 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning in Deterministic Systems with Value Function Generalization
Jul 06, 2016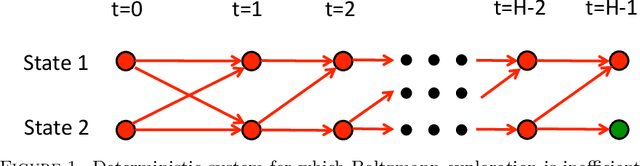
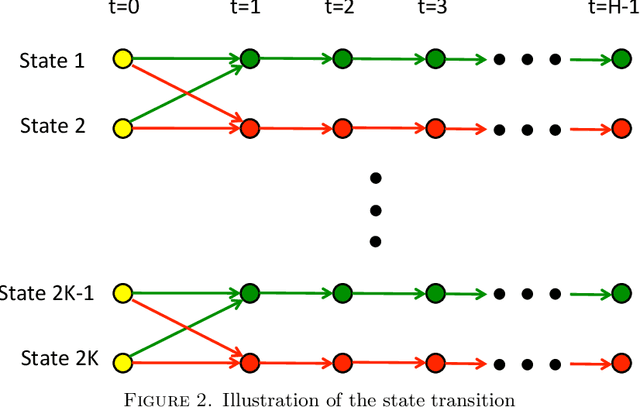
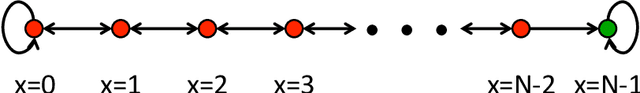
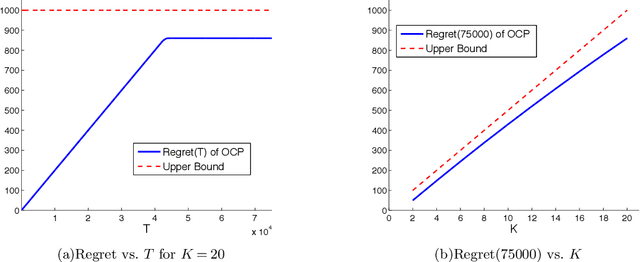
We consider the problem of reinforcement learning over episodes of a finite-horizon deterministic system and as a solution propose optimistic constraint propagation (OCP), an algorithm designed to synthesize efficient exploration and value function generalization. We establish that when the true value function lies within a given hypothesis class, OCP selects optimal actions over all but at most K episodes, where K is the eluder dimension of the given hypothesis class. We establish further efficiency and asymptotic performance guarantees that apply even if the true value function does not lie in the given hypothesis class, for the special case where the hypothesis class is the span of pre-specified indicator functions over disjoint sets. We also discuss the computational complexity of OCP and present computational results involving two illustrative examples.
Cascading Bandits for Large-Scale Recommendation Problems
Jun 30, 2016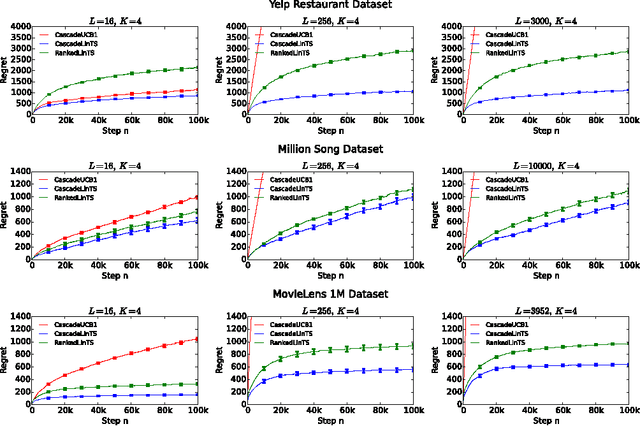
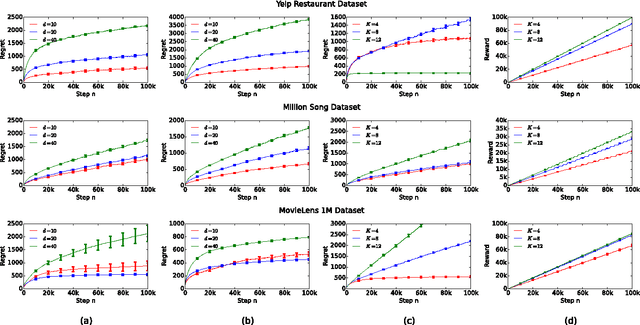
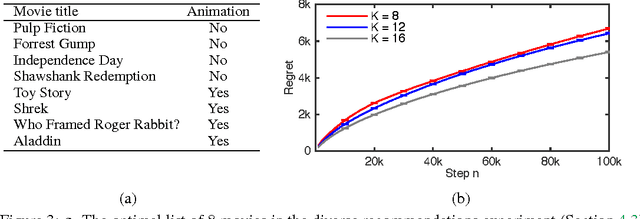
Most recommender systems recommend a list of items. The user examines the list, from the first item to the last, and often chooses the first attractive item and does not examine the rest. This type of user behavior can be modeled by the cascade model. In this work, we study cascading bandits, an online learning variant of the cascade model where the goal is to recommend $K$ most attractive items from a large set of $L$ candidate items. We propose two algorithms for solving this problem, which are based on the idea of linear generalization. The key idea in our solutions is that we learn a predictor of the attraction probabilities of items from their features, as opposing to learning the attraction probability of each item independently as in the existing work. This results in practical learning algorithms whose regret does not depend on the number of items $L$. We bound the regret of one algorithm and comprehensively evaluate the other on a range of recommendation problems. The algorithm performs well and outperforms all baselines.
DCM Bandits: Learning to Rank with Multiple Clicks
May 31, 2016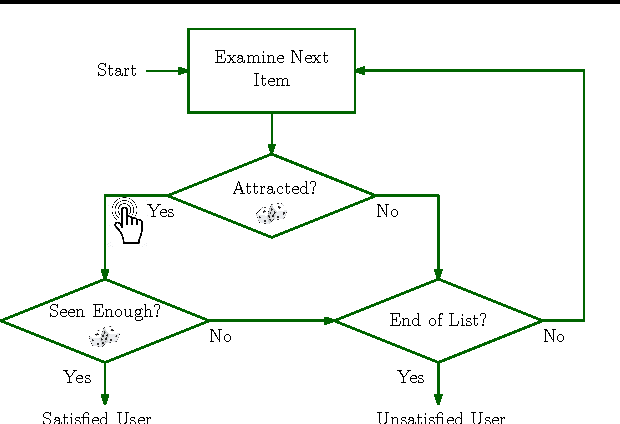
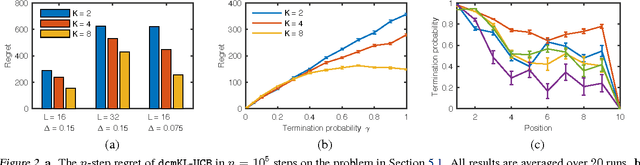
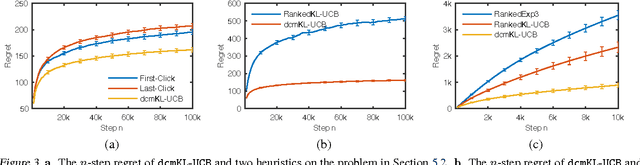
A search engine recommends to the user a list of web pages. The user examines this list, from the first page to the last, and clicks on all attractive pages until the user is satisfied. This behavior of the user can be described by the dependent click model (DCM). We propose DCM bandits, an online learning variant of the DCM where the goal is to maximize the probability of recommending satisfactory items, such as web pages. The main challenge of our learning problem is that we do not observe which attractive item is satisfactory. We propose a computationally-efficient learning algorithm for solving our problem, dcmKL-UCB; derive gap-dependent upper bounds on its regret under reasonable assumptions; and also prove a matching lower bound up to logarithmic factors. We evaluate our algorithm on synthetic and real-world problems, and show that it performs well even when our model is misspecified. This work presents the first practical and regret-optimal online algorithm for learning to rank with multiple clicks in a cascade-like click model.
Generalization and Exploration via Randomized Value Functions
Feb 15, 2016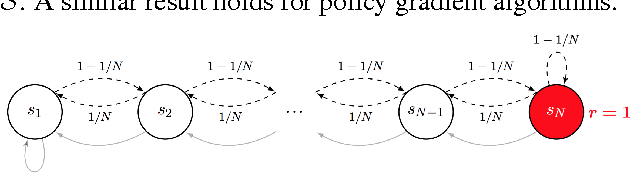
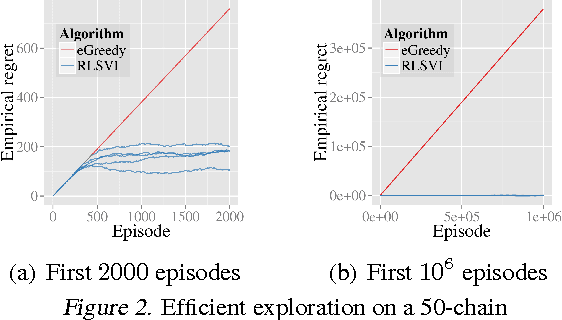
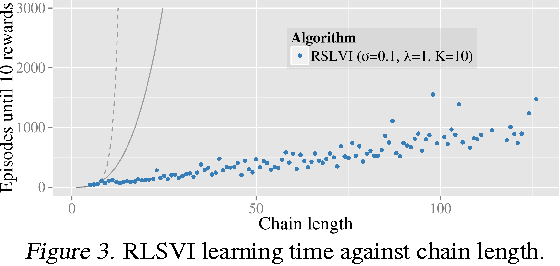
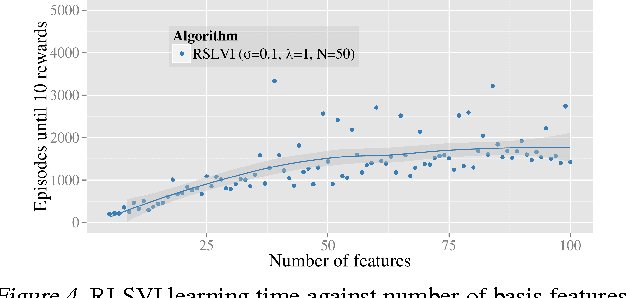
We propose randomized least-squares value iteration (RLSVI) -- a new reinforcement learning algorithm designed to explore and generalize efficiently via linearly parameterized value functions. We explain why versions of least-squares value iteration that use Boltzmann or epsilon-greedy exploration can be highly inefficient, and we present computational results that demonstrate dramatic efficiency gains enjoyed by RLSVI. Further, we establish an upper bound on the expected regret of RLSVI that demonstrates near-optimality in a tabula rasa learning context. More broadly, our results suggest that randomized value functions offer a promising approach to tackling a critical challenge in reinforcement learning: synthesizing efficient exploration and effective generalization.
Combinatorial Cascading Bandits
Nov 17, 2015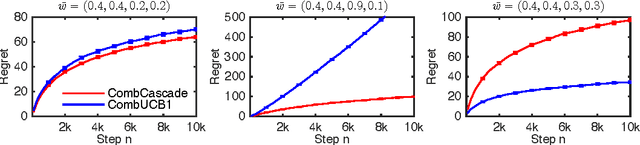
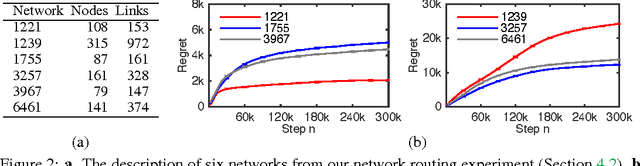
We propose combinatorial cascading bandits, a class of partial monitoring problems where at each step a learning agent chooses a tuple of ground items subject to constraints and receives a reward if and only if the weights of all chosen items are one. The weights of the items are binary, stochastic, and drawn independently of each other. The agent observes the index of the first chosen item whose weight is zero. This observation model arises in network routing, for instance, where the learning agent may only observe the first link in the routing path which is down, and blocks the path. We propose a UCB-like algorithm for solving our problems, CombCascade; and prove gap-dependent and gap-free upper bounds on its $n$-step regret. Our proofs build on recent work in stochastic combinatorial semi-bandits but also address two novel challenges of our setting, a non-linear reward function and partial observability. We evaluate CombCascade on two real-world problems and show that it performs well even when our modeling assumptions are violated. We also demonstrate that our setting requires a new learning algorithm.
Cascading Bandits: Learning to Rank in the Cascade Model
May 18, 2015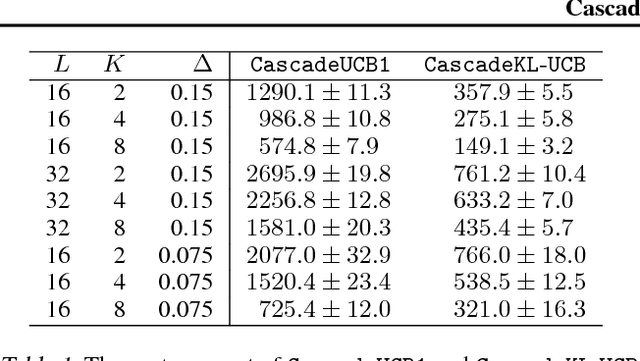
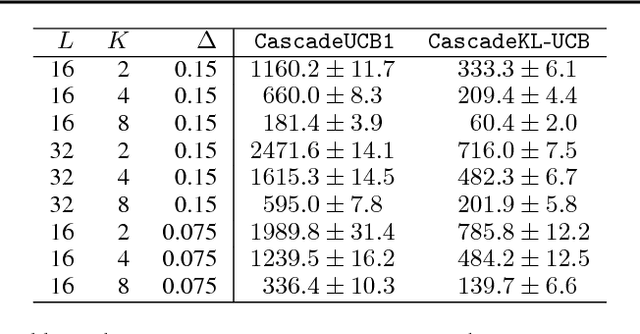
A search engine usually outputs a list of $K$ web pages. The user examines this list, from the first web page to the last, and chooses the first attractive page. This model of user behavior is known as the cascade model. In this paper, we propose cascading bandits, a learning variant of the cascade model where the objective is to identify $K$ most attractive items. We formulate our problem as a stochastic combinatorial partial monitoring problem. We propose two algorithms for solving it, CascadeUCB1 and CascadeKL-UCB. We also prove gap-dependent upper bounds on the regret of these algorithms and derive a lower bound on the regret in cascading bandits. The lower bound matches the upper bound of CascadeKL-UCB up to a logarithmic factor. We experiment with our algorithms on several problems. The algorithms perform surprisingly well even when our modeling assumptions are violated.
Tight Regret Bounds for Stochastic Combinatorial Semi-Bandits
Jan 27, 2015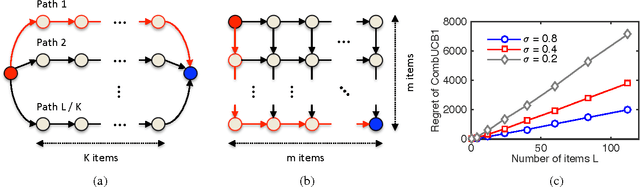
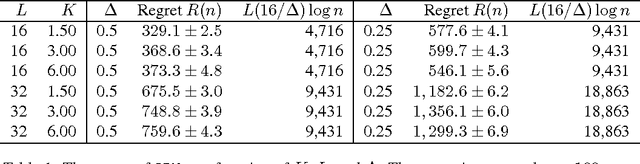
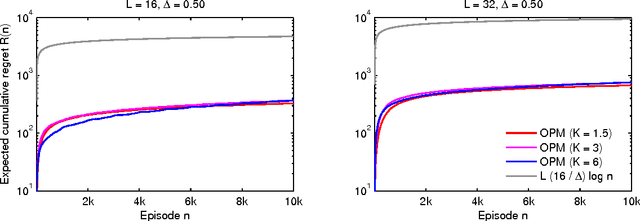
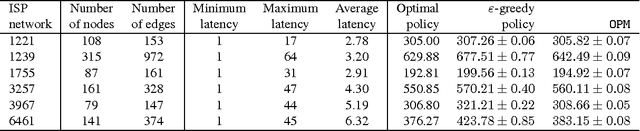
A stochastic combinatorial semi-bandit is an online learning problem where at each step a learning agent chooses a subset of ground items subject to constraints, and then observes stochastic weights of these items and receives their sum as a payoff. In this paper, we close the problem of computationally and sample efficient learning in stochastic combinatorial semi-bandits. In particular, we analyze a UCB-like algorithm for solving the problem, which is known to be computationally efficient; and prove $O(K L (1 / \Delta) \log n)$ and $O(\sqrt{K L n \log n})$ upper bounds on its $n$-step regret, where $L$ is the number of ground items, $K$ is the maximum number of chosen items, and $\Delta$ is the gap between the expected returns of the optimal and best suboptimal solutions. The gap-dependent bound is tight up to a constant factor and the gap-free bound is tight up to a polylogarithmic factor.
Learning to Act Greedily: Polymatroid Semi-Bandits
Nov 21, 2014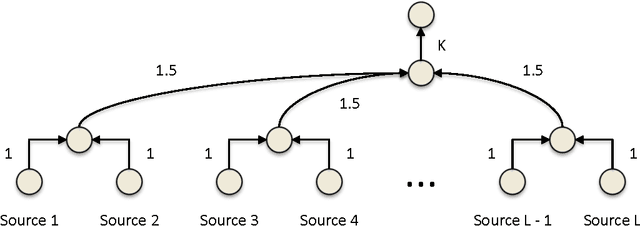
Many important optimization problems, such as the minimum spanning tree and minimum-cost flow, can be solved optimally by a greedy method. In this work, we study a learning variant of these problems, where the model of the problem is unknown and has to be learned by interacting repeatedly with the environment in the bandit setting. We formalize our learning problem quite generally, as learning how to maximize an unknown modular function on a known polymatroid. We propose a computationally efficient algorithm for solving our problem and bound its expected cumulative regret. Our gap-dependent upper bound is tight up to a constant and our gap-free upper bound is tight up to polylogarithmic factors. Finally, we evaluate our method on three problems and demonstrate that it is practical.
DUM: Diversity-Weighted Utility Maximization for Recommendations
Nov 13, 2014


The need for diversification of recommendation lists manifests in a number of recommender systems use cases. However, an increase in diversity may undermine the utility of the recommendations, as relevant items in the list may be replaced by more diverse ones. In this work we propose a novel method for maximizing the utility of the recommended items subject to the diversity of user's tastes, and show that an optimal solution to this problem can be found greedily. We evaluate the proposed method in two online user studies as well as in an offline analysis incorporating a number of evaluation metrics. The results of evaluations show the superiority of our method over a number of baselines.
Optimal Demand Response Using Device Based Reinforcement Learning
Jun 28, 2014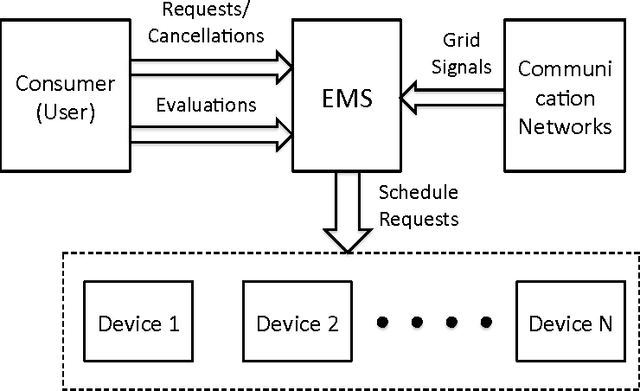
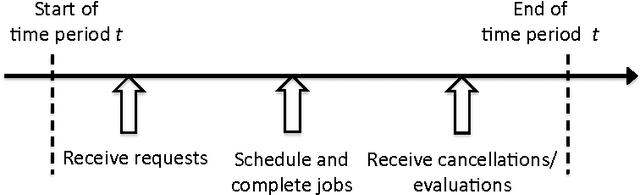
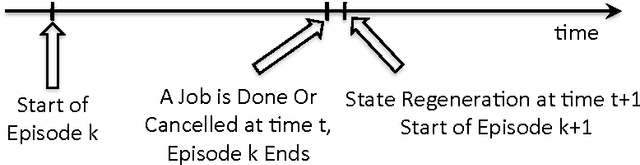
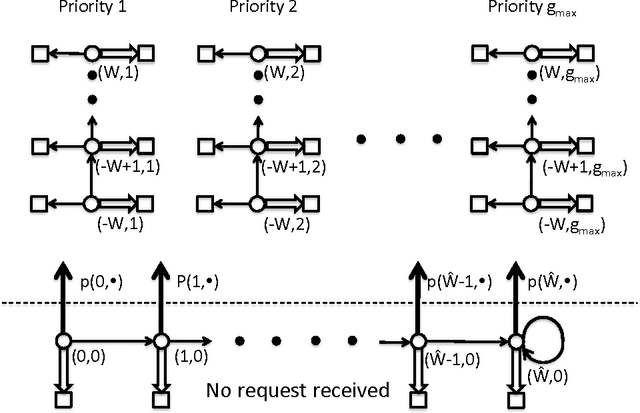
Demand response (DR) for residential and small commercial buildings is estimated to account for as much as 65% of the total energy savings potential of DR, and previous work shows that a fully automated Energy Management System (EMS) is a necessary prerequisite to DR in these areas. In this paper, we propose a novel EMS formulation for DR problems in these sectors. Specifically, we formulate a fully automated EMS's rescheduling problem as a reinforcement learning (RL) problem, and argue that this RL problem can be approximately solved by decomposing it over device clusters. Compared with existing formulations, our new formulation (1) does not require explicitly modeling the user's dissatisfaction on job rescheduling, (2) enables the EMS to self-initiate jobs, (3) allows the user to initiate more flexible requests and (4) has a computational complexity linear in the number of devices. We also demonstrate the simulation results of applying Q-learning, one of the most popular and classical RL algorithms, to a representative example.