 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffE2E: Rethinking End-to-End Driving with a Hybrid Action Diffusion and Supervised Policy
May 26, 2025End-to-end learning has emerged as a transformative paradigm in autonomous driving. However, the inherently multimodal nature of driving behaviors and the generalization challenges in long-tail scenarios remain critical obstacles to robust deployment. We propose DiffE2E, a diffusion-based end-to-end autonomous driving framework. This framework first performs multi-scale alignment of multi-sensor perception features through a hierarchical bidirectional cross-attention mechanism. It then introduces a novel class of hybrid diffusion-supervision decoders based on the Transformer architecture, and adopts a collaborative training paradigm that seamlessly integrates the strengths of both diffusion and supervised policy. DiffE2E models structured latent spaces, where diffusion captures the distribution of future trajectories and supervision enhances controllability and robustness. A global condition integration module enables deep fusion of perception features with high-level targets, significantly improving the quality of trajectory generation. Subsequently, a cross-attention mechanism facilitates efficient interaction between integrated features and hybrid latent variables, promoting the joint optimization of diffusion and supervision objectives for structured output generation, ultimately leading to more robust control. Experiments demonstrate that DiffE2E achieves state-of-the-art performance in both CARLA closed-loop evaluations and NAVSIM benchmarks. The proposed integrated diffusion-supervision policy offers a generalizable paradigm for hybrid action representation, with strong potential for extension to broader domains including embodied intelligence. More details and visualizations are available at \href{https://infinidrive.github.io/DiffE2E/}{project website}.
An Enhanced Low-Resolution Image Recognition Method for Traffic Environments
Sep 28, 2023



Currently, low-resolution image recognition is confronted with a significant challenge in the field of intelligent traffic perception. Compared to high-resolution images, low-resolution images suffer from small size, low quality, and lack of detail, leading to a notable decrease in the accuracy of traditional neural network recognition algorithms. The key to low-resolution image recognition lies in effective feature extraction. Therefore, this paper delves into the fundamental dimensions of residual modules and their impact on feature extraction and computational efficiency. Based on experiments, we introduce a dual-branch residual network structure that leverages the basic architecture of residual networks and a common feature subspace algorithm. Additionally, it incorporates the utilization of intermediate-layer features to enhance the accuracy of low-resolution image recognition. Furthermore, we employ knowledge distillation to reduce network parameters and computational overhead. Experimental results validate the effectiveness of this algorithm for low-resolution image recognition in traffic environments.
Holistic Transformer: A Joint Neural Network for Trajectory Prediction and Decision-Making of Autonomous Vehicles
Jun 17, 2022
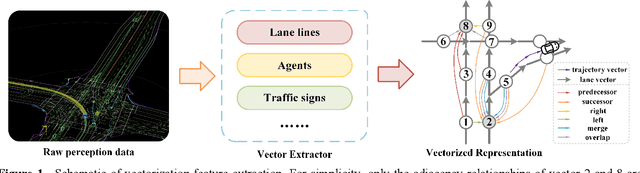

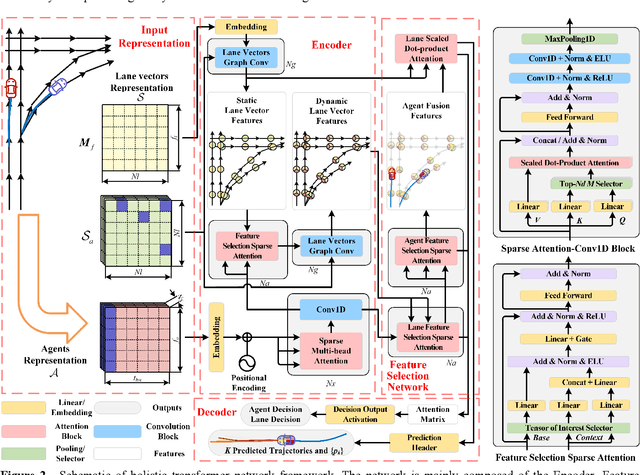
Trajectory prediction and behavioral decision-making are two important tasks for autonomous vehicles that require good understanding of the environmental context; behavioral decisions are better made by referring to the outputs of trajectory predictions. However, most current solutions perform these two tasks separately. Therefore, a joint neural network that combines multiple cues is proposed and named as the holistic transformer to predict trajectories and make behavioral decisions simultaneously. To better explore the intrinsic relationships between cues, the network uses existing knowledge and adopts three kinds of attention mechanisms: the sparse multi-head type for reducing noise impact, feature selection sparse type for optimally using partial prior knowledge, and multi-head with sigmoid activation type for optimally using posteriori knowledge. Compared with other trajectory prediction models, the proposed model has better comprehensive performance and good interpretability. Perceptual noise robustness experiments demonstrate that the proposed model has good noise robustness. Thus, simultaneous trajectory prediction and behavioral decision-making combining multiple cues can reduce computational costs and enhance semantic relationships between scenes and agents.