 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Epinets against Distributional Shifts
Jul 01, 2022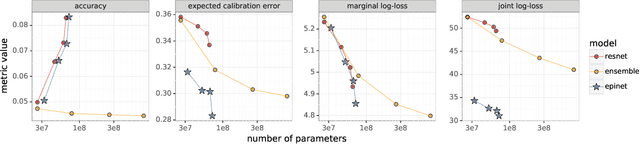
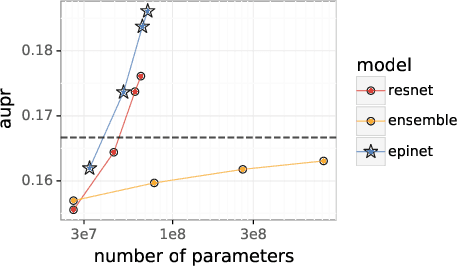
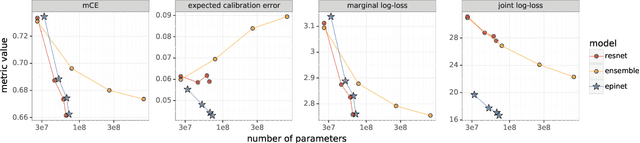
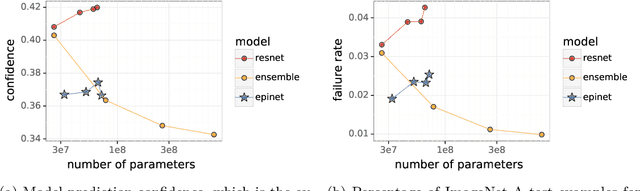
Recent work introduced the epinet as a new approach to uncertainty modeling in deep learning. An epinet is a small neural network added to traditional neural networks, which, together, can produce predictive distributions. In particular, using an epinet can greatly improve the quality of joint predictions across multiple inputs, a measure of how well a neural network knows what it does not know. In this paper, we examine whether epinets can offer similar advantages under distributional shifts. We find that, across ImageNet-A/O/C, epinets generally improve robustness metrics. Moreover, these improvements are more significant than those afforded by even very large ensembles at orders of magnitude lower computational costs. However, these improvements are relatively small compared to the outstanding issues in distributionally-robust deep learning. Epinets may be a useful tool in the toolbox, but they are far from the complete solution.
Ensembles for Uncertainty Estimation: Benefits of Prior Functions and Bootstrapping
Jun 08, 2022
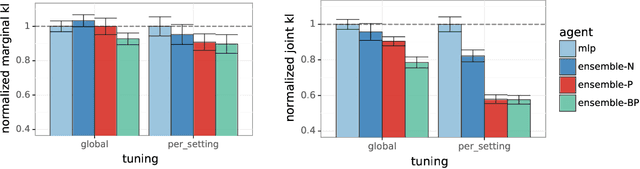


In machine learning, an agent needs to estimate uncertainty to efficiently explore and adapt and to make effective decisions. A common approach to uncertainty estimation maintains an ensemble of models. In recent years, several approaches have been proposed for training ensembles, and conflicting views prevail with regards to the importance of various ingredients of these approaches. In this paper, we aim to address the benefits of two ingredients -- prior functions and bootstrapping -- which have come into question. We show that prior functions can significantly improve an ensemble agent's joint predictions across inputs and that bootstrapping affords additional benefits if the signal-to-noise ratio varies across inputs. Our claims are justified by both theoretical and experimental results.
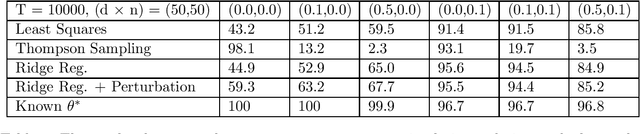
An Analysis of Ensemble Sampling
Mar 02, 2022Ensemble sampling serves as a practical approximation to Thompson sampling when maintaining an exact posterior distribution over model parameters is computationally intractable. In this paper, we establish a Bayesian regret bound that ensures desirable behavior when ensemble sampling is applied to the linear bandit problem. This represents the first rigorous regret analysis of ensemble sampling and is made possible by leveraging information-theoretic concepts and novel analytic techniques that may prove useful beyond the scope of this paper.
Evaluating High-Order Predictive Distributions in Deep Learning
Feb 28, 2022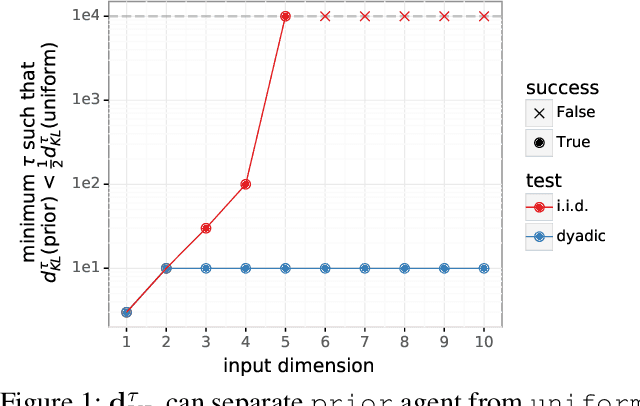
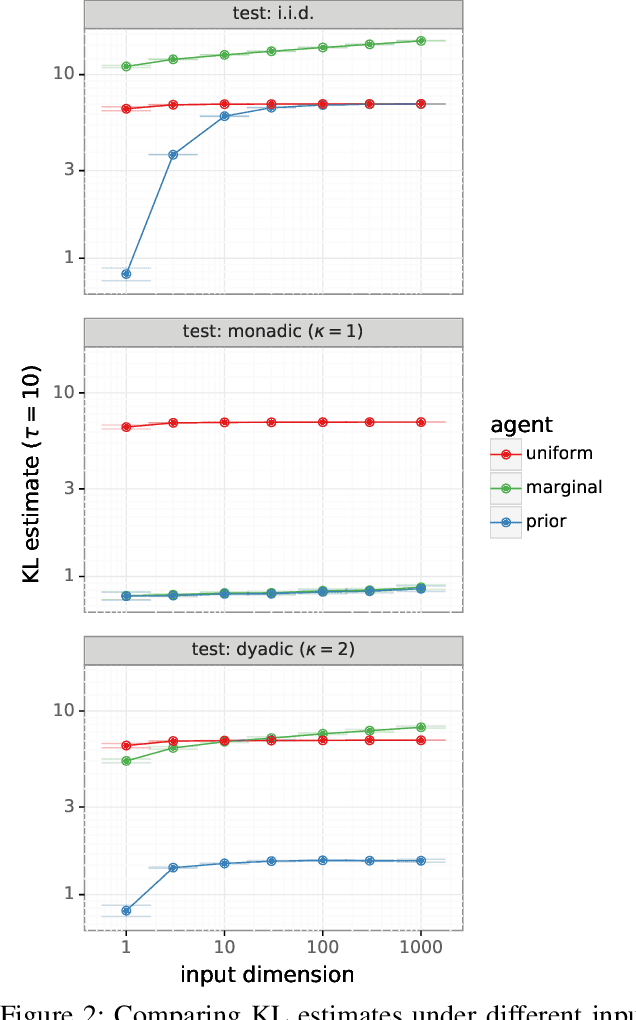
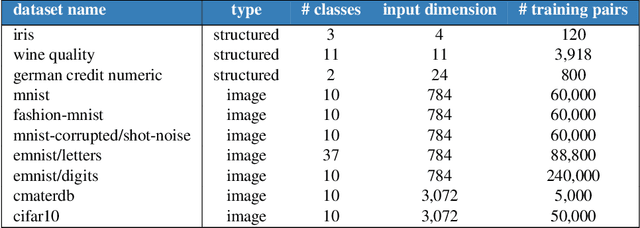
Most work on supervised learning research has focused on marginal predictions. In decision problems, joint predictive distributions are essential for good performance. Previous work has developed methods for assessing low-order predictive distributions with inputs sampled i.i.d. from the testing distribution. With low-dimensional inputs, these methods distinguish agents that effectively estimate uncertainty from those that do not. We establish that the predictive distribution order required for such differentiation increases greatly with input dimension, rendering these methods impractical. To accommodate high-dimensional inputs, we introduce \textit{dyadic sampling}, which focuses on predictive distributions associated with random \textit{pairs} of inputs. We demonstrate that this approach efficiently distinguishes agents in high-dimensional examples involving simple logistic regression as well as complex synthetic and empirical data.
Evaluating Predictive Distributions: Does Bayesian Deep Learning Work?
Oct 09, 2021
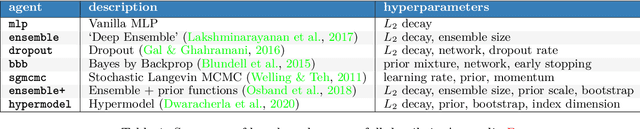
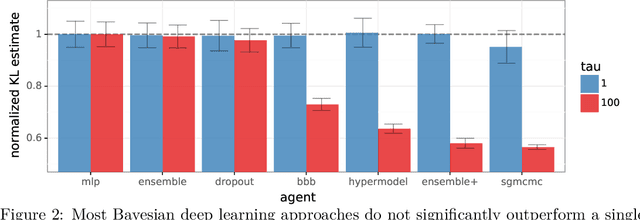
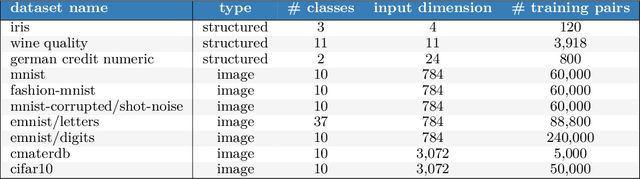
Posterior predictive distributions quantify uncertainties ignored by point estimates. This paper introduces \textit{The Neural Testbed}, which provides tools for the systematic evaluation of agents that generate such predictions. Crucially, these tools assess not only the quality of marginal predictions per input, but also joint predictions given many inputs. Joint distributions are often critical for useful uncertainty quantification, but they have been largely overlooked by the Bayesian deep learning community. We benchmark several approaches to uncertainty estimation using a neural-network-based data generating process. Our results reveal the importance of evaluation beyond marginal predictions. Further, they reconcile sources of confusion in the field, such as why Bayesian deep learning approaches that generate accurate marginal predictions perform poorly in sequential decision tasks, how incorporating priors can be helpful, and what roles epistemic versus aleatoric uncertainty play when evaluating performance. We also present experiments on real-world challenge datasets, which show a high correlation with testbed results, and that the importance of evaluating joint predictive distributions carries over to real data. As part of this effort, we opensource The Neural Testbed, including all implementations from this paper.
Evaluating Probabilistic Inference in Deep Learning: Beyond Marginal Predictions
Jul 20, 2021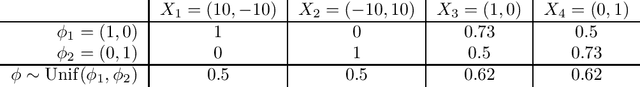
A fundamental challenge for any intelligent system is prediction: given some inputs $X_1,..,X_\tau$ can you predict outcomes $Y_1,.., Y_\tau$. The KL divergence $\mathbf{d}_{\mathrm{KL}}$ provides a natural measure of prediction quality, but the majority of deep learning research looks only at the marginal predictions per input $X_t$. In this technical report we propose a scoring rule $\mathbf{d}_{\mathrm{KL}}^\tau$, parameterized by $\tau \in \mathcal{N}$ that evaluates the joint predictions at $\tau$ inputs simultaneously. We show that the commonly-used $\tau=1$ can be insufficient to drive good decisions in many settings of interest. We also show that, as $\tau$ grows, performing well according to $\mathbf{d}_{\mathrm{KL}}^\tau$ recovers universal guarantees for any possible decision. Finally, we provide problem-dependent guidance on the scale of $\tau$ for which our score provides sufficient guarantees for good performance.
Epistemic Neural Networks
Jul 19, 2021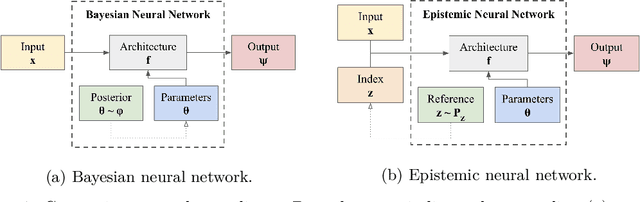
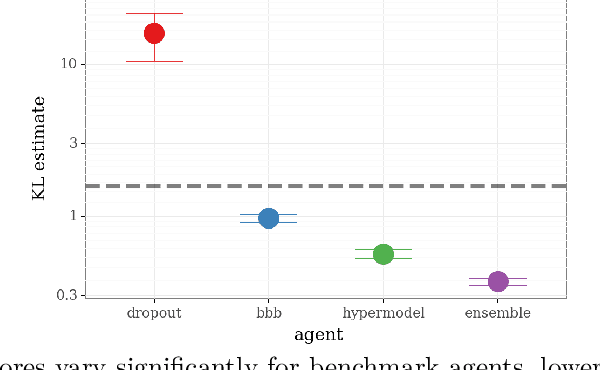
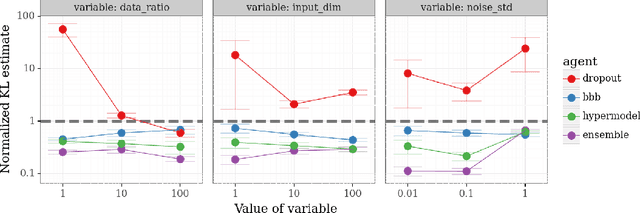
We introduce the \textit{epistemic neural network} (ENN) as an interface for uncertainty modeling in deep learning. All existing approaches to uncertainty modeling can be expressed as ENNs, and any ENN can be identified with a Bayesian neural network. However, this new perspective provides several promising directions for future research. Where prior work has developed probabilistic inference tools for neural networks; we ask instead, `which neural networks are suitable as tools for probabilistic inference?'. We propose a clear and simple metric for progress in ENNs: the KL-divergence with respect to a target distribution. We develop a computational testbed based on inference in a neural network Gaussian process and release our code as a benchmark at \url{https://github.com/deepmind/enn}. We evaluate several canonical approaches to uncertainty modeling in deep learning, and find they vary greatly in their performance. We provide insight to the sensitivity of these results and show that our metric is highly correlated with performance in sequential decision problems. Finally, we provide indications that new ENN architectures can improve performance in both the statistical quality and computational cost.
Joint Online Learning and Decision-making via Dual Mirror Descent
Apr 20, 2021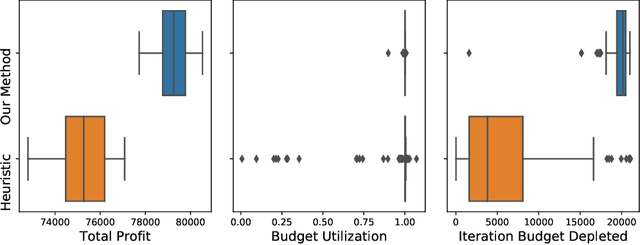
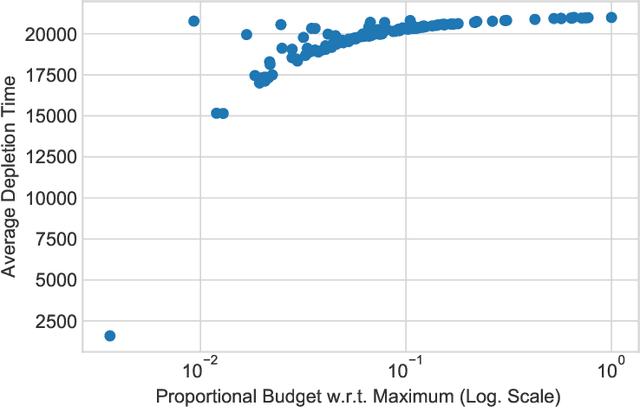
We consider an online revenue maximization problem over a finite time horizon subject to lower and upper bounds on cost. At each period, an agent receives a context vector sampled i.i.d. from an unknown distribution and needs to make a decision adaptively. The revenue and cost functions depend on the context vector as well as some fixed but possibly unknown parameter vector to be learned. We propose a novel offline benchmark and a new algorithm that mixes an online dual mirror descent scheme with a generic parameter learning process. When the parameter vector is known, we demonstrate an $O(\sqrt{T})$ regret result as well an $O(\sqrt{T})$ bound on the possible constraint violations. When the parameter is not known and must be learned, we demonstrate that the regret and constraint violations are the sums of the previous $O(\sqrt{T})$ terms plus terms that directly depend on the convergence of the learning process.
Reinforcement Learning, Bit by Bit
Mar 14, 2021

Reinforcement learning agents have demonstrated remarkable achievements in simulated environments. Data efficiency poses an impediment to carrying this success over to real environments. The design of data-efficient agents calls for a deeper understanding of information acquisition and representation. We develop concepts and establish a regret bound that together offer principled guidance. The bound sheds light on questions of what information to seek, how to seek that information, and it what information to retain. To illustrate concepts, we design simple agents that build on them and present computational results that demonstrate improvements in data efficiency.
Neural Contextual Bandits with Deep Representation and Shallow Exploration
Dec 03, 2020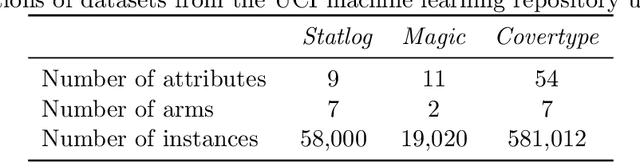
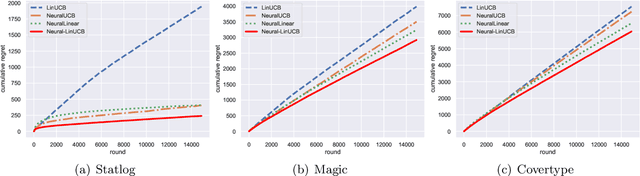
We study a general class of contextual bandits, where each context-action pair is associated with a raw feature vector, but the reward generating function is unknown. We propose a novel learning algorithm that transforms the raw feature vector using the last hidden layer of a deep ReLU neural network (deep representation learning), and uses an upper confidence bound (UCB) approach to explore in the last linear layer (shallow exploration). We prove that under standard assumptions, our proposed algorithm achieves $\tilde{O}(\sqrt{T})$ finite-time regret, where $T$ is the learning time horizon. Compared with existing neural contextual bandit algorithms, our approach is computationally much more efficient since it only needs to explore in the last layer of the deep neural network.