchronous stochastic gradient descent (SGD) based algorithms with variance reduction converge with a linear convergent rate on convex problems. However, there is no work to analyze asynchronous SGD with variance reduction technique on non-convex problem. In this paper, we study two asynchronous parallel implementations of SVRG: one is on a distributed memory system and the other is on a shared memory system. We provide the theoretical analysis that both algorithms can obtain a convergence rate of $O(1/T)$, and linear speed up is achievable if the number of workers is upper bounded. V1,v2,v3 have been withdrawn due to reference issue, please refer the newest version v4.
Zeroth-order Asynchronous Doubly Stochastic Algorithm with Variance Reduction
Dec 05, 2016
Zeroth-order (derivative-free) optimization attracts a lot of attention in machine learning, because explicit gradient calculations may be computationally expensive or infeasible. To handle large scale problems both in volume and dimension, recently asynchronous doubly stochastic zeroth-order algorithms were proposed. The convergence rate of existing asynchronous doubly stochastic zeroth order algorithms is $O(\frac{1}{\sqrt{T}})$ (also for the sequential stochastic zeroth-order optimization algorithms). In this paper, we focus on the finite sums of smooth but not necessarily convex functions, and propose an asynchronous doubly stochastic zeroth-order optimization algorithm using the accelerated technology of variance reduction (AsyDSZOVR). Rigorous theoretical analysis show that the convergence rate can be improved from $O(\frac{1}{\sqrt{T}})$ the best result of existing algorithms to $O(\frac{1}{T})$. Also our theoretical results is an improvement to the ones of the sequential stochastic zeroth-order optimization algorithms.
Asynchronous Stochastic Block Coordinate Descent with Variance Reduction
Nov 14, 2016Asynchronous parallel implementations for stochastic optimization have received huge successes in theory and practice recently. Asynchronous implementations with lock-free are more efficient than the one with writing or reading lock. In this paper, we focus on a composite objective function consisting of a smooth convex function $f$ and a block separable convex function, which widely exists in machine learning and computer vision. We propose an asynchronous stochastic block coordinate descent algorithm with the accelerated technology of variance reduction (AsySBCDVR), which are with lock-free in the implementation and analysis. AsySBCDVR is particularly important because it can scale well with the sample size and dimension simultaneously. We prove that AsySBCDVR achieves a linear convergence rate when the function $f$ is with the optimal strong convexity property, and a sublinear rate when $f$ is with the general convexity. More importantly, a near-linear speedup on a parallel system with shared memory can be obtained.
Decoupled Asynchronous Proximal Stochastic Gradient Descent with Variance Reduction
Sep 29, 2016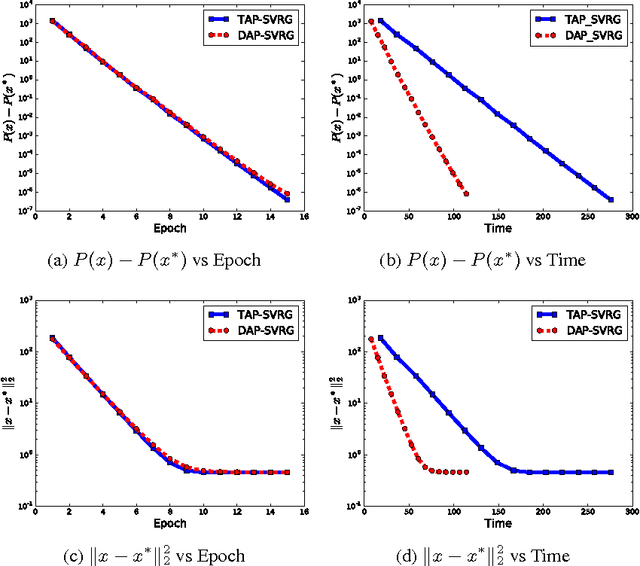
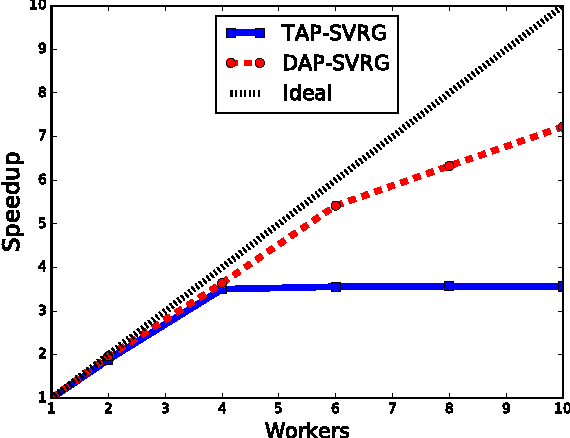
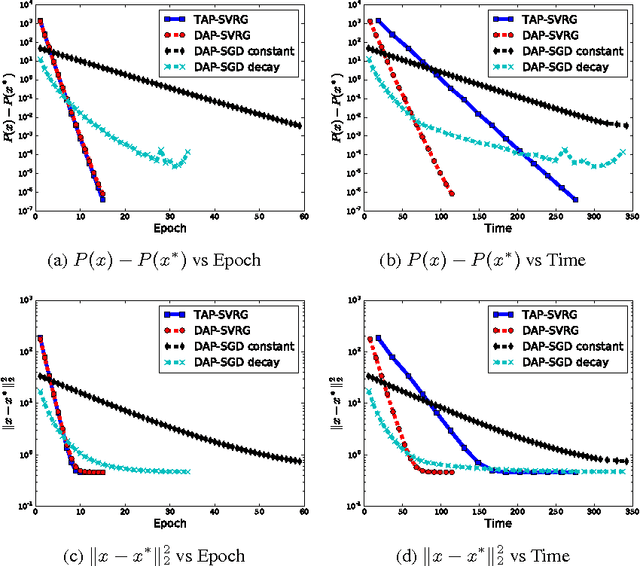
In the era of big data, optimizing large scale machine learning problems becomes a challenging task and draws significant attention. Asynchronous optimization algorithms come out as a promising solution. Recently, decoupled asynchronous proximal stochastic gradient descent (DAP-SGD) is proposed to minimize a composite function. It is claimed to be able to off-loads the computation bottleneck from server to workers by allowing workers to evaluate the proximal operators, therefore, server just need to do element-wise operations. However, it still suffers from slow convergence rate because of the variance of stochastic gradient is nonzero. In this paper, we propose a faster method, decoupled asynchronous proximal stochastic variance reduced gradient descent method (DAP-SVRG). We prove that our method has linear convergence for strongly convex problem. Large-scale experiments are also conducted in this paper, and results demonstrate our theoretical analysis.