 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adaptive Embedding Considering Incremental Class
Aug 31, 2020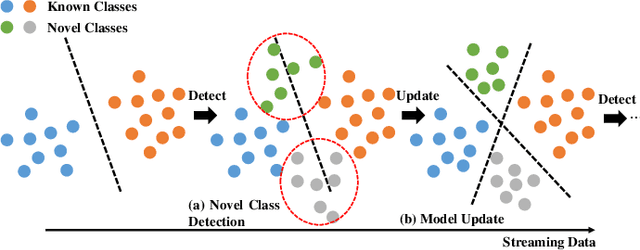

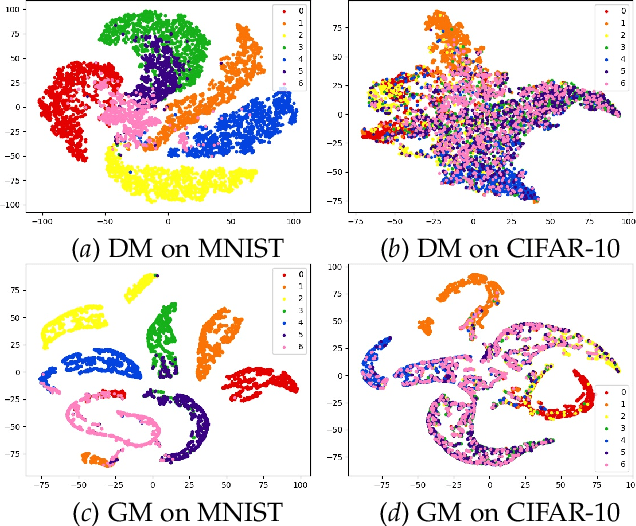
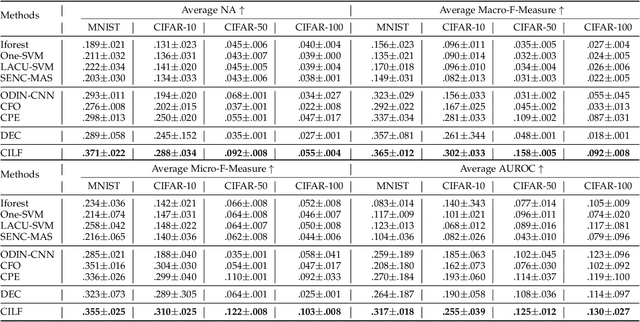
Class-Incremental Learning (CIL) aims to train a reliable model with the streaming data, which emerges unknown classes sequentially. Different from traditional closed set learning, CIL has two main challenges: 1) Novel class detection. The initial training data only contains incomplete classes, and streaming test data will accept unknown classes. Therefore, the model needs to not only accurately classify known classes, but also effectively detect unknown classes; 2) Model expansion. After the novel classes are detected, the model needs to be updated without re-training using entire previous data. However, traditional CIL methods have not fully considered these two challenges, first, they are always restricted to single novel class detection each phase and embedding confusion caused by unknown classes. Besides, they also ignore the catastrophic forgetting of known categories in model update. To this end, we propose a Class-Incremental Learning without Forgetting (CILF) framework, which aims to learn adaptive embedding for processing novel class detection and model update in a unified framework. In detail, CILF designs to regularize classification with decoupled prototype based loss, which can improve the intra-class and inter-class structure significantly, and acquire a compact embedding representation for novel class detection in result. Then, CILF employs a learnable curriculum clustering operator to estimate the number of semantic clusters via fine-tuning the learned network, in which curriculum operator can adaptively learn the embedding in self-taught form. Therefore, CILF can detect multiple novel classes and mitigate the embedding confusion problem. Last, with the labeled streaming test data, CILF can update the network with robust regularization to mitigate the catastrophic forgetting. Consequently, CILF is able to iteratively perform novel class detection and model update.
S2OSC: A Holistic Semi-Supervised Approach for Open Set Classification
Aug 11, 2020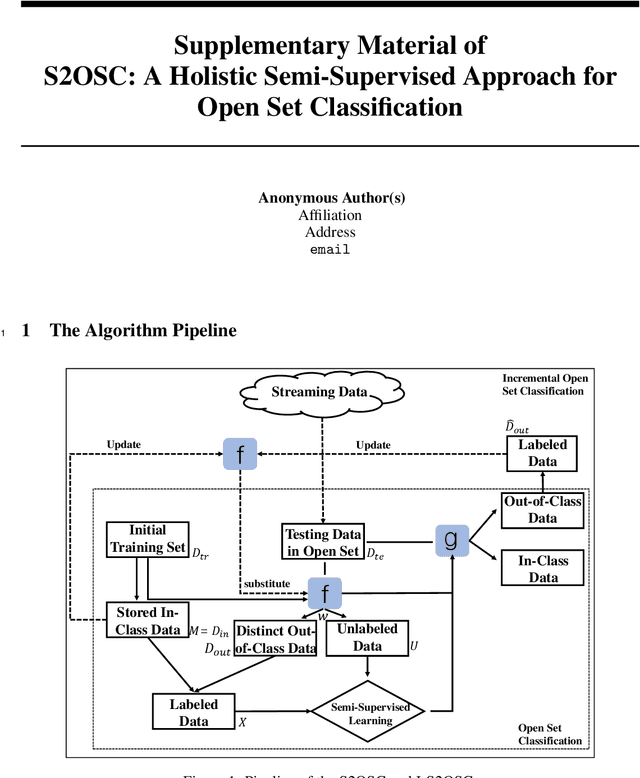
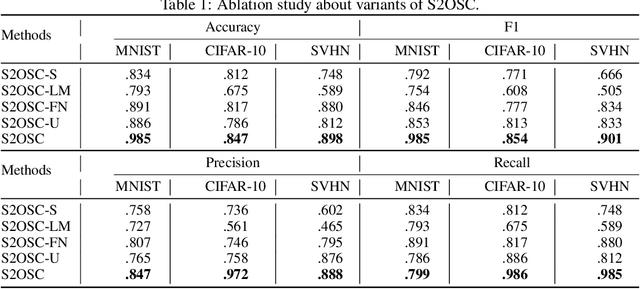
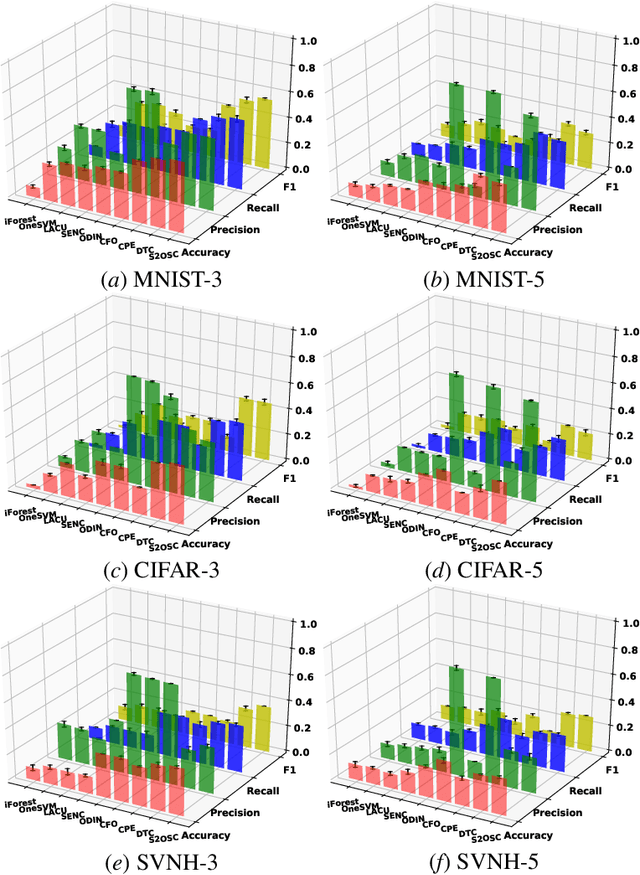
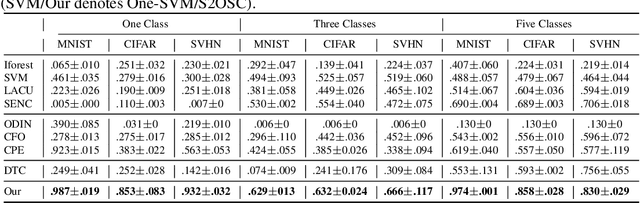
Open set classification (OSC) tackles the problem of determining whether the data are in-class or out-of-class during inference, when only provided with a set of in-class examples at training time. Traditional OSC methods usually train discriminative or generative models with in-class data, then utilize the pre-trained models to classify test data directly. However, these methods always suffer from embedding confusion problem, i.e., partial out-of-class instances are mixed with in-class ones of similar semantics, making it difficult to classify. To solve this problem, we unify semi-supervised learning to develop a novel OSC algorithm, S2OSC, that incorporates out-of-class instances filtering and model re-training in a transductive manner. In detail, given a pool of newly coming test data, S2OSC firstly filters distinct out-of-class instances using the pre-trained model, and annotates super-class for them. Then, S2OSC trains a holistic classification model by combing in-class and out-of-class labeled data and remaining unlabeled test data in semi-supervised paradigm, which also integrates pre-trained model for knowledge distillation to further separate mixed instances. Despite its simplicity, the experimental results show that S2OSC achieves state-of-the-art performance across a variety of OSC tasks, including 85.4% of F1 on CIFAR-10 with only 300 pseudo-labels. We also demonstrate how S2OSC can be expanded to incremental OSC setting effectively with streaming data.