 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe TEA-ASLP System for Multilingual Conversational Speech Recognition and Speech Diarization in MLC-SLM 2025 Challenge
Jul 24, 2025This paper presents the TEA-ASLP's system submitted to the MLC-SLM 2025 Challenge, addressing multilingual conversational automatic speech recognition (ASR) in Task I and speech diarization ASR in Task II. For Task I, we enhance Ideal-LLM model by integrating known language identification and a multilingual MOE LoRA structure, along with using CTC-predicted tokens as prompts to improve autoregressive generation. The model is trained on approximately 180k hours of multilingual ASR data. In Task II, we replace the baseline English-Chinese speaker diarization model with a more suitable English-only version. Our approach achieves a 30.8% reduction in word error rate (WER) compared to the baseline speech language model, resulting in a final WER of 9.60% in Task I and a time-constrained minimum-permutation WER of 17.49% in Task II, earning first and second place in the respective challenge tasks.
Chain of Correction for Full-text Speech Recognition with Large Language Models
Apr 02, 2025Full-text error correction with Large Language Models (LLMs) for Automatic Speech Recognition (ASR) has gained increased attention due to its potential to correct errors across long contexts and address a broader spectrum of error types, including punctuation restoration and inverse text normalization. Nevertheless, many challenges persist, including issues related to stability, controllability, completeness, and fluency. To mitigate these challenges, this paper proposes the Chain of Correction (CoC) for full-text error correction with LLMs, which corrects errors segment by segment using pre-recognized text as guidance within a regular multi-turn chat format. The CoC also uses pre-recognized full text for context, allowing the model to better grasp global semantics and maintain a comprehensive overview of the entire content. Utilizing the open-sourced full-text error correction dataset ChFT, we fine-tune a pre-trained LLM to evaluate the performance of the CoC framework. Experimental results demonstrate that the CoC effectively corrects errors in full-text ASR outputs, significantly outperforming baseline and benchmark systems. We further analyze how to set the correction threshold to balance under-correction and over-rephrasing, extrapolate the CoC model on extremely long ASR outputs, and investigate whether other types of information can be employed to guide the error correction process.
The SJTU System for Short-duration Speaker Verification Challenge 2021
Aug 03, 2022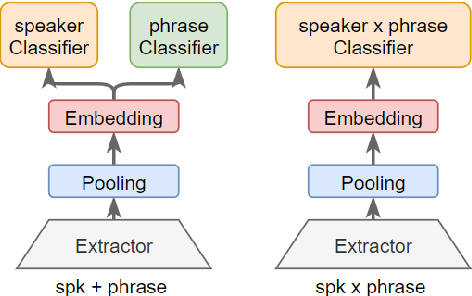
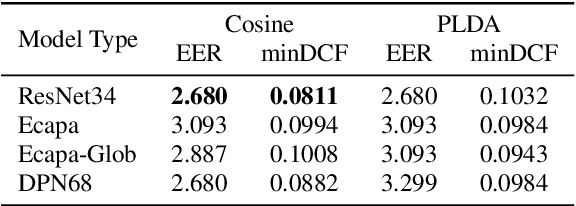
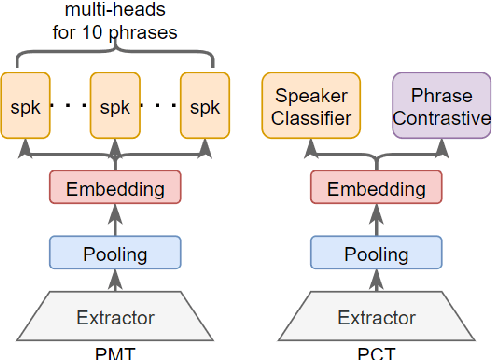
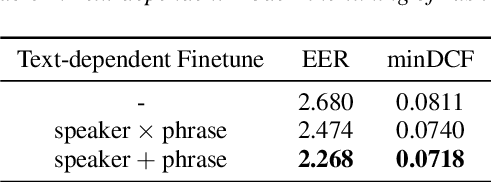
This paper presents the SJTU system for both text-dependent and text-independent tasks in short-duration speaker verification (SdSV) challenge 2021. In this challenge, we explored different strong embedding extractors to extract robust speaker embedding. For text-independent task, language-dependent adaptive snorm is explored to improve the system performance under the cross-lingual verification condition. For text-dependent task, we mainly focus on the in-domain fine-tuning strategies based on the model pre-trained on large-scale out-of-domain data. In order to improve the distinction between different speakers uttering the same phrase, we proposed several novel phrase-aware fine-tuning strategies and phrase-aware neural PLDA. With such strategies, the system performance is further improved. Finally, we fused the scores of different systems, and our fusion systems achieved 0.0473 in Task1 (rank 3) and 0.0581 in Task2 (rank 8) on the primary evaluation metric.
Knowledge Transfer and Distillation from Autoregressive to Non-Autoregressive Speech Recognition
Jul 15, 2022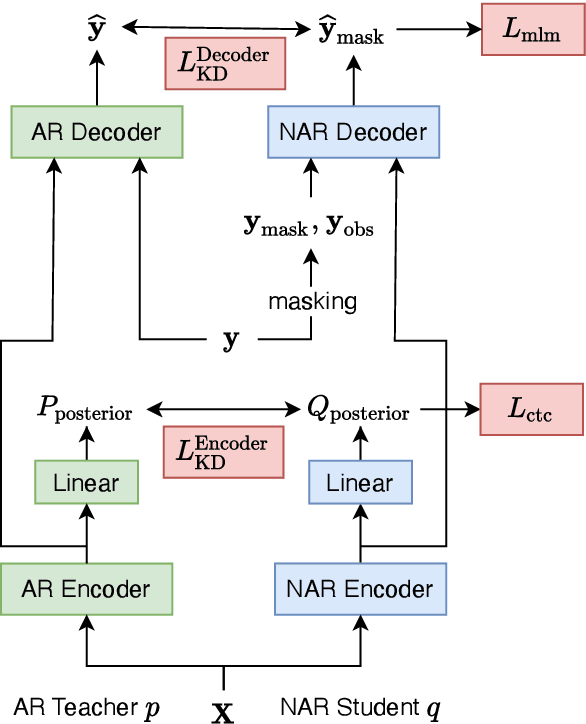
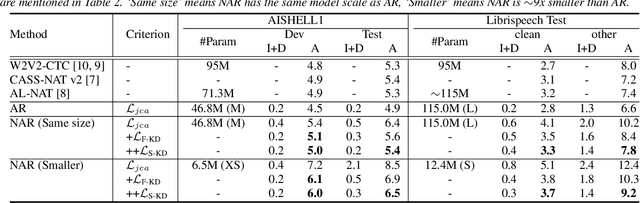
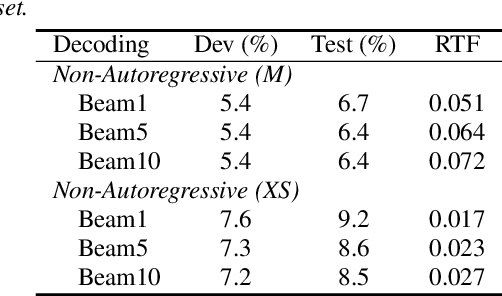
Modern non-autoregressive~(NAR) speech recognition systems aim to accelerate the inference speed; however, they suffer from performance degradation compared with autoregressive~(AR) models as well as the huge model size issue. We propose a novel knowledge transfer and distillation architecture that leverages knowledge from AR models to improve the NAR performance while reducing the model's size. Frame- and sequence-level objectives are well-designed for transfer learning. To further boost the performance of NAR, a beam search method on Mask-CTC is developed to enlarge the search space during the inference stage. Experiments show that the proposed NAR beam search relatively reduces CER by over 5% on AISHELL-1 benchmark with a tolerable real-time-factor~(RTF) increment. By knowledge transfer, the NAR student who has the same size as the AR teacher obtains relative CER reductions of 8/16% on AISHELL-1 dev/test sets, and over 25% relative WER reductions on LibriSpeech test-clean/other sets. Moreover, the ~9x smaller NAR models achieve ~25% relative CER/WER reductions on both AISHELL-1 and LibriSpeech benchmarks with the proposed knowledge transfer and distillation.
Layer-wise Fast Adaptation for End-to-End Multi-Accent Speech Recognition
Apr 21, 2022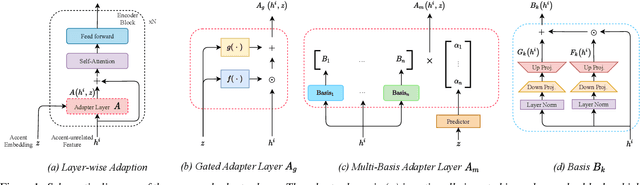
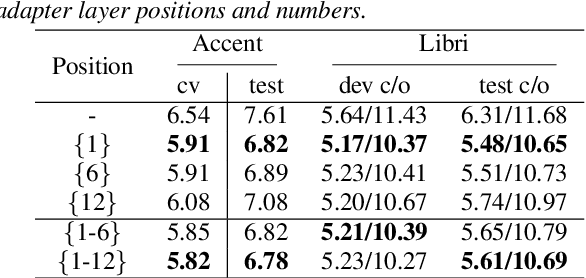
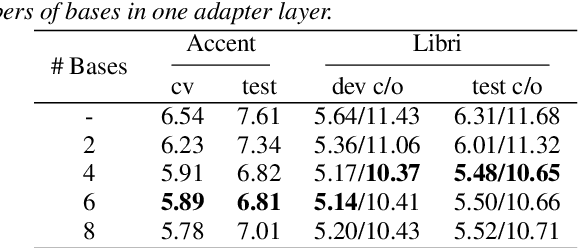
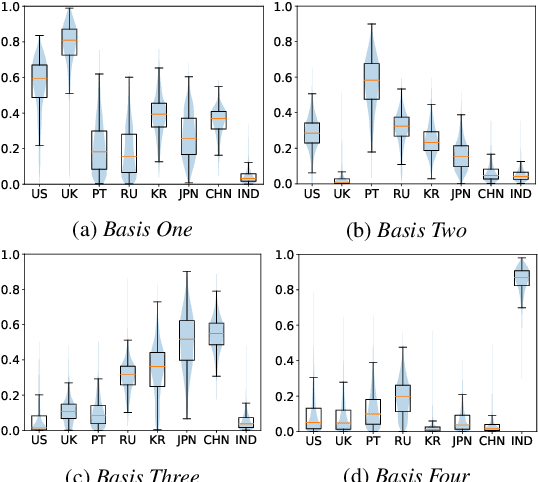
Accent variability has posed a huge challenge to automatic speech recognition~(ASR) modeling. Although one-hot accent vector based adaptation systems are commonly used, they require prior knowledge about the target accent and cannot handle unseen accents. Furthermore, simply concatenating accent embeddings does not make good use of accent knowledge, which has limited improvements. In this work, we aim to tackle these problems with a novel layer-wise adaptation structure injected into the E2E ASR model encoder. The adapter layer encodes an arbitrary accent in the accent space and assists the ASR model in recognizing accented speech. Given an utterance, the adaptation structure extracts the corresponding accent information and transforms the input acoustic feature into an accent-related feature through the linear combination of all accent bases. We further explore the injection position of the adaptation layer, the number of accent bases, and different types of accent bases to achieve better accent adaptation. Experimental results show that the proposed adaptation structure brings 12\% and 10\% relative word error rate~(WER) reduction on the AESRC2020 accent dataset and the Librispeech dataset, respectively, compared to the baseline.
* Accepted by Interspeech2021