 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPCV: Information-Preserving Compression for MLLM Visual Encoders
Dec 21, 2025



Multimodal Large Language Models (MLLMs) deliver strong vision-language performance but at high computational cost, driven by numerous visual tokens processed by the Vision Transformer (ViT) encoder. Existing token pruning strategies are inadequate: LLM-stage token pruning overlooks the ViT's overhead, while conventional ViT token pruning, without language guidance, risks discarding textually critical visual cues and introduces feature distortions amplified by the ViT's bidirectional attention. To meet these challenges, we propose IPCV, a training-free, information-preserving compression framework for MLLM visual encoders. IPCV enables aggressive token pruning inside the ViT via Neighbor-Guided Reconstruction (NGR) that temporarily reconstructs pruned tokens to participate in attention with minimal overhead, then fully restores them before passing to the LLM. Besides, we introduce Attention Stabilization (AS) to further alleviate the negative influence from token pruning by approximating the K/V of pruned tokens. It can be directly applied to previous LLM-side token pruning methods to enhance their performance. Extensive experiments show that IPCV substantially reduces end-to-end computation and outperforms state-of-the-art training-free token compression methods across diverse image and video benchmarks. Our code is available at https://github.com/Perkzi/IPCV.
Efficient Reinforcement Learning with a Mind-Game for Full-Length StarCraft II
Mar 02, 2019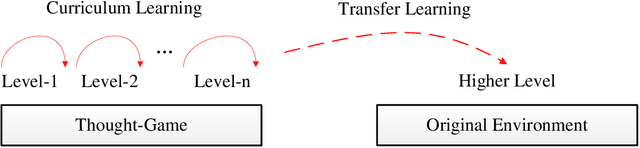
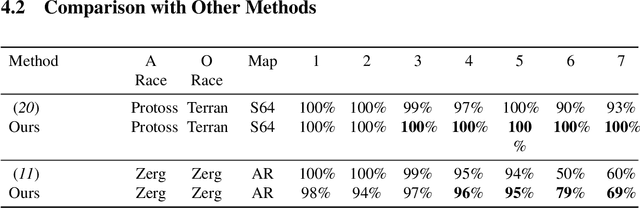
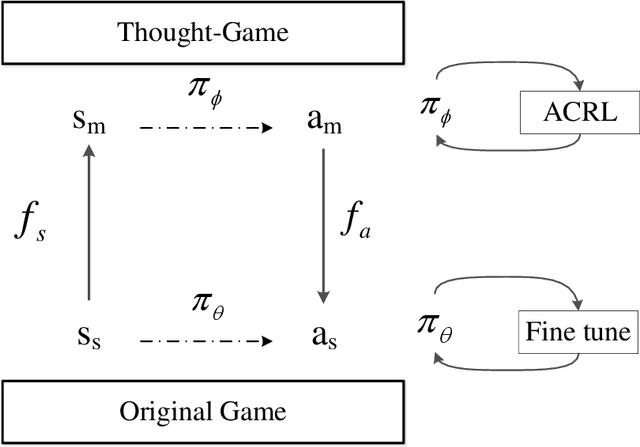

StarCraft II provides an extremely challenging platform for reinforcement learning due to its huge state-space and game length. The previous fastest method requires days to train a full-length game policy in a single commercial machine. In this paper, we introduce the mind-game to facilitate the reinforcement learning, which is an abstract task model. With the mind-game, the policy is firstly trained in the mind-game fastly and is then mapped to the real game for the second phase training. In our experiments, the trained agent can achieve a 100% win-rate on the map Simple64 against the most difficult non-cheating built-in bot (level-7), and the training is 100 times faster than the previous ones under the same computational resource. To test the generalization performance of the agent, a Golden level of StarCraft II Ladder human player has competed with the agent. With restricted strategy, the agent wins the human player by 4 out of 5 games. The mind-game approach might shed some light for further studies of efficient reinforcement learning. The codes are publicly available (https://github.com/mindgameSC2/mind-SC2).