 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNodeSynth: Socially Aligned Synthetic Data for AI Evaluation
May 14, 2026Recent advancements in generative AI facilitate large-scale synthetic data generation for model evaluation. However, without targeted approaches, these datasets often lack the sociotechnical nuance required for sensitive domains. We introduce NodeSynth, an evidence-grounded methodology that generates socially relevant synthetic queries by leveraging a fine-tuned taxonomy generator (TaG) anchored in real-world evidence. Evaluated against four mainstream LLMs (e.g., Claude 4.5 Haiku), NodeSynth elicited failure rates up to five times higher than human-authored benchmarks. Ablation studies confirm that our granular taxonomic expansion significantly drives these failure rates, while independent validation reveals critical deficiencies in prominent guard models (e.g., Llama-Guard-3). We open-source our end-to-end research prototype and datasets to enable scalable, high-stakes model evaluation and targeted safety interventions (https://github.com/google-research/nodesynth).
When Valid Signals Fail: Regime Boundaries Between LLM Features and RL Trading Policies
Apr 13, 2026Can large language models (LLMs) generate continuous numerical features that improve reinforcement learning (RL) trading agents? We build a modular pipeline where a frozen LLM serves as a stateless feature extractor, transforming unstructured daily news and filings into a fixed-dimensional vector consumed by a downstream PPO agent. We introduce an automated prompt-optimization loop that treats the extraction prompt as a discrete hyperparameter and tunes it directly against the Information Coefficient - the Spearman rank correlation between predicted and realized returns - rather than NLP losses. The optimized prompt discovers genuinely predictive features (IC above 0.15 on held-out data). However, these valid intermediate representations do not automatically translate into downstream task performance: during a distribution shift caused by a macroeconomic shock, LLM-derived features add noise, and the augmented agent under-performs a price-only baseline. In a calmer test regime the agent recovers, yet macroeconomic state variables remain the most robust driver of policy improvement. Our findings highlight a gap between feature-level validity and policy-level robustness that parallels known challenges in transfer learning under distribution shift.
Incremental Sense Weight Training for the Interpretation of Contextualized Word Embeddings
Dec 18, 2019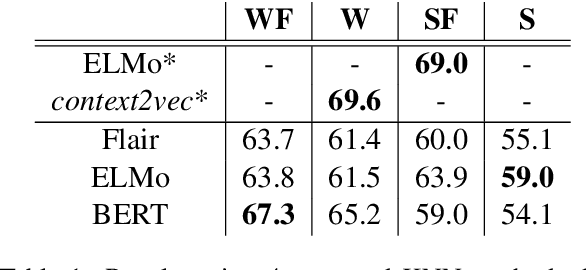
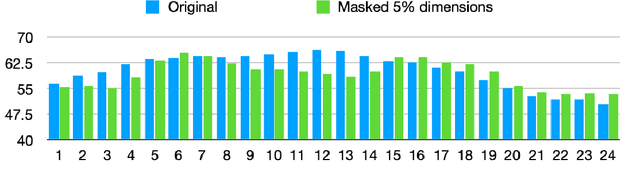
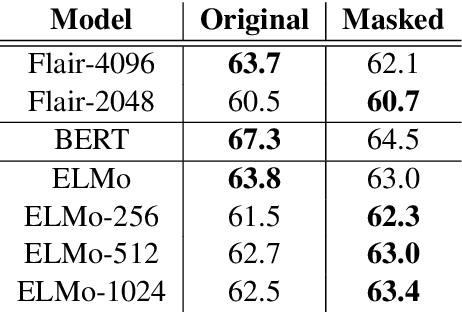
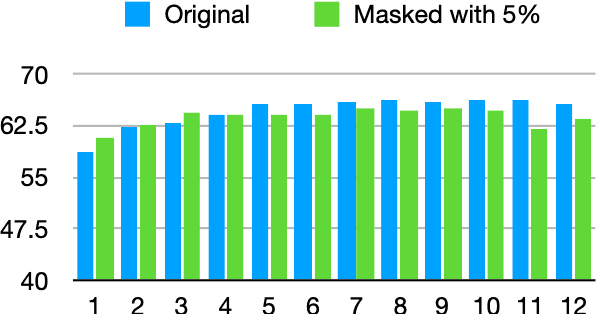
We present a novel online algorithm that learns the essence of each dimension in word embeddings by minimizing the within-group distance of contextualized embedding groups. Three state-of-the-art neural-based language models are used, Flair, ELMo, and BERT, to generate contextualized word embeddings such that different embeddings are generated for the same word type, which are grouped by their senses manually annotated in the SemCor dataset. We hypothesize that not all dimensions are equally important for downstream tasks so that our algorithm can detect unessential dimensions and discard them without hurting the performance. To verify this hypothesis, we first mask dimensions determined unessential by our algorithm, apply the masked word embeddings to a word sense disambiguation task (WSD), and compare its performance against the one achieved by the original embeddings. Several KNN approaches are experimented to establish strong baselines for WSD. Our results show that the masked word embeddings do not hurt the performance and can improve it by 3%. Our work can be used to conduct future research on the interpretability of contextualized embeddings.