 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving information retrieval from electronic health records using dynamic and multi-collaborative filtering
Aug 12, 2020

Due to the rapid growth of information available about individual patients, most physicians suffer from information overload when they review patient information in health information technology systems. In this manuscript, we present a novel hybrid dynamic and multi-collaborative filtering method to improve information retrieval from electronic health records. This method recommends relevant information from electronic health records for physicians during patient visits. It models information search dynamics using a Markov model. It also leverages the key idea of collaborative filtering, originating from Recommender Systems, to prioritize information based on various similarities among physicians, patients and information items. We tested this new method using real electronic health record data from the Indiana Network for Patient Care. Our experimental results demonstrated that for 46.7% of testing cases, this new method is able to correctly prioritize relevant information among top-5 recommendations that physicians are truly interested in.
Hybrid Collaborative Filtering Models for Clinical Search Recommendation
Jul 19, 2020With increasing and extensive use of electronic health records, clinicians are often under time pressure when they need to retrieve important information efficiently among large amounts of patients' health records in clinics. While a search function can be a useful alternative to browsing through a patient's record, it is cumbersome for clinicians to search repeatedly for the same or similar information on similar patients. Under such circumstances, there is a critical need to build effective recommender systems that can generate accurate search term recommendations for clinicians. In this manuscript, we developed a hybrid collaborative filtering model using patients' encounter and search term information to recommend the next search terms for clinicians to retrieve important information fast in clinics. For each patient, the model will recommend terms that either have high co-occurrence frequencies with his/her most recent ICD codes or are highly relevant to the most recent search terms on this patient. We have conducted comprehensive experiments to evaluate the proposed model, and the experimental results demonstrate that our model can outperform all the state-of-the-art baseline methods for top-N search term recommendation on different datasets.
M2pht: Mixed Models with Preferences and Hybrid Transitions for Next-Basket Recommendation
Apr 03, 2020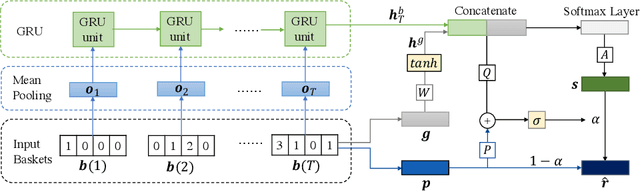

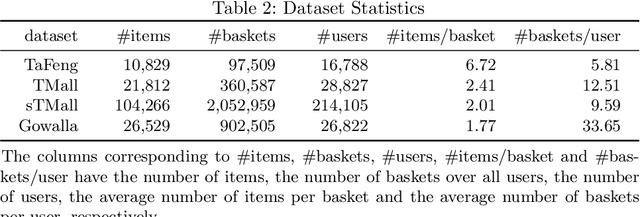
Next-basket recommendation considers the problem of recommending a set of items into the next basket that users will purchase as a whole. In this paper, we develop a new mixed model with preferences and hybrid transitions for the next-basket recommendation problem. This method explicitly models three important factors: 1) users' general preferences; 2) transition patterns among items and 3) transition patterns among baskets. We compared this method with 5 state-of-the-art next-basket recommendation methods on 4 public benchmark datasets. Our experimental results demonstrate that our method significantly outperforms the state-of-the-art methods on all the datasets. We also conducted a comprehensive ablation study to verify the effectiveness of the different factors.
ALE: Additive Latent Effect Models for Grade Prediction
Jan 17, 2018

The past decade has seen a growth in the development and deployment of educational technologies for assisting college-going students in choosing majors, selecting courses and acquiring feedback based on past academic performance. Grade prediction methods seek to estimate a grade that a student may achieve in a course that she may take in the future (e.g., next term). Accurate and timely prediction of students' academic grades is important for developing effective degree planners and early warning systems, and ultimately improving educational outcomes. Existing grade pre- diction methods mostly focus on modeling the knowledge components associated with each course and student, and often overlook other factors such as the difficulty of each knowledge component, course instructors, student interest, capabilities and effort. In this paper, we propose additive latent effect models that incorporate these factors to predict the student next-term grades. Specifically, the proposed models take into account four factors: (i) student's academic level, (ii) course instructors, (iii) student global latent factor, and (iv) latent knowledge factors. We compared the new models with several state-of-the-art methods on students of various characteristics (e.g., whether a student transferred in or not). The experimental results demonstrate that the proposed methods significantly outperform the baselines on grade prediction problem. Moreover, we perform a thorough analysis on the importance of different factors and how these factors can practically assist students in course selection, and finally improve their academic performance.
Grade Prediction with Temporal Course-wise Influence
Sep 15, 2017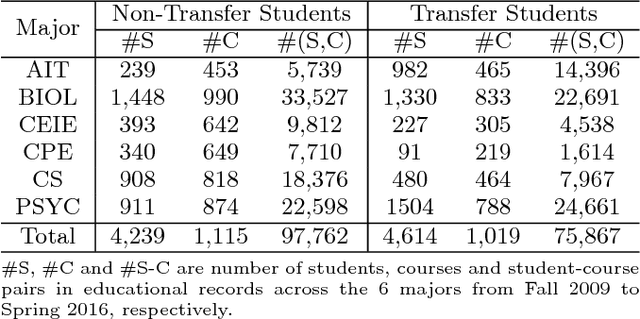
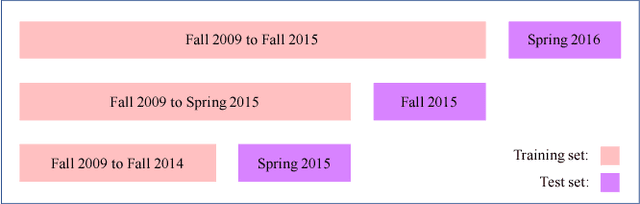

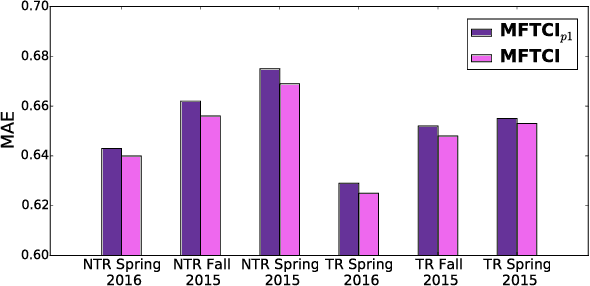
There is a critical need to develop new educational technology applications that analyze the data collected by universities to ensure that students graduate in a timely fashion (4 to 6 years); and they are well prepared for jobs in their respective fields of study. In this paper, we present a novel approach for analyzing historical educational records from a large, public university to perform next-term grade prediction; i.e., to estimate the grades that a student will get in a course that he/she will enroll in the next term. Accurate next-term grade prediction holds the promise for better student degree planning, personalized advising and automated interventions to ensure that students stay on track in their chosen degree program and graduate on time. We present a factorization-based approach called Matrix Factorization with Temporal Course-wise Influence that incorporates course-wise influence effects and temporal effects for grade prediction. In this model, students and courses are represented in a latent "knowledge" space. The grade of a student on a course is modeled as the similarity of their latent representation in the "knowledge" space. Course-wise influence is considered as an additional factor in the grade prediction. Our experimental results show that the proposed method outperforms several baseline approaches and infer meaningful patterns between pairs of courses within academic programs.
Predicting Performance on MOOC Assessments using Multi-Regression Models
May 08, 2016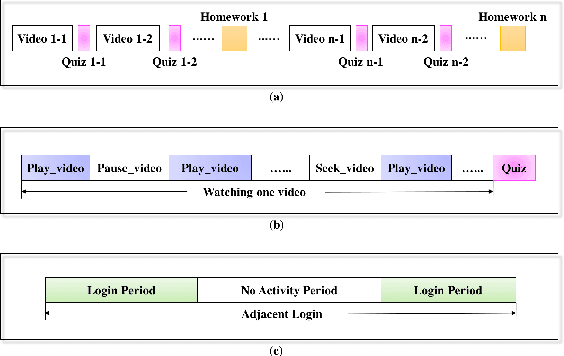
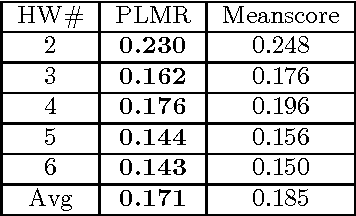
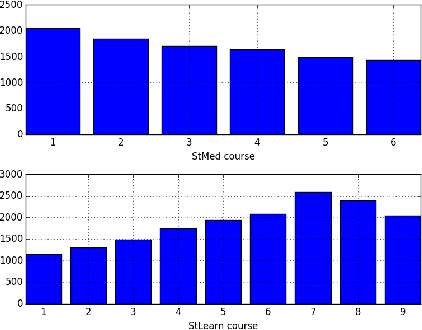
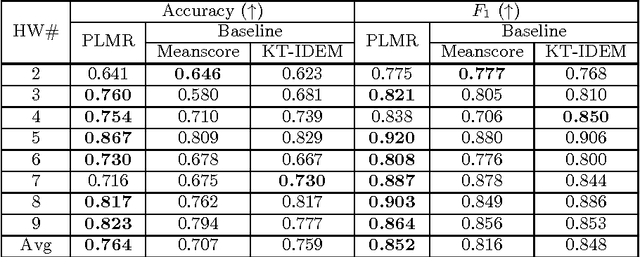
The past few years has seen the rapid growth of data min- ing approaches for the analysis of data obtained from Mas- sive Open Online Courses (MOOCs). The objectives of this study are to develop approaches to predict the scores a stu- dent may achieve on a given grade-related assessment based on information, considered as prior performance or prior ac- tivity in the course. We develop a personalized linear mul- tiple regression (PLMR) model to predict the grade for a student, prior to attempting the assessment activity. The developed model is real-time and tracks the participation of a student within a MOOC (via click-stream server logs) and predicts the performance of a student on the next as- sessment within the course offering. We perform a com- prehensive set of experiments on data obtained from three openEdX MOOCs via a Stanford University initiative. Our experimental results show the promise of the proposed ap- proach in comparison to baseline approaches and also helps in identification of key features that are associated with the study habits and learning behaviors of students.