 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Scanning Parameter Configuration for Robotic Inspection Using Vision Language Embeddings and Hyperdimensional Computing
May 05, 2026Robotic laser profiling is widely used for dimensional verification and surface inspection, yet measurement fidelity is often dominated by sensor configuration rather than robot motion. Industrial profilers expose multiple coupled parameters, including sampling frequency, measurement range, exposure time, receiver dynamic range, and illumination, that are still tuned by trial-and-error; mismatches can cause saturation, clipping, or missing returns that cannot be recovered downstream. We formulate instruction-conditioned sensing parameter recommendation; given a pre-scan RGB observation and a natural-language inspection instruction, infer a discrete configuration over key parameters of a robot-mounted profiler. To benchmark this problem, we develop Instruct-Obs2Param, a real-world multimodal dataset linking inspection intents and multi-view pose and illumination variation across 16 objects to canonical parameter regimes. We then propose ScanHD, a hyperdimensional computing framework that binds instruction and observation into a task-aware code and performs parameter-wise associative reasoning with compact memories, matching discrete scanner regimes while yielding stable, interpretable, low-latency decisions. On Instruct-Obs2Param, ScanHD achieves 92.7% average exact accuracy and 98.1% average Win@1 accuracy across the five parameters, with strong cross-split generalization and low-latency inference suitable for deployment, outperforming rule-based heuristics, conventional multimodal models, and multimodal large language models. This work enables autonomous, instruction-conditioned sensing configuration from task intent and scene context, eliminating manual tuning and elevating sensor configuration from a static setting to an adaptive decision variable.
ScanBot: Towards Intelligent Surface Scanning in Embodied Robotic Systems
May 22, 2025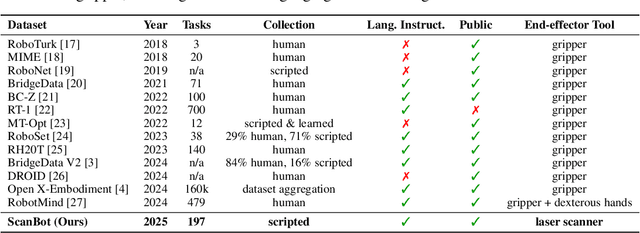



We introduce ScanBot, a novel dataset designed for instruction-conditioned, high-precision surface scanning in robotic systems. In contrast to existing robot learning datasets that focus on coarse tasks such as grasping, navigation, or dialogue, ScanBot targets the high-precision demands of industrial laser scanning, where sub-millimeter path continuity and parameter stability are critical. The dataset covers laser scanning trajectories executed by a robot across 12 diverse objects and 6 task types, including full-surface scans, geometry-focused regions, spatially referenced parts, functionally relevant structures, defect inspection, and comparative analysis. Each scan is guided by natural language instructions and paired with synchronized RGB, depth, and laser profiles, as well as robot pose and joint states. Despite recent progress, existing vision-language action (VLA) models still fail to generate stable scanning trajectories under fine-grained instructions and real-world precision demands. To investigate this limitation, we benchmark a range of multimodal large language models (MLLMs) across the full perception-planning-execution loop, revealing persistent challenges in instruction-following under realistic constraints.
Multimodal RAG-driven Anomaly Detection and Classification in Laser Powder Bed Fusion using Large Language Models
May 20, 2025Additive manufacturing enables the fabrication of complex designs while minimizing waste, but faces challenges related to defects and process anomalies. This study presents a novel multimodal Retrieval-Augmented Generation-based framework that automates anomaly detection across various Additive Manufacturing processes leveraging retrieved information from literature, including images and descriptive text, rather than training datasets. This framework integrates text and image retrieval from scientific literature and multimodal generation models to perform zero-shot anomaly identification, classification, and explanation generation in a Laser Powder Bed Fusion setting. The proposed framework is evaluated on four L-PBF manufacturing datasets from Oak Ridge National Laboratory, featuring various printer makes, models, and materials. This evaluation demonstrates the framework's adaptability and generalizability across diverse images without requiring additional training. Comparative analysis using Qwen2-VL-2B and GPT-4o-mini as MLLM within the proposed framework highlights that GPT-4o-mini outperforms Qwen2-VL-2B and proportional random baseline in manufacturing anomalies classification. Additionally, the evaluation of the RAG system confirms that incorporating retrieval mechanisms improves average accuracy by 12% by reducing the risk of hallucination and providing additional information. The proposed framework can be continuously updated by integrating emerging research, allowing seamless adaptation to the evolving landscape of AM technologies. This scalable, automated, and zero-shot-capable framework streamlines AM anomaly analysis, enhancing efficiency and accuracy.
Can Multimodal Large Language Models be Guided to Improve Industrial Anomaly Detection?
Jan 27, 2025In industrial settings, the accurate detection of anomalies is essential for maintaining product quality and ensuring operational safety. Traditional industrial anomaly detection (IAD) models often struggle with flexibility and adaptability, especially in dynamic production environments where new defect types and operational changes frequently arise. Recent advancements in Multimodal Large Language Models (MLLMs) hold promise for overcoming these limitations by combining visual and textual information processing capabilities. MLLMs excel in general visual understanding due to their training on large, diverse datasets, but they lack domain-specific knowledge, such as industry-specific defect tolerance levels, which limits their effectiveness in IAD tasks. To address these challenges, we propose Echo, a novel multi-expert framework designed to enhance MLLM performance for IAD. Echo integrates four expert modules: Reference Extractor which provides a contextual baseline by retrieving similar normal images, Knowledge Guide which supplies domain-specific insights, Reasoning Expert which enables structured, stepwise reasoning for complex queries, and Decision Maker which synthesizes information from all modules to deliver precise, context-aware responses. Evaluated on the MMAD benchmark, Echo demonstrates significant improvements in adaptability, precision, and robustness, moving closer to meeting the demands of real-world industrial anomaly detection.
Vision Language Model for Interpretable and Fine-grained Detection of Safety Compliance in Diverse Workplaces
Aug 13, 2024Workplace accidents due to personal protective equipment (PPE) non-compliance raise serious safety concerns and lead to legal liabilities, financial penalties, and reputational damage. While object detection models have shown the capability to address this issue by identifying safety items, most existing models, such as YOLO, Faster R-CNN, and SSD, are limited in verifying the fine-grained attributes of PPE across diverse workplace scenarios. Vision language models (VLMs) are gaining traction for detection tasks by leveraging the synergy between visual and textual information, offering a promising solution to traditional object detection limitations in PPE recognition. Nonetheless, VLMs face challenges in consistently verifying PPE attributes due to the complexity and variability of workplace environments, requiring them to interpret context-specific language and visual cues simultaneously. We introduce Clip2Safety, an interpretable detection framework for diverse workplace safety compliance, which comprises four main modules: scene recognition, the visual prompt, safety items detection, and fine-grained verification. The scene recognition identifies the current scenario to determine the necessary safety gear. The visual prompt formulates the specific visual prompts needed for the detection process. The safety items detection identifies whether the required safety gear is being worn according to the specified scenario. Lastly, the fine-grained verification assesses whether the worn safety equipment meets the fine-grained attribute requirements. We conduct real-world case studies across six different scenarios. The results show that Clip2Safety not only demonstrates an accuracy improvement over state-of-the-art question-answering based VLMs but also achieves inference times two hundred times faster.