 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToy Models of Superposition
Sep 21, 2022Neural networks often pack many unrelated concepts into a single neuron - a puzzling phenomenon known as 'polysemanticity' which makes interpretability much more challenging. This paper provides a toy model where polysemanticity can be fully understood, arising as a result of models storing additional sparse features in "superposition." We demonstrate the existence of a phase change, a surprising connection to the geometry of uniform polytopes, and evidence of a link to adversarial examples. We also discuss potential implications for mechanistic interpretability.
Scaling Laws and Interpretability of Learning from Repeated Data
May 21, 2022
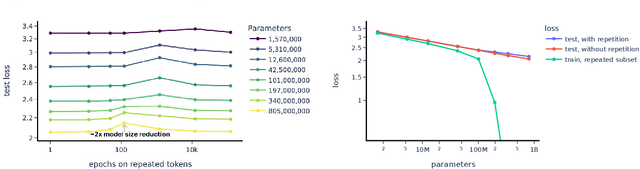
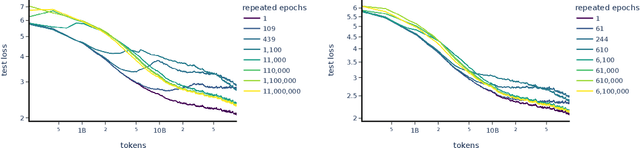
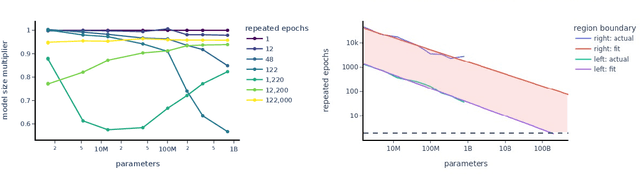
Recent large language models have been trained on vast datasets, but also often on repeated data, either intentionally for the purpose of upweighting higher quality data, or unintentionally because data deduplication is not perfect and the model is exposed to repeated data at the sentence, paragraph, or document level. Some works have reported substantial negative performance effects of this repeated data. In this paper we attempt to study repeated data systematically and to understand its effects mechanistically. To do this, we train a family of models where most of the data is unique but a small fraction of it is repeated many times. We find a strong double descent phenomenon, in which repeated data can lead test loss to increase midway through training. A predictable range of repetition frequency leads to surprisingly severe degradation in performance. For instance, performance of an 800M parameter model can be degraded to that of a 2x smaller model (400M params) by repeating 0.1% of the data 100 times, despite the other 90% of the training tokens remaining unique. We suspect there is a range in the middle where the data can be memorized and doing so consumes a large fraction of the model's capacity, and this may be where the peak of degradation occurs. Finally, we connect these observations to recent mechanistic interpretability work - attempting to reverse engineer the detailed computations performed by the model - by showing that data repetition disproportionately damages copying and internal structures associated with generalization, such as induction heads, providing a possible mechanism for the shift from generalization to memorization. Taken together, these results provide a hypothesis for why repeating a relatively small fraction of data in large language models could lead to disproportionately large harms to performance.
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Apr 12, 2022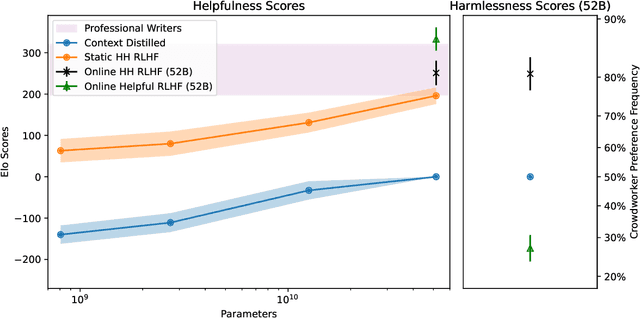
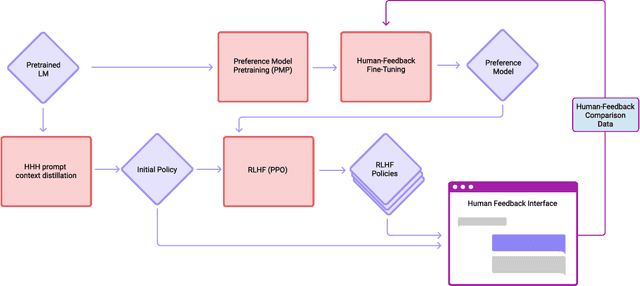
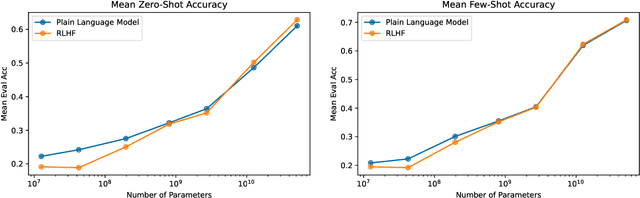
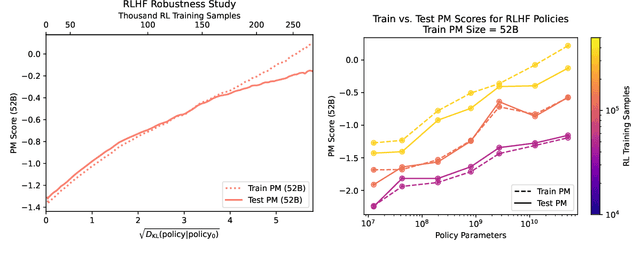
We apply preference modeling and reinforcement learning from human feedback (RLHF) to finetune language models to act as helpful and harmless assistants. We find this alignment training improves performance on almost all NLP evaluations, and is fully compatible with training for specialized skills such as python coding and summarization. We explore an iterated online mode of training, where preference models and RL policies are updated on a weekly cadence with fresh human feedback data, efficiently improving our datasets and models. Finally, we investigate the robustness of RLHF training, and identify a roughly linear relation between the RL reward and the square root of the KL divergence between the policy and its initialization. Alongside our main results, we perform peripheral analyses on calibration, competing objectives, and the use of OOD detection, compare our models with human writers, and provide samples from our models using prompts appearing in recent related work.
A General Language Assistant as a Laboratory for Alignment
Dec 09, 2021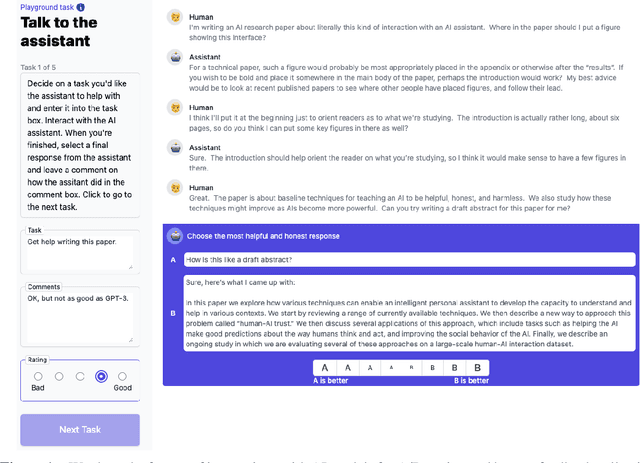
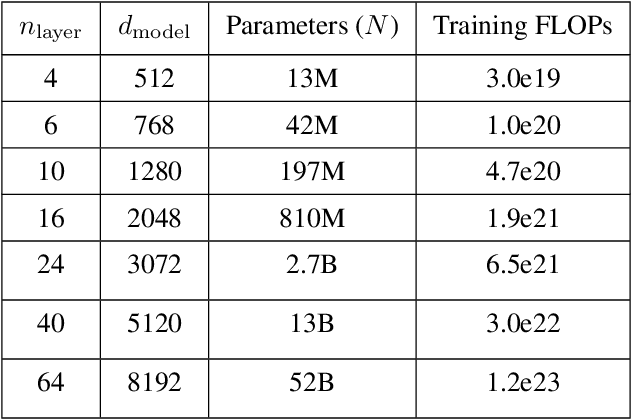
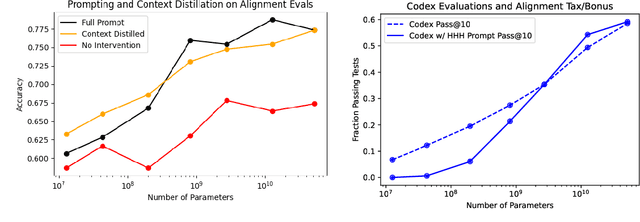
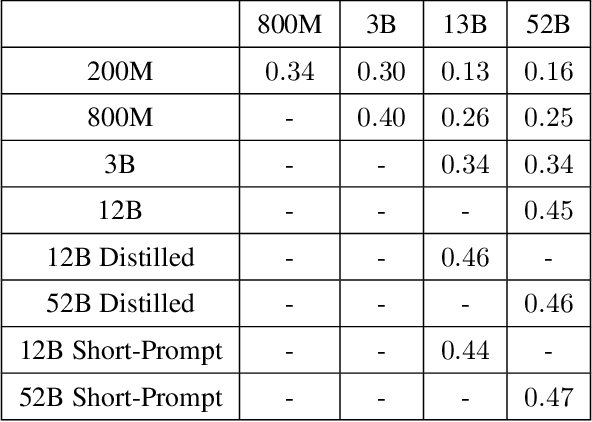
Given the broad capabilities of large language models, it should be possible to work towards a general-purpose, text-based assistant that is aligned with human values, meaning that it is helpful, honest, and harmless. As an initial foray in this direction we study simple baseline techniques and evaluations, such as prompting. We find that the benefits from modest interventions increase with model size, generalize to a variety of alignment evaluations, and do not compromise the performance of large models. Next we investigate scaling trends for several training objectives relevant to alignment, comparing imitation learning, binary discrimination, and ranked preference modeling. We find that ranked preference modeling performs much better than imitation learning, and often scales more favorably with model size. In contrast, binary discrimination typically performs and scales very similarly to imitation learning. Finally we study a `preference model pre-training' stage of training, with the goal of improving sample efficiency when finetuning on human preferences.