 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest Selection for Deep Learning Systems
Apr 30, 2019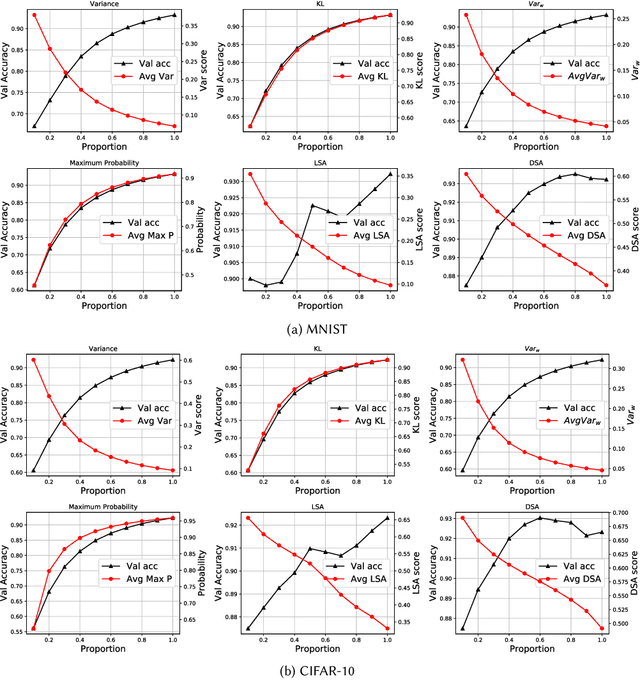
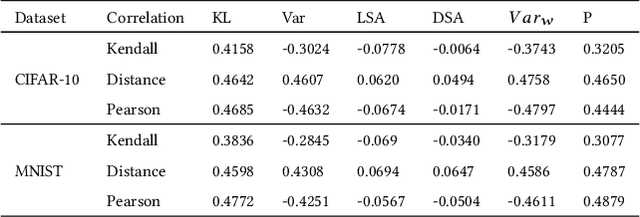
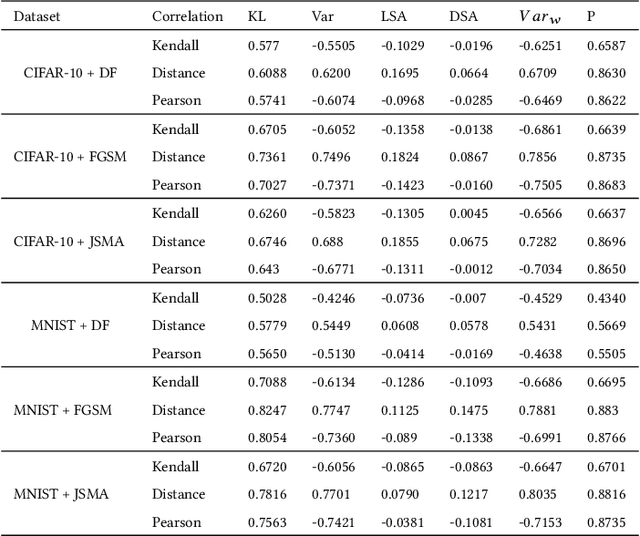
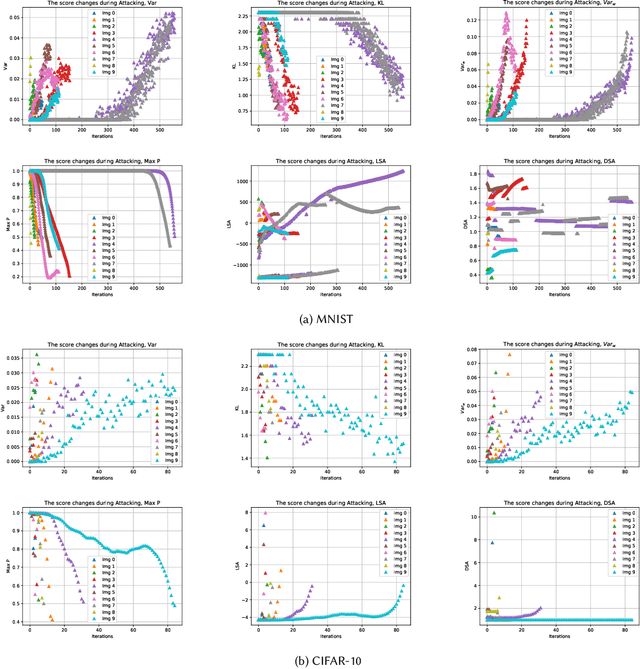
Testing of deep learning models is challenging due to the excessive number and complexity of computations involved. As a result, test data selection is performed manually and in an ad hoc way. This raises the question of how we can automatically select candidate test data to test deep learning models. Recent research has focused on adapting test selection metrics from code-based software testing (such as coverage) to deep learning. However, deep learning models have different attributes from code such as spread of computations across the entire network reflecting training data properties, balance of neuron weights and redundancy (use of many more neurons than needed). Such differences make code-based metrics inappropriate to select data that can challenge the models (can trigger misclassification). We thus propose a set of test selection metrics based on the notion of model uncertainty (model confidence on specific inputs). Intuitively, the more uncertain we are about a candidate sample, the more likely it is that this sample triggers a misclassification. Similarly, the samples for which we are the most uncertain, are the most informative and should be used to improve the model by retraining. We evaluate these metrics on two widely-used image classification problems involving real and artificial (adversarial) data. We show that uncertainty-based metrics have a strong ability to select data that are misclassified and lead to major improvement in classification accuracy during retraining: up to 80% more gain than random selection and other state-of-the-art metrics on one dataset and up to 29% on the other.
Constrained Bayesian Active Learning of Interference Channels in Cognitive Radio Networks
Oct 23, 2017



In this paper, a sequential probing method for interference constraint learning is proposed to allow a centralized Cognitive Radio Network (CRN) accessing the frequency band of a Primary User (PU) in an underlay cognitive scenario with a designed PU protection specification. The main idea is that the CRN probes the PU and subsequently eavesdrops the reverse PU link to acquire the binary ACK/NACK packet. This feedback indicates whether the probing-induced interference is harmful or not and can be used to learn the PU interference constraint. The cognitive part of this sequential probing process is the selection of the power levels of the Secondary Users (SUs) which aims to learn the PU interference constraint with a minimum number of probing attempts while setting a limit on the number of harmful probing-induced interference events or equivalently of NACK packet observations over a time window. This constrained design problem is studied within the Active Learning (AL) framework and an optimal solution is derived and implemented with a sophisticated, accurate and fast Bayesian Learning method, the Expectation Propagation (EP). The performance of this solution is also demonstrated through numerical simulations and compared with modified versions of AL techniques we developed in earlier work.