 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing Task-Specified Compliance Bounds for Humanoids via Anisotropic Lipschitz-Constrained Policies
Mar 17, 2026Reinforcement learning (RL) has demonstrated substantial potential for humanoid bipedal locomotion and the control of complex motions. To cope with oscillations and impacts induced by environmental interactions, compliant control is widely regarded as an effective remedy. However, the model-free nature of RL makes it difficult to impose task-specified and quantitatively verifiable compliance objectives, and classical model-based stiffness designs are not directly applicable. Lipschitz-Constrained Policies (LCP), which regularize the local sensitivity of a policy via gradient penalties, have recently been used to smooth humanoid motions. Nevertheless, existing LCP-based methods typically employ a single scalar Lipschitz budget and lack an explicit connection to physically meaningful compliance specifications in real-world systems. In this study, we propose an anisotropic Lipschitz-constrained policy (ALCP) that maps a task-space stiffness upper bound to a state-dependent Lipschitz-style constraint on the policy Jacobian. The resulting constraint is enforced during RL training via a hinge-squared spectral-norm penalty, preserving physical interpretability while enabling direction-dependent compliance. Experiments on humanoid robots show that ALCP improves locomotion stability and impact robustness, while reducing oscillations and energy usage.
Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
Feb 03, 2026Reinforcement learning has emerged as a principled post-training paradigm for Temporal Video Grounding (TVG) due to its on-policy optimization, yet existing GRPO-based methods remain fundamentally constrained by sparse reward signals and substantial computational overhead. We propose Video-OPD, an efficient post-training framework for TVG inspired by recent advances in on-policy distillation. Video-OPD optimizes trajectories sampled directly from the current policy, thereby preserving alignment between training and inference distributions, while a frontier teacher supplies dense, token-level supervision via a reverse KL divergence objective. This formulation preserves the on-policy property critical for mitigating distributional shift, while converting sparse, episode-level feedback into fine-grained, step-wise learning signals. Building on Video-OPD, we introduce Teacher-Validated Disagreement Focusing (TVDF), a lightweight training curriculum that iteratively prioritizes trajectories that are both teacher-reliable and maximally informative for the student, thereby improving training efficiency. Empirical results demonstrate that Video-OPD consistently outperforms GRPO while achieving substantially faster convergence and lower computational cost, establishing on-policy distillation as an effective alternative to conventional reinforcement learning for TVG.
Consistent Scale Normalization for Object Recognition
Aug 20, 2019
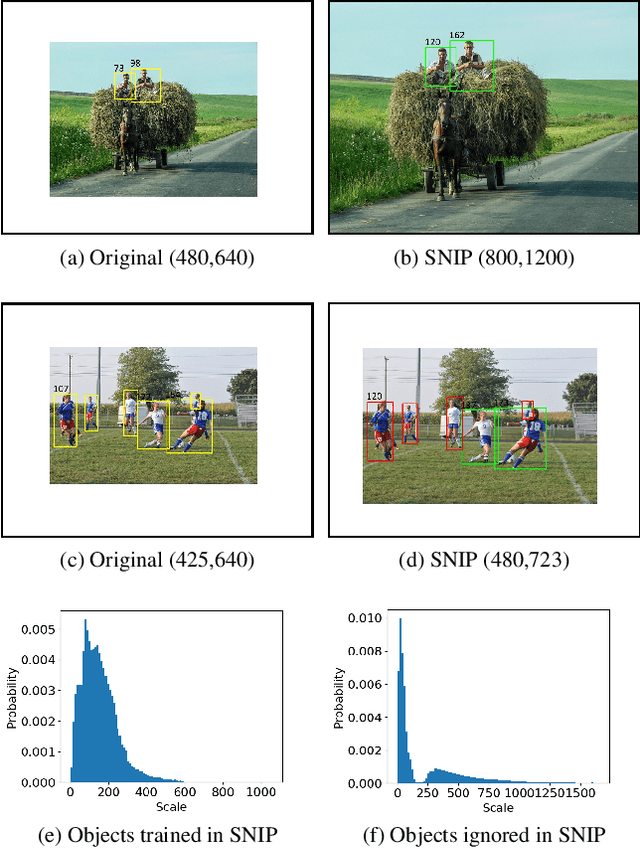

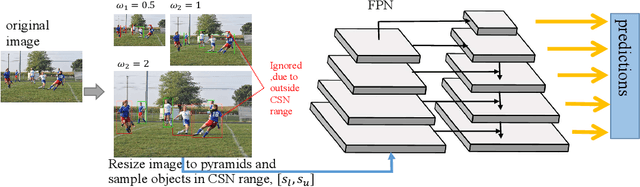
Scale variation remains a challenge problem for object detection. Common paradigms usually adopt multi-scale training & testing (image pyramid) or FPN (feature pyramid network) to process objects in wide scale range. However, multi-scale methods aggravate more variation of scale that even deep convolution neural networks with FPN cannot handle well. In this work, we propose an innovative paradigm called Consistent Scale Normalization (CSN) to resolve above problem. CSN compresses the scale space of objects into a consistent range (CSN range), in both training and testing phase. This reassures problem of scale variation fundamentally, and reduces the difficulty for network learning. Experiments show that CSN surpasses multi-scale counterpart significantly for object detection, instance segmentation and multi-task human pose estimation, on several architectures. On COCO test-dev, our single model based on CSN achieves 46.5 mAP with a ResNet-101 backbone, which is among the state-of-the-art (SOTA) candidates for object detection.