 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Testing of Deep Neural Networks via Decision Boundary Analysis
Jul 22, 2022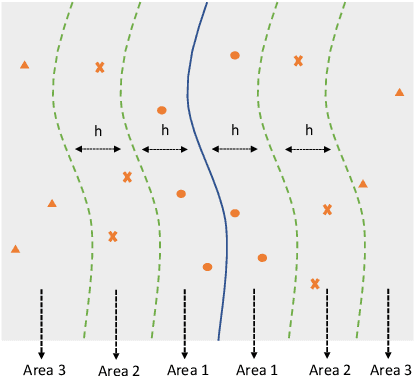


Deep learning plays a more and more important role in our daily life due to its competitive performance in multiple industrial application domains. As the core of DL-enabled systems, deep neural networks automatically learn knowledge from carefully collected and organized training data to gain the ability to predict the label of unseen data. Similar to the traditional software systems that need to be comprehensively tested, DNNs also need to be carefully evaluated to make sure the quality of the trained model meets the demand. In practice, the de facto standard to assess the quality of DNNs in industry is to check their performance (accuracy) on a collected set of labeled test data. However, preparing such labeled data is often not easy partly because of the huge labeling effort, i.e., data labeling is labor-intensive, especially with the massive new incoming unlabeled data every day. Recent studies show that test selection for DNN is a promising direction that tackles this issue by selecting minimal representative data to label and using these data to assess the model. However, it still requires human effort and cannot be automatic. In this paper, we propose a novel technique, named Aries, that can estimate the performance of DNNs on new unlabeled data using only the information obtained from the original test data. The key insight behind our technique is that the model should have similar prediction accuracy on the data which have similar distances to the decision boundary. We performed a large-scale evaluation of our technique on 13 types of data transformation methods. The results demonstrate the usefulness of our technique that the estimated accuracy by Aries is only 0.03% -- 2.60% (on average 0.61%) off the true accuracy. Besides, Aries also outperforms the state-of-the-art selection-labeling-based methods in most (96 out of 128) cases.
CodeS: A Distribution Shift Benchmark Dataset for Source Code Learning
Jun 11, 2022



Over the past few years, deep learning (DL) has been continuously expanding its applications and becoming a driving force for large-scale source code analysis in the big code era. Distribution shift, where the test set follows a different distribution from the training set, has been a longstanding challenge for the reliable deployment of DL models due to the unexpected accuracy degradation. Although recent progress on distribution shift benchmarking has been made in domains such as computer vision and natural language process. Limited progress has been made on distribution shift analysis and benchmarking for source code tasks, on which there comes a strong demand due to both its volume and its important role in supporting the foundations of almost all industrial sectors. To fill this gap, this paper initiates to propose CodeS, a distribution shift benchmark dataset, for source code learning. Specifically, CodeS supports 2 programming languages (i.e., Java and Python) and 5 types of code distribution shifts (i.e., task, programmer, time-stamp, token, and CST). To the best of our knowledge, we are the first to define the code representation-based distribution shifts. In the experiments, we first evaluate the effectiveness of existing out-of-distribution detectors and the reasonability of the distribution shift definitions and then measure the model generalization of popular code learning models (e.g., CodeBERT) on classification task. The results demonstrate that 1) only softmax score-based OOD detectors perform well on CodeS, 2) distribution shift causes the accuracy degradation in all code classification models, 3) representation-based distribution shifts have a higher impact on the model than others, and 4) pre-trained models are more resistant to distribution shifts. We make CodeS publicly available, enabling follow-up research on the quality assessment of code learning models.
Characterizing and Understanding the Behavior of Quantized Models for Reliable Deployment
Apr 08, 2022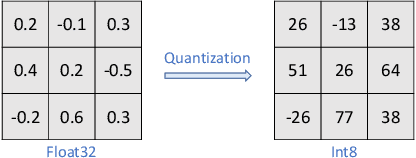
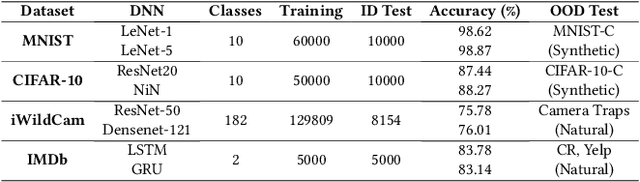
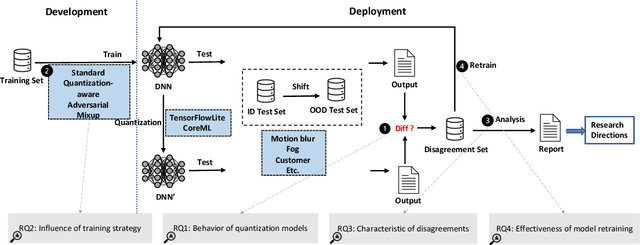
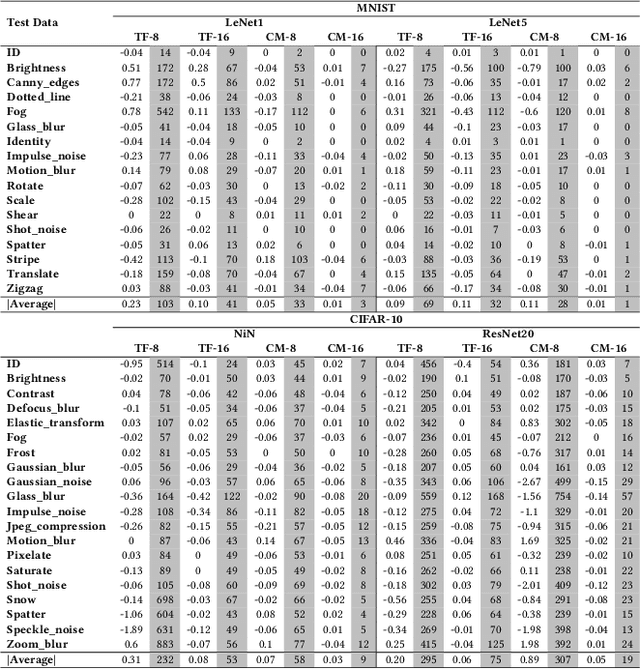
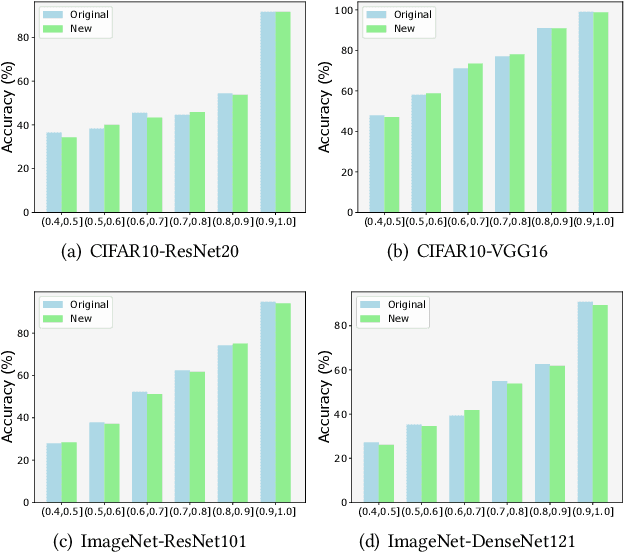
Deep Neural Networks (DNNs) have gained considerable attention in the past decades due to their astounding performance in different applications, such as natural language modeling, self-driving assistance, and source code understanding. With rapid exploration, more and more complex DNN architectures have been proposed along with huge pre-trained model parameters. The common way to use such DNN models in user-friendly devices (e.g., mobile phones) is to perform model compression before deployment. However, recent research has demonstrated that model compression, e.g., model quantization, yields accuracy degradation as well as outputs disagreements when tested on unseen data. Since the unseen data always include distribution shifts and often appear in the wild, the quality and reliability of quantized models are not ensured. In this paper, we conduct a comprehensive study to characterize and help users understand the behaviors of quantized models. Our study considers 4 datasets spanning from image to text, 8 DNN architectures including feed-forward neural networks and recurrent neural networks, and 42 shifted sets with both synthetic and natural distribution shifts. The results reveal that 1) data with distribution shifts happen more disagreements than without. 2) Quantization-aware training can produce more stable models than standard, adversarial, and Mixup training. 3) Disagreements often have closer top-1 and top-2 output probabilities, and $Margin$ is a better indicator than the other uncertainty metrics to distinguish disagreements. 4) Retraining with disagreements has limited efficiency in removing disagreements. We opensource our code and models as a new benchmark for further studying the quantized models.
Labeling-Free Comparison Testing of Deep Learning Models
Apr 08, 2022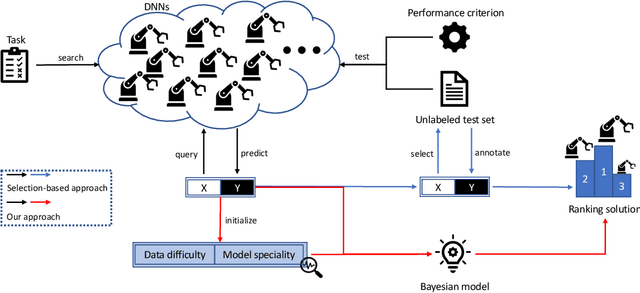

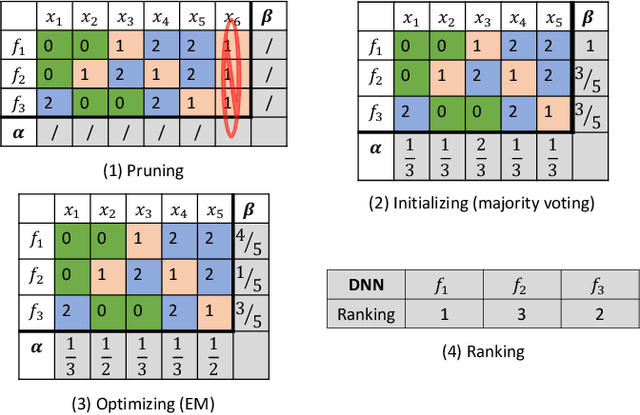
Various deep neural networks (DNNs) are developed and reported for their tremendous success in multiple domains. Given a specific task, developers can collect massive DNNs from public sources for efficient reusing and avoid redundant work from scratch. However, testing the performance (e.g., accuracy and robustness) of multiple DNNs and giving a reasonable recommendation that which model should be used is challenging regarding the scarcity of labeled data and demand of domain expertise. Existing testing approaches are mainly selection-based where after sampling, a few of the test data are labeled to discriminate DNNs. Therefore, due to the randomness of sampling, the performance ranking is not deterministic. In this paper, we propose a labeling-free comparison testing approach to overcome the limitations of labeling effort and sampling randomness. The main idea is to learn a Bayesian model to infer the models' specialty only based on predicted labels. To evaluate the effectiveness of our approach, we undertook exhaustive experiments on 9 benchmark datasets spanning in the domains of image, text, and source code, and 165 DNNs. In addition to accuracy, we consider the robustness against synthetic and natural distribution shifts. The experimental results demonstrate that the performance of existing approaches degrades under distribution shifts. Our approach outperforms the baseline methods by up to 0.74 and 0.53 on Spearman's correlation and Kendall's $\tau$, respectively, regardless of the dataset and distribution shift. Additionally, we investigated the impact of model quality (accuracy and robustness) and diversity (standard deviation of the quality) on the testing effectiveness and observe that there is a higher chance of a good result when the quality is over 50\% and the diversity is larger than 18\%.
On The Empirical Effectiveness of Unrealistic Adversarial Hardening Against Realistic Adversarial Attacks
Feb 07, 2022



While the literature on security attacks and defense of Machine Learning (ML) systems mostly focuses on unrealistic adversarial examples, recent research has raised concern about the under-explored field of realistic adversarial attacks and their implications on the robustness of real-world systems. Our paper paves the way for a better understanding of adversarial robustness against realistic attacks and makes two major contributions. First, we conduct a study on three real-world use cases (text classification, botnet detection, malware detection)) and five datasets in order to evaluate whether unrealistic adversarial examples can be used to protect models against realistic examples. Our results reveal discrepancies across the use cases, where unrealistic examples can either be as effective as the realistic ones or may offer only limited improvement. Second, to explain these results, we analyze the latent representation of the adversarial examples generated with realistic and unrealistic attacks. We shed light on the patterns that discriminate which unrealistic examples can be used for effective hardening. We release our code, datasets and models to support future research in exploring how to reduce the gap between unrealistic and realistic adversarial attacks.
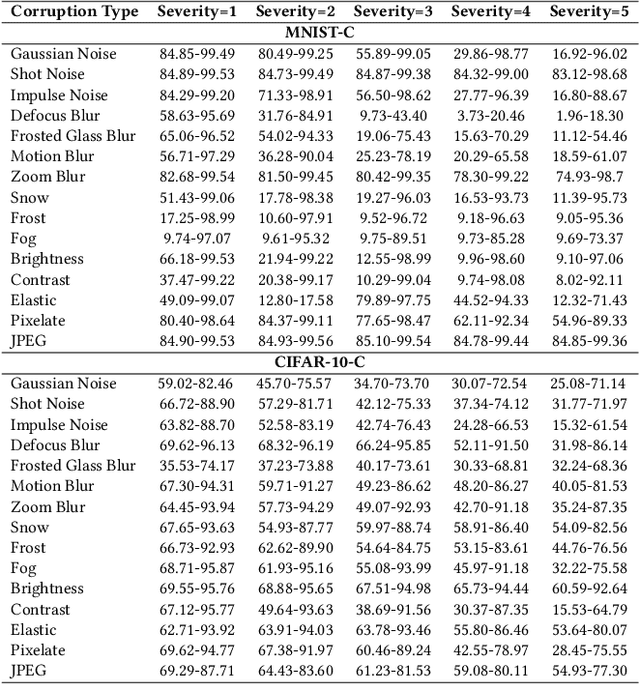
Robust Active Learning: Sample-Efficient Training of Robust Deep Learning Models
Dec 05, 2021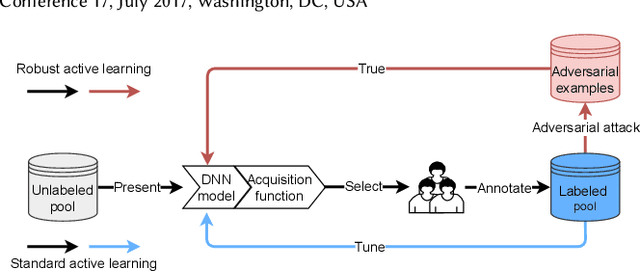
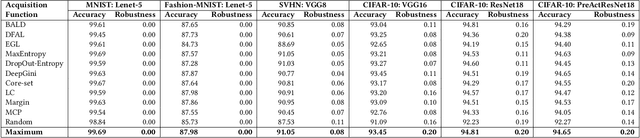
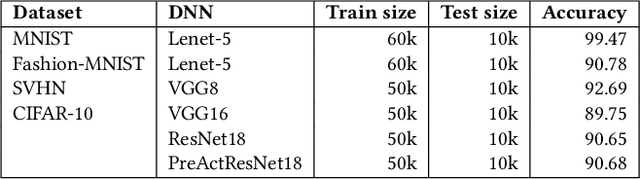
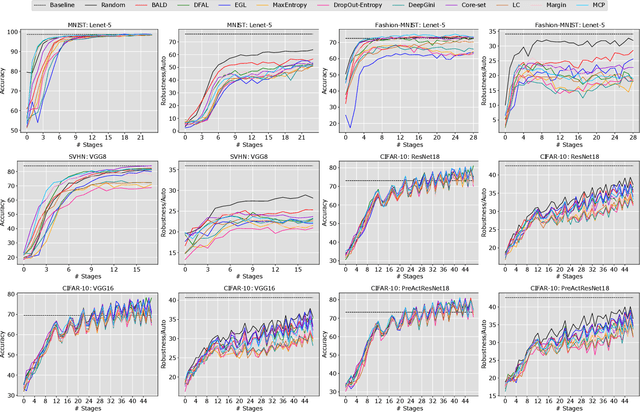
Active learning is an established technique to reduce the labeling cost to build high-quality machine learning models. A core component of active learning is the acquisition function that determines which data should be selected to annotate. State-of-the-art acquisition functions -- and more largely, active learning techniques -- have been designed to maximize the clean performance (e.g. accuracy) and have disregarded robustness, an important quality property that has received increasing attention. Active learning, therefore, produces models that are accurate but not robust. In this paper, we propose \emph{robust active learning}, an active learning process that integrates adversarial training -- the most established method to produce robust models. Via an empirical study on 11 acquisition functions, 4 datasets, 6 DNN architectures, and 15105 trained DNNs, we show that robust active learning can produce models with the robustness (accuracy on adversarial examples) ranging from 2.35\% to 63.85\%, whereas standard active learning systematically achieves negligible robustness (less than 0.20\%). Our study also reveals, however, that the acquisition functions that perform well on accuracy are worse than random sampling when it comes to robustness. We, therefore, examine the reasons behind this and devise a new acquisition function that targets both clean performance and robustness. Our acquisition function -- named density-based robust sampling with entropy (DRE) -- outperforms the other acquisition functions (including random) in terms of robustness by up to 24.40\% (3.84\% than random particularly), while remaining competitive on accuracy. Additionally, we prove that DRE is applicable as a test selection metric for model retraining and stands out from all compared functions by up to 8.21\% robustness.
A Unified Framework for Adversarial Attack and Defense in Constrained Feature Space
Dec 02, 2021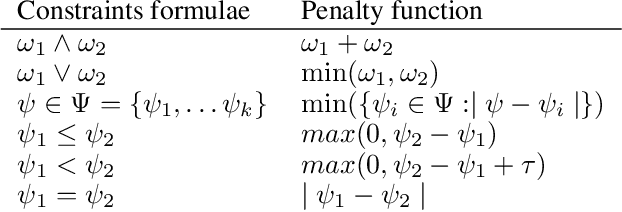
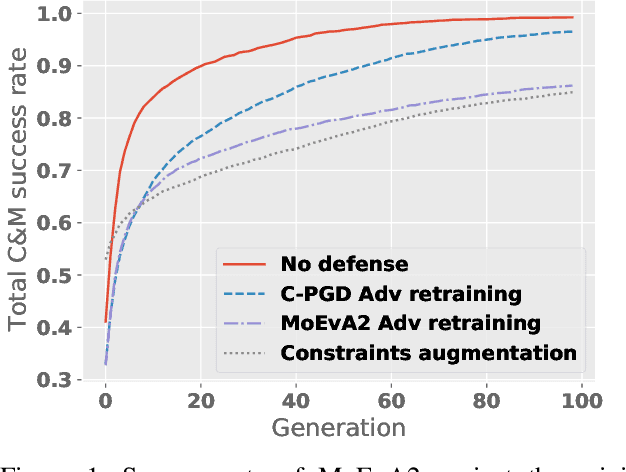
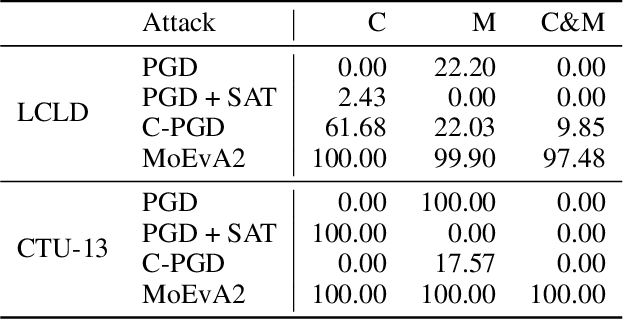
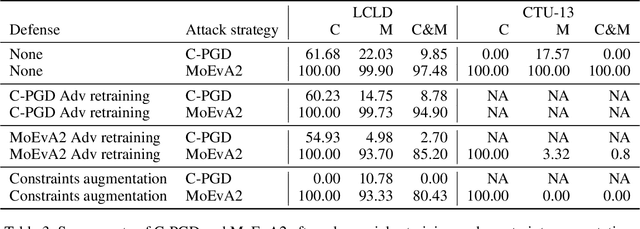
The generation of feasible adversarial examples is necessary for properly assessing models that work on constrained feature space. However, it remains a challenging task to enforce constraints into attacks that were designed for computer vision. We propose a unified framework to generate feasible adversarial examples that satisfy given domain constraints. Our framework supports the use cases reported in the literature and can handle both linear and non-linear constraints. We instantiate our framework into two algorithms: a gradient-based attack that introduces constraints in the loss function to maximize, and a multi-objective search algorithm that aims for misclassification, perturbation minimization, and constraint satisfaction. We show that our approach is effective on two datasets from different domains, with a success rate of up to 100%, where state-of-the-art attacks fail to generate a single feasible example. In addition to adversarial retraining, we propose to introduce engineered non-convex constraints to improve model adversarial robustness. We demonstrate that this new defense is as effective as adversarial retraining. Our framework forms the starting point for research on constrained adversarial attacks and provides relevant baselines and datasets that future research can exploit.
Adversarial Robustness in Multi-Task Learning: Promises and Illusions
Oct 26, 2021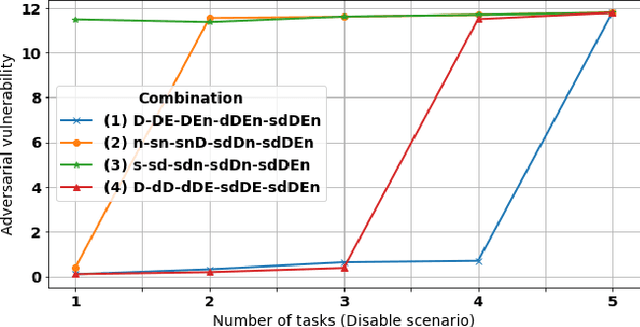
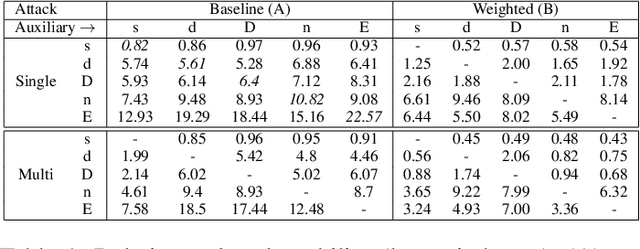
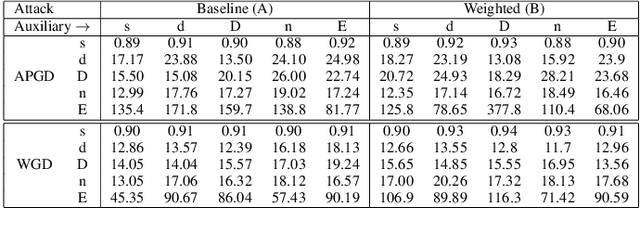

Vulnerability to adversarial attacks is a well-known weakness of Deep Neural networks. While most of the studies focus on single-task neural networks with computer vision datasets, very little research has considered complex multi-task models that are common in real applications. In this paper, we evaluate the design choices that impact the robustness of multi-task deep learning networks. We provide evidence that blindly adding auxiliary tasks, or weighing the tasks provides a false sense of robustness. Thereby, we tone down the claim made by previous research and study the different factors which may affect robustness. In particular, we show that the choice of the task to incorporate in the loss function are important factors that can be leveraged to yield more robust models.
MUTEN: Boosting Gradient-Based Adversarial Attacks via Mutant-Based Ensembles
Sep 27, 2021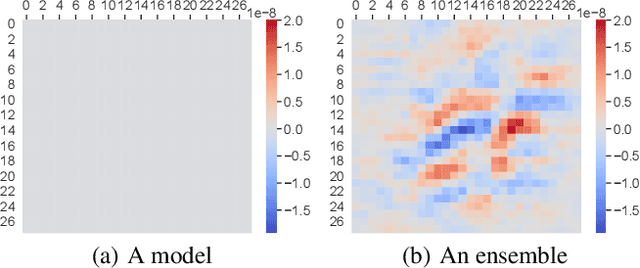

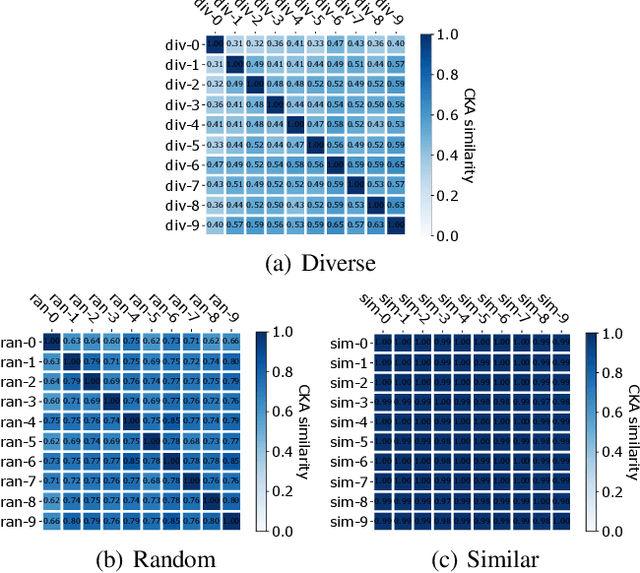
Deep Neural Networks (DNNs) are vulnerable to adversarial examples, which causes serious threats to security-critical applications. This motivated much research on providing mechanisms to make models more robust against adversarial attacks. Unfortunately, most of these defenses, such as gradient masking, are easily overcome through different attack means. In this paper, we propose MUTEN, a low-cost method to improve the success rate of well-known attacks against gradient-masking models. Our idea is to apply the attacks on an ensemble model which is built by mutating the original model elements after training. As we found out that mutant diversity is a key factor in improving success rate, we design a greedy algorithm for generating diverse mutants efficiently. Experimental results on MNIST, SVHN, and CIFAR10 show that MUTEN can increase the success rate of four attacks by up to 0.45.
Effective and Efficient Data Poisoning in Semi-Supervised Learning
Dec 14, 2020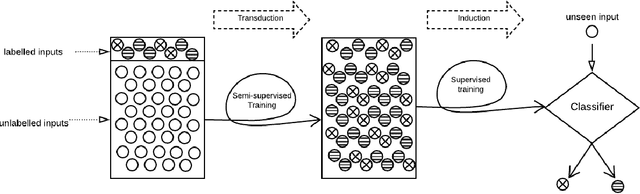
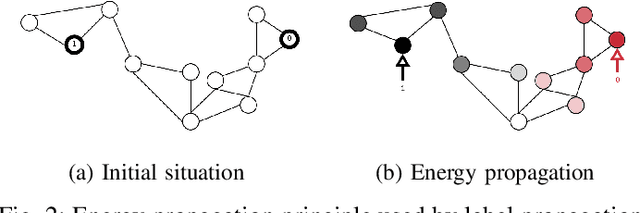
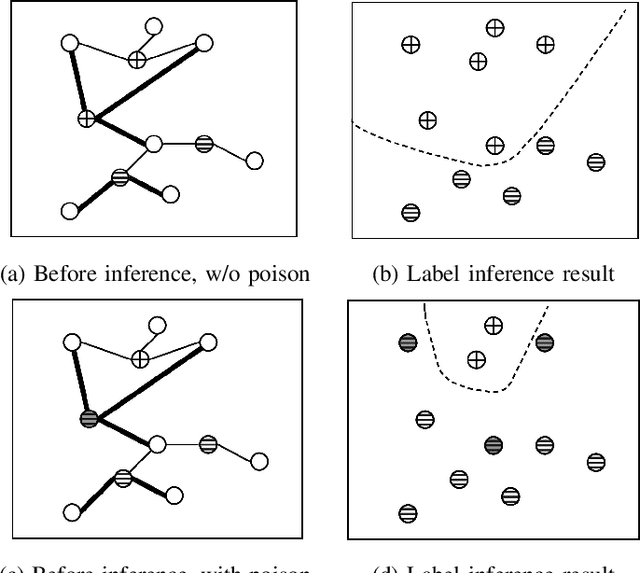
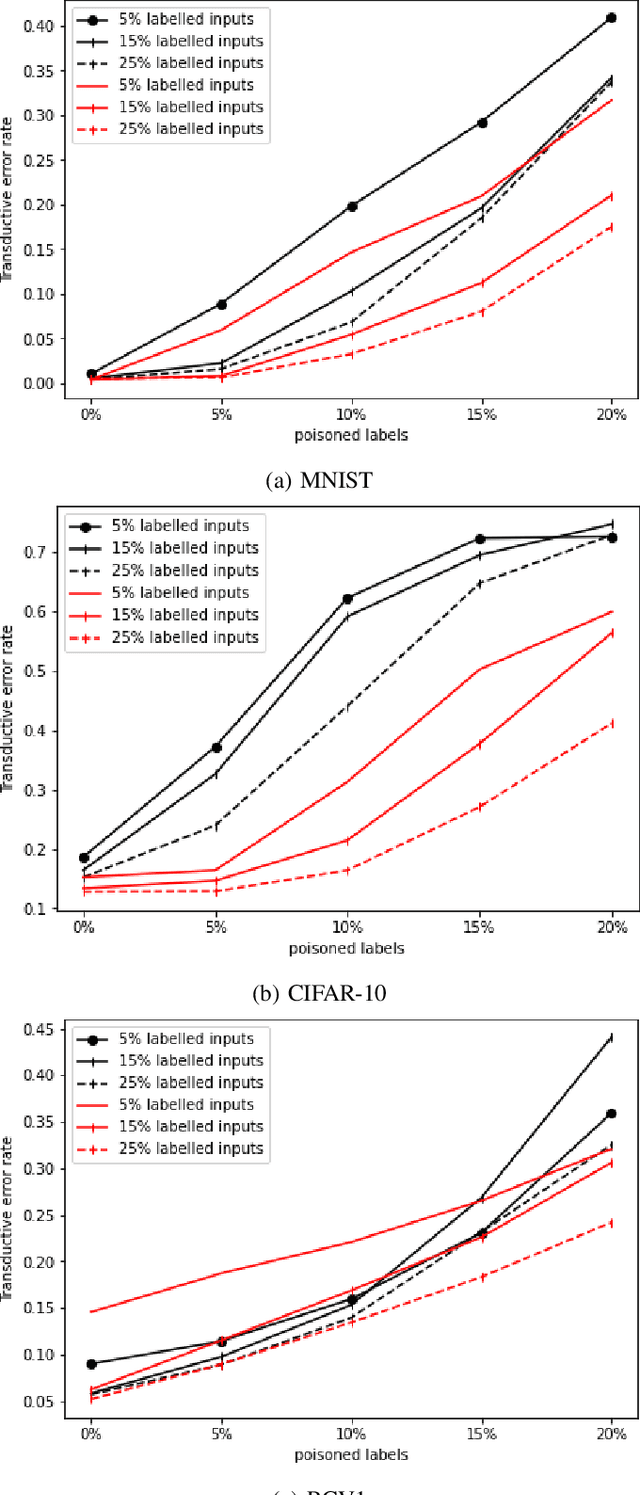
Semi-Supervised Learning (SSL) aims to maximize the benefits of learning from a limited amount of labelled data together with a vast amount of unlabelled data. Because they rely on the known labels to infer the unknown labels, SSL algorithms are sensitive to data quality. This makes it important to study the potential threats related to the labelled data, more specifically, label poisoning. However, data poisoning of SSL remains largely understudied. To fill this gap, we propose a novel data poisoning method which is both effective and efficient. Our method exploits mathematical properties of SSL to approximate the influence of labelled inputs onto unlabelled one, which allows the identification of the inputs that, if poisoned, would produce the highest number of incorrectly inferred labels. We evaluate our approach on three classification problems under 12 different experimental settings each. Compared to the state of the art, our influence-based attack produces an average increase of error rate 3 times higher, while being faster by multiple orders of magnitude. Moreover, our method can inform engineers of inputs that deserve investigation (relabelling them) before training the learning model. We show that relabelling one-third of the poisoned inputs (selected based on their influence) reduces the poisoning effect by 50%.