 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling and Transferring Knowledge via cGAN-generated Samples for Image Classification and Regression
May 01, 2021
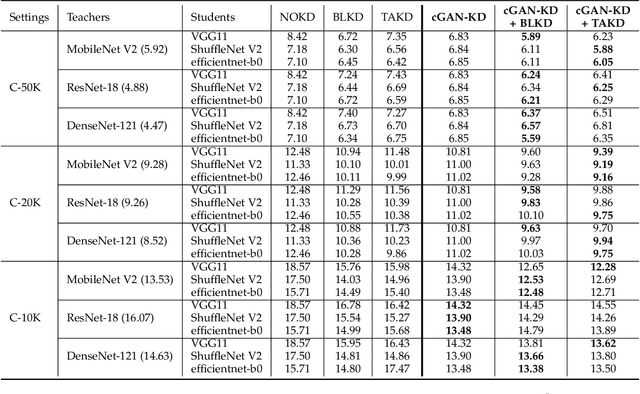
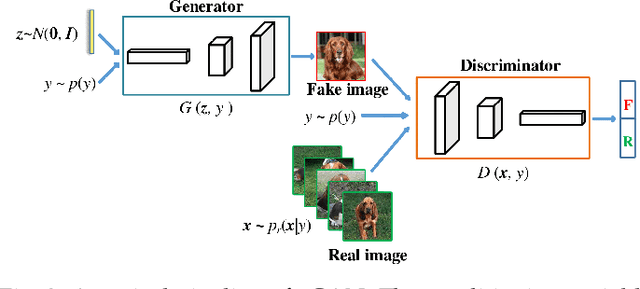
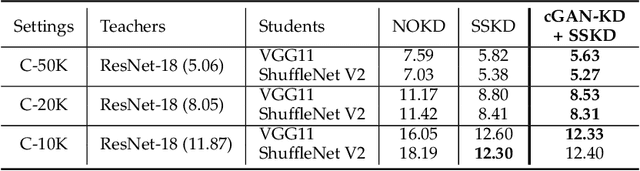
Knowledge distillation (KD) has been actively studied for image classification tasks in deep learning, aiming to improve the performance of a student model based on the knowledge from a teacher model. However, there have been very few efforts for applying KD in image regression with a scalar response, and there is no KD method applicable to both tasks. Moreover, existing KD methods often require a practitioner to carefully choose or adjust the teacher and student architectures, making these methods less scalable in practice. Furthermore, although KD is usually conducted in scenarios with limited labeled data, very few techniques are developed to alleviate such data insufficiency. To solve the above problems in an all-in-one manner, we propose in this paper a unified KD framework based on conditional generative adversarial networks (cGANs), termed cGAN-KD. Fundamentally different from existing KD methods, cGAN-KD distills and transfers knowledge from a teacher model to a student model via cGAN-generated samples. This unique mechanism makes cGAN-KD suitable for both classification and regression tasks, compatible with other KD methods, and insensitive to the teacher and student architectures. Also, benefiting from the recent advances in cGAN methodology and our specially designed subsampling and filtering procedures, cGAN-KD also performs well when labeled data are scarce. An error bound of a student model trained in the cGAN-KD framework is derived in this work, which theoretically explains why cGAN-KD takes effect and guides the implementation of cGAN-KD in practice. Extensive experiments on CIFAR-10 and Tiny-ImageNet show that we can incorporate state-of-the-art KD methods into the cGAN-KD framework to reach a new state of the art. Also, experiments on RC-49 and UTKFace demonstrate the effectiveness of cGAN-KD in image regression tasks, where existing KD methods are inapplicable.
Multi-view 3D Reconstruction with Transformer
Mar 24, 2021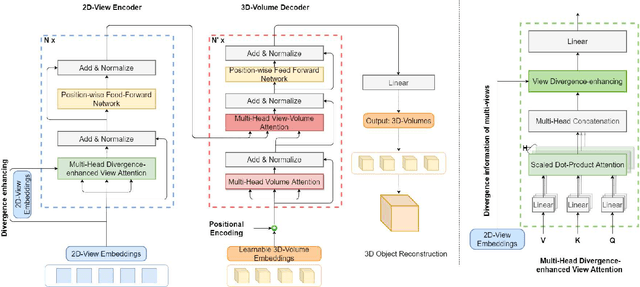



Deep CNN-based methods have so far achieved the state of the art results in multi-view 3D object reconstruction. Despite the considerable progress, the two core modules of these methods - multi-view feature extraction and fusion, are usually investigated separately, and the object relations in different views are rarely explored. In this paper, inspired by the recent great success in self-attention-based Transformer models, we reformulate the multi-view 3D reconstruction as a sequence-to-sequence prediction problem and propose a new framework named 3D Volume Transformer (VolT) for such a task. Unlike previous CNN-based methods using a separate design, we unify the feature extraction and view fusion in a single Transformer network. A natural advantage of our design lies in the exploration of view-to-view relationships using self-attention among multiple unordered inputs. On ShapeNet - a large-scale 3D reconstruction benchmark dataset, our method achieves a new state-of-the-art accuracy in multi-view reconstruction with fewer parameters ($70\%$ less) than other CNN-based methods. Experimental results also suggest the strong scaling capability of our method. Our code will be made publicly available.
Efficient Subsampling for Generating High-Quality Images from Conditional Generative Adversarial Networks
Mar 20, 2021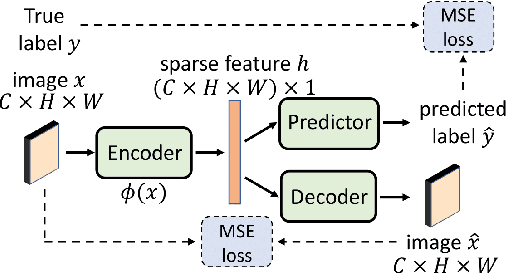
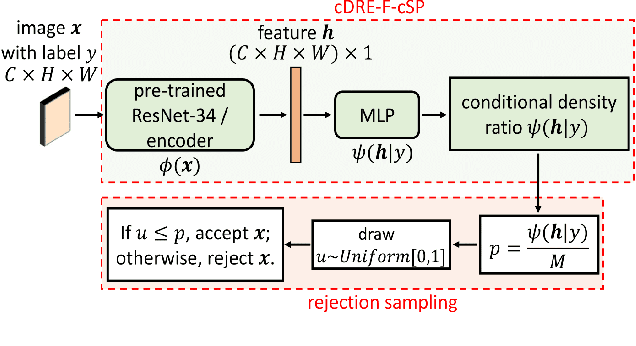
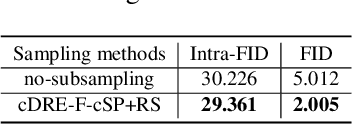
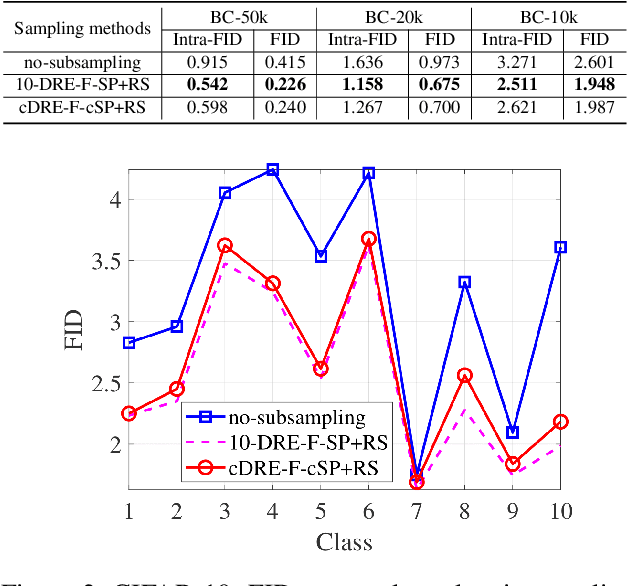
Subsampling unconditional generative adversarial networks (GANs) to improve the overall image quality has been studied recently. However, these methods often require high training costs (e.g., storage space, parameter tuning) and may be inefficient or even inapplicable for subsampling conditional GANs, such as class-conditional GANs and continuous conditional GANs (CcGANs), when the condition has many distinct values. In this paper, we propose an efficient method called conditional density ratio estimation in feature space with conditional Softplus loss (cDRE-F-cSP). With cDRE-F-cSP, we estimate an image's conditional density ratio based on a novel conditional Softplus (cSP) loss in the feature space learned by a specially designed ResNet-34 or sparse autoencoder. We then derive the error bound of a conditional density ratio model trained with the proposed cSP loss. Finally, we propose a rejection sampling scheme, termed cDRE-F-cSP+RS, which can subsample both class-conditional GANs and CcGANs efficiently. An extra filtering scheme is also developed for CcGANs to increase the label consistency. Experiments on CIFAR-10 and Tiny-ImageNet datasets show that cDRE-F-cSP+RS can substantially improve the Intra-FID and FID scores of BigGAN. Experiments on RC-49 and UTKFace datasets demonstrate that cDRE-F-cSP+RS also improves Intra-FID, Diversity, and Label Score of CcGANs. Moreover, to show the high efficiency of cDRE-F-cSP+RS, we compare it with the state-of-the-art unconditional subsampling method (i.e., DRE-F-SP+RS). With comparable or even better performance, cDRE-F-cSP+RS only requires about \textbf{10}\% and \textbf{1.7}\% of the training costs spent respectively on CIFAR-10 and UTKFace by DRE-F-SP+RS.
Adversarial Attacks on Camera-LiDAR Models for 3D Car Detection
Mar 17, 2021
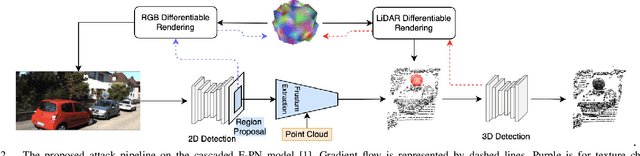
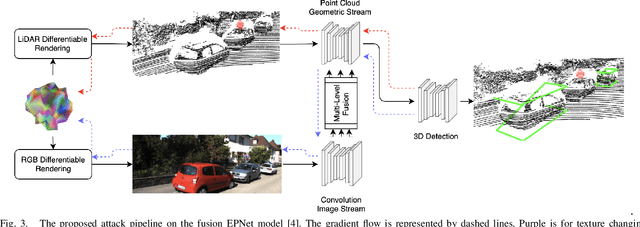
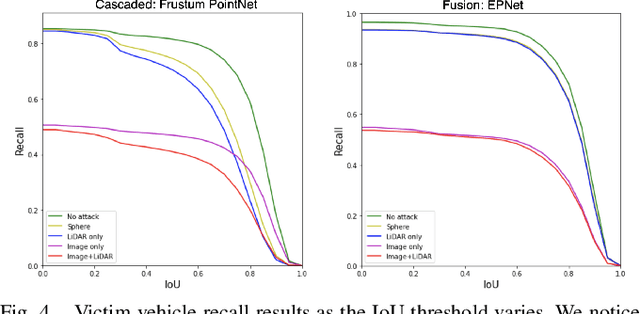
Most autonomous vehicles (AVs) rely on LiDAR and RGB camera sensors for perception. Using these point cloud and image data, perception models based on deep neural nets (DNNs) have achieved state-of-the-art performance in 3D detection. The vulnerability of DNNs to adversarial attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously. Multi-modal perception systems used in AVs can be divided into two broad types: cascaded models which use each modality independently, and fusion models which learn from different modalities simultaneously. We propose a universal and physically realizable adversarial attack for each type, and study and contrast their respective vulnerabilities to attacks. We place a single adversarial object with specific shape and texture on top of a car with the objective of making this car evade detection. Evaluating on the popular KITTI benchmark, our adversarial object made the host vehicle escape detection by each model type nearly 50% of the time. The dense RGB input contributed more to the success of the adversarial attacks on both cascaded and fusion models. We found that the fusion model was relatively more robust to adversarial attacks than the cascaded model.
Towards Universal Physical Attacks On Cascaded Camera-Lidar 3D Object Detection Models
Jan 31, 2021
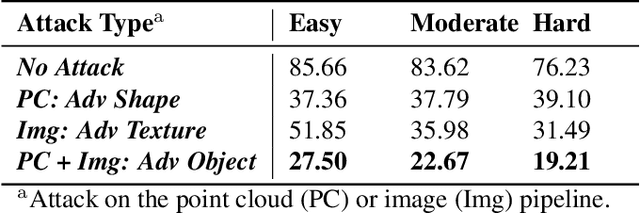
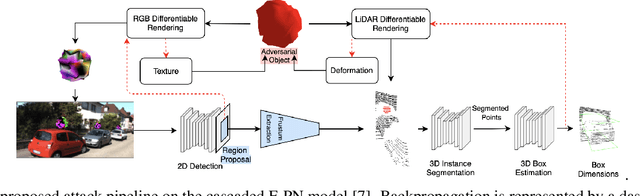
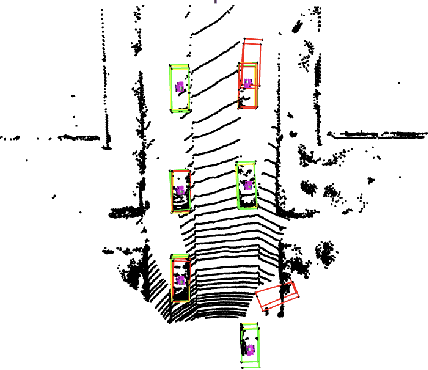
We propose a universal and physically realizable adversarial attack on a cascaded multi-modal deep learning network (DNN), in the context of self-driving cars. DNNs have achieved high performance in 3D object detection, but they are known to be vulnerable to adversarial attacks. These attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously - a gap to be filled in this paper. We use a single 3D mesh and differentiable rendering to explore how perturbing the mesh's geometry and texture can reduce the robustness of DNNs to adversarial attacks. We attack a prominent cascaded multi-modal DNN, the Frustum-Pointnet model. Using the popular KITTI benchmark, we showed that the proposed universal multi-modal attack was successful in reducing the model's ability to detect a car by nearly 73%. This work can aid in the understanding of what the cascaded RGB-point cloud DNN learns and its vulnerability to adversarial attacks.
CcGAN: Continuous Conditional Generative Adversarial Networks for Image Generation
Nov 15, 2020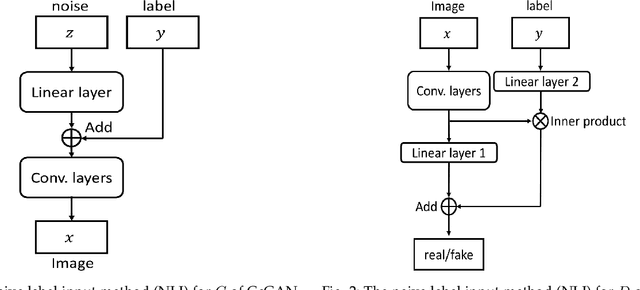

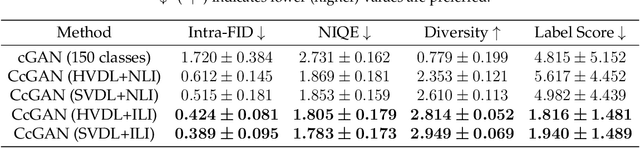

This work proposes the continuous conditional generative adversarial network (CcGAN), the first generative model for image generation conditional on continuous, scalar conditions (termed regression labels). Existing conditional GANs (cGANs) are mainly designed for categorical conditions (e.g., class labels); conditioning on regression labels is mathematically distinct and raises two fundamental problems: (P1) Since there may be very few (even zero) real images for some regression labels, minimizing existing empirical versions of cGAN losses (a.k.a. empirical cGAN losses) often fails in practice; (P2) Since regression labels are scalar and infinitely many, conventional label input methods are not applicable. The proposed CcGAN solves the above problems, respectively, by (S1) reformulating existing empirical cGAN losses to be appropriate for the continuous scenario; and (S2) proposing a naive label input (NLI) method and an improved label input (ILI) method to incorporate regression labels into the generator and the discriminator. The reformulation in (S1) leads to two novel empirical discriminator losses, termed the hard vicinal discriminator loss (HVDL) and the soft vicinal discriminator loss (SVDL) respectively, and a novel empirical generator loss. The error bounds of a discriminator trained with HVDL and SVDL are derived under mild assumptions in this work. Two new benchmark datasets (RC-49 and Cell-200) and a novel evaluation metric (Sliding Fr\'echet Inception Distance) are also proposed for this continuous scenario. Our experiments on the Circular 2-D Gaussians, RC-49, UTKFace, Cell-200, and Steering Angle datasets show that CcGAN can generate diverse, high-quality samples from the image distribution conditional on a given regression label. Moreover, in these experiments, CcGAN substantially outperforms cGAN both visually and quantitatively.
Perception Improvement for Free: Exploring Imperceptible Black-box Adversarial Attacks on Image Classification
Oct 30, 2020
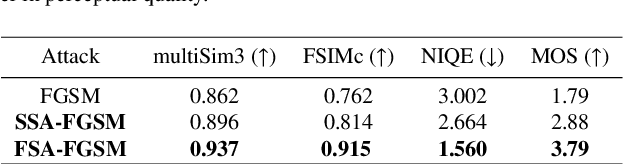


Deep neural networks are vulnerable to adversarial attacks. White-box adversarial attacks can fool neural networks with small adversarial perturbations, especially for large size images. However, keeping successful adversarial perturbations imperceptible is especially challenging for transfer-based black-box adversarial attacks. Often such adversarial examples can be easily spotted due to their unpleasantly poor visual qualities, which compromises the threat of adversarial attacks in practice. In this study, to improve the image quality of black-box adversarial examples perceptually, we propose structure-aware adversarial attacks by generating adversarial images based on psychological perceptual models. Specifically, we allow higher perturbations on perceptually insignificant regions, while assigning lower or no perturbation on visually sensitive regions. In addition to the proposed spatial-constrained adversarial perturbations, we also propose a novel structure-aware frequency adversarial attack method in the discrete cosine transform (DCT) domain. Since the proposed attacks are independent of the gradient estimation, they can be directly incorporated with existing gradient-based attacks. Experimental results show that, with the comparable attack success rate (ASR), the proposed methods can produce adversarial examples with considerably improved visual quality for free. With the comparable perceptual quality, the proposed approaches achieve higher attack success rates: particularly for the frequency structure-aware attacks, the average ASR improves more than 10% over the baseline attacks.
Perception Matters: Exploring Imperceptible and Transferable Anti-forensics for GAN-generated Fake Face Imagery Detection
Oct 29, 2020
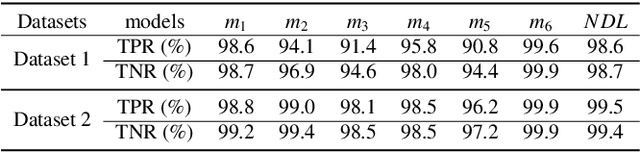
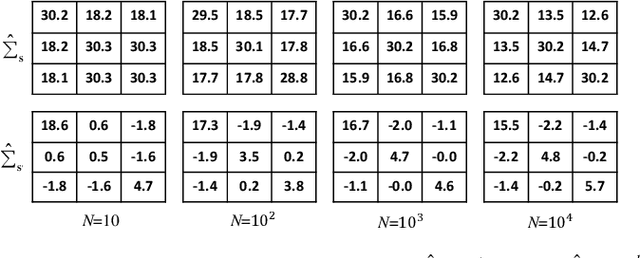
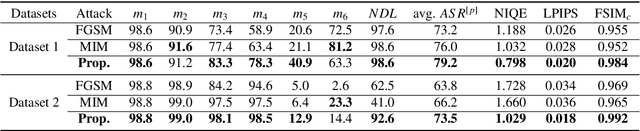
Recently, generative adversarial networks (GANs) can generate photo-realistic fake facial images which are perceptually indistinguishable from real face photos, promoting research on fake face detection. Though fake face forensics can achieve high detection accuracy, their anti-forensic counterparts are less investigated. Here we explore more \textit{imperceptible} and \textit{transferable} anti-forensics for fake face imagery detection based on adversarial attacks. Since facial and background regions are often smooth, even small perturbation could cause noticeable perceptual impairment in fake face images. Therefore it makes existing adversarial attacks ineffective as an anti-forensic method. Our perturbation analysis reveals the intuitive reason of the perceptual degradation issue when directly applying existing attacks. We then propose a novel adversarial attack method, better suitable for image anti-forensics, in the transformed color domain by considering visual perception. Simple yet effective, the proposed method can fool both deep learning and non-deep learning based forensic detectors, achieving higher attack success rate and significantly improved visual quality. Specially, when adversaries consider imperceptibility as a constraint, the proposed anti-forensic method can improve the average attack success rate by around 30\% on fake face images over two baseline attacks. \textit{More imperceptible} and \textit{more transferable}, the proposed method raises new security concerns to fake face imagery detection. We have released our code for public use, and hopefully the proposed method can be further explored in related forensic applications as an anti-forensic benchmark.
CHAIN: Concept-harmonized Hierarchical Inference Interpretation of Deep Convolutional Neural Networks
Feb 05, 2020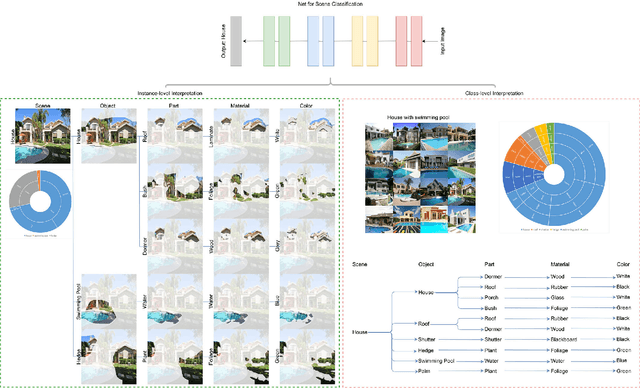
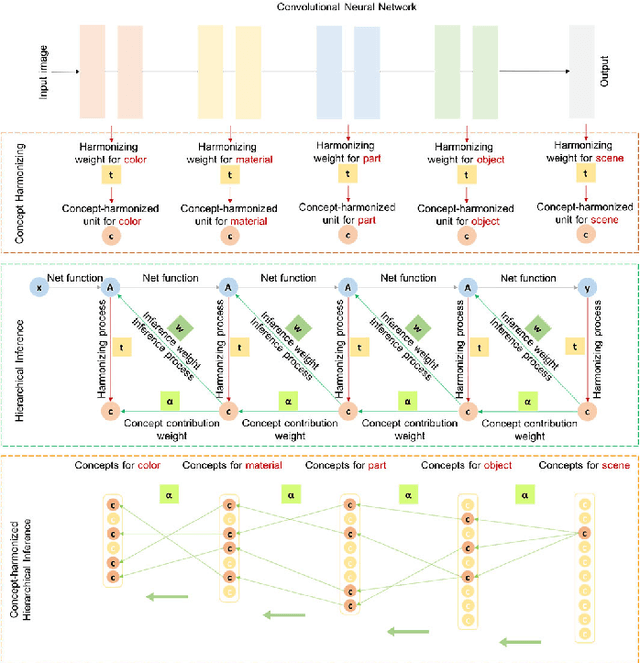


With the great success of networks, it witnesses the increasing demand for the interpretation of the internal network mechanism, especially for the net decision-making logic. To tackle the challenge, the Concept-harmonized HierArchical INference (CHAIN) is proposed to interpret the net decision-making process. For net-decisions being interpreted, the proposed method presents the CHAIN interpretation in which the net decision can be hierarchically deduced into visual concepts from high to low semantic levels. To achieve it, we propose three models sequentially, i.e., the concept harmonizing model, the hierarchical inference model, and the concept-harmonized hierarchical inference model. Firstly, in the concept harmonizing model, visual concepts from high to low semantic-levels are aligned with net-units from deep to shallow layers. Secondly, in the hierarchical inference model, the concept in a deep layer is disassembled into units in shallow layers. Finally, in the concept-harmonized hierarchical inference model, a deep-layer concept is inferred from its shallow-layer concepts. After several rounds, the concept-harmonized hierarchical inference is conducted backward from the highest semantic level to the lowest semantic level. Finally, net decision-making is explained as a form of concept-harmonized hierarchical inference, which is comparable to human decision-making. Meanwhile, the net layer structure for feature learning can be explained based on the hierarchical visual concepts. In quantitative and qualitative experiments, we demonstrate the effectiveness of CHAIN at the instance and class levels.
Subsampling Generative Adversarial Networks: Density Ratio Estimation in Feature Space with Softplus Loss
Nov 01, 2019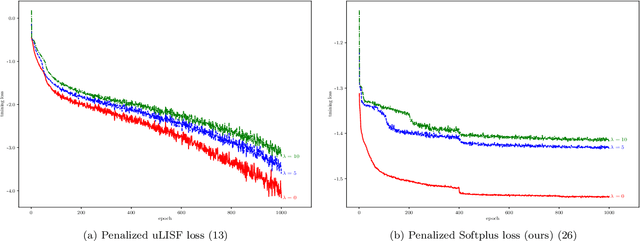
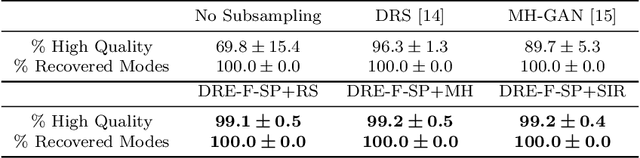
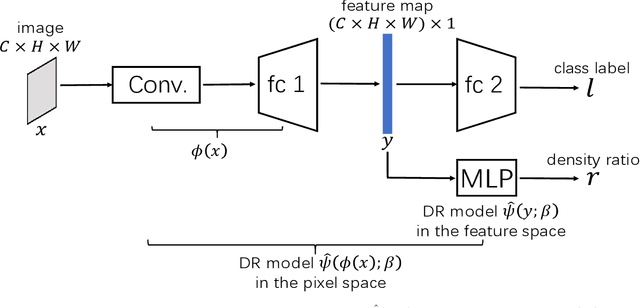
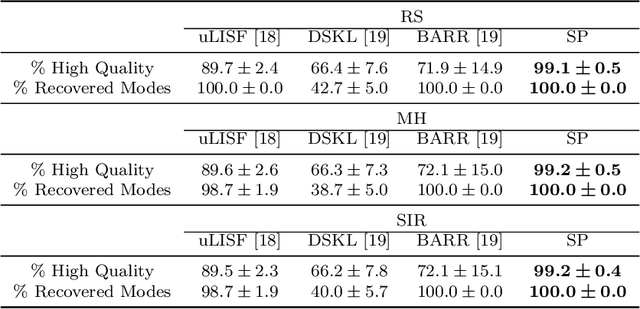
Filtering out unrealistic images from trained generative adversarial networks (GANs) has attracted considerable attention recently. Two density ratio based subsampling methods---Discriminator Rejection Sampling (DRS) and Metropolis-Hastings GAN (MH-GAN)---were recently proposed, and their effectiveness in improving GANs was demonstrated on multiple datasets. However, DRS and MH-GAN are based on discriminator based density ratio estimation (DRE) methods, so they may not work well if the discriminator in the trained GAN is far from optimal. Moreover, they do not apply to some GANs (e.g., MMD-GAN). In this paper, we propose a novel Softplus (SP) loss for DRE. Based on it, we develop a sample-based DRE method in a feature space learned by a specially designed and pre-trained ResNet-34 (DRE-F-SP). We derive the rate of convergence of a density ratio model trained under the SP loss. Then, we propose three different density ratio subsampling methods (DRE-F-SP+RS, DRE-F-SP+MH, and DRE-F-SP+SIR) for GANs based on DRE-F-SP. Our subsampling methods do not rely on the optimality of the discriminator and are suitable for all types of GANs. We empirically show our subsampling approach can substantially outperform DRS and MH-GAN on a synthetic dataset and the CIFAR-10 dataset, using multiple GANs.