 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Animatable Avatar via Factorized Neural Fields
Jun 02, 2024For reconstructing high-fidelity human 3D models from monocular videos, it is crucial to maintain consistent large-scale body shapes along with finely matched subtle wrinkles. This paper explores the observation that the per-frame rendering results can be factorized into a pose-independent component and a corresponding pose-dependent equivalent to facilitate frame consistency. Pose adaptive textures can be further improved by restricting frequency bands of these two components. In detail, pose-independent outputs are expected to be low-frequency, while highfrequency information is linked to pose-dependent factors. We achieve a coherent preservation of both coarse body contours across the entire input video and finegrained texture features that are time variant with a dual-branch network with distinct frequency components. The first branch takes coordinates in canonical space as input, while the second branch additionally considers features outputted by the first branch and pose information of each frame. Our network integrates the information predicted by both branches and utilizes volume rendering to generate photo-realistic 3D human images. Through experiments, we demonstrate that our network surpasses the neural radiance fields (NeRF) based state-of-the-art methods in preserving high-frequency details and ensuring consistent body contours.
Neural Fourier Filter Bank
Dec 04, 2022We present a novel method to provide efficient and highly detailed reconstructions. Inspired by wavelets, our main idea is to learn a neural field that decompose the signal both spatially and frequency-wise. We follow the recent grid-based paradigm for spatial decomposition, but unlike existing work, encourage specific frequencies to be stored in each grid via Fourier features encodings. We then apply a multi-layer perceptron with sine activations, taking these Fourier encoded features in at appropriate layers so that higher-frequency components are accumulated on top of lower-frequency components sequentially, which we sum up to form the final output. We demonstrate that our method outperforms the state of the art regarding model compactness and efficiency on multiple tasks: 2D image fitting, 3D shape reconstruction, and neural radiance fields.
ETNet: Error Transition Network for Arbitrary Style Transfer
Oct 29, 2019

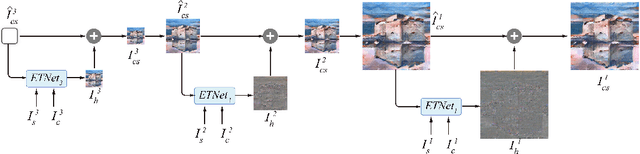

Numerous valuable efforts have been devoted to achieving arbitrary style transfer since the seminal work of Gatys et al. However, existing state-of-the-art approaches often generate insufficiently stylized results under challenging cases. We believe a fundamental reason is that these approaches try to generate the stylized result in a single shot and hence fail to fully satisfy the constraints on semantic structures in the content images and style patterns in the style images. Inspired by the works on error-correction, instead, we propose a self-correcting model to predict what is wrong with the current stylization and refine it accordingly in an iterative manner. For each refinement, we transit the error features across both the spatial and scale domain and invert the processed features into a residual image, with a network we call Error Transition Network (ETNet). The proposed model improves over the state-of-the-art methods with better semantic structures and more adaptive style pattern details. Various qualitative and quantitative experiments show that the key concept of both progressive strategy and error-correction leads to better results. Code and models are available at https://github.com/zhijieW94/ETNet.
Pair-wise Exchangeable Feature Extraction for Arbitrary Style Transfer
Nov 26, 2018
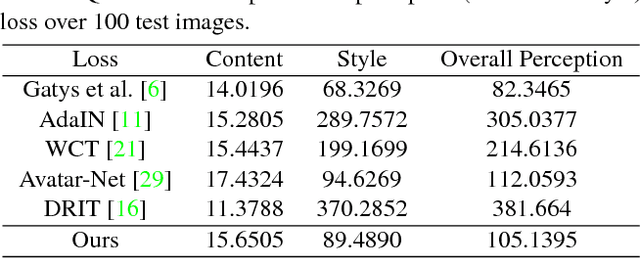
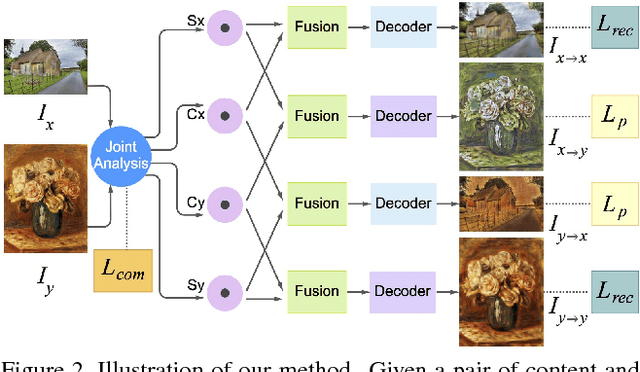
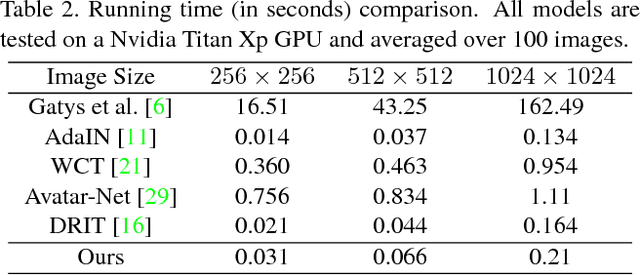
Style transfer has been an important topic in both computer vision and graphics. Gatys et al. first prove that deep features extracted by the pre-trained VGG network represent both content and style features of an image and hence, style transfer can be achieved through optimization in feature space. Huang et al. then show that real-time arbitrary style transfer can be done by simply aligning the mean and variance of each feature channel. In this paper, however, we argue that only aligning the global statistics of deep features cannot always guarantee a good style transfer. Instead, we propose to jointly analyze the input image pair and extract common/exchangeable style features between the two. Besides, a new fusion mode is developed for combining content and style information in feature space. Qualitative and quantitative experiments demonstrate the advantages of our approach.