 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Machine Learning Algorithm for Knowledge Graphs
Jan 04, 2020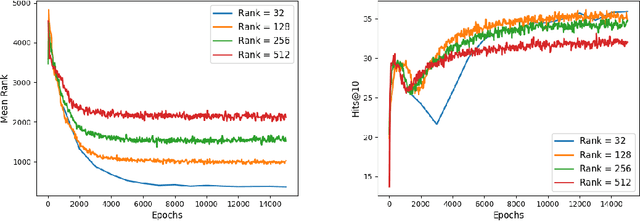
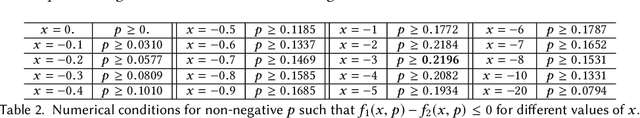
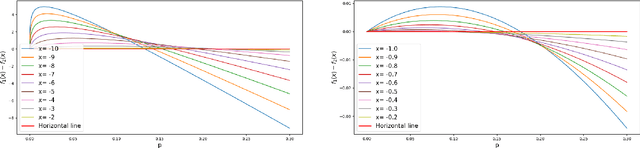
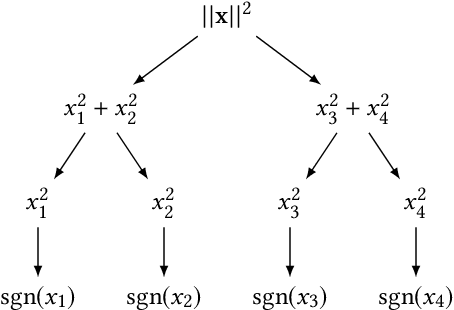
Semantic knowledge graphs are large-scale triple-oriented databases for knowledge representation and reasoning. Implicit knowledge can be inferred by modeling and reconstructing the tensor representations generated from knowledge graphs. However, as the sizes of knowledge graphs continue to grow, classical modeling becomes increasingly computational resource intensive. This paper investigates how quantum resources can be capitalized to accelerate the modeling of knowledge graphs. In particular, we propose the first quantum machine learning algorithm for making inference on tensorized data, e.g., on knowledge graphs. Since most tensor problems are NP-hard, it is challenging to devise quantum algorithms to support that task. We simplify the problem by making a plausible assumption that the tensor representation of a knowledge graph can be approximated by its low-rank tensor singular value decomposition, which is verified by our experiments. The proposed sampling-based quantum algorithm achieves exponential speedup with a runtime that is polylogarithmic in the dimension of knowledge graph tensor.
Improving Neural Relation Extraction with Positive and Unlabeled Learning
Nov 28, 2019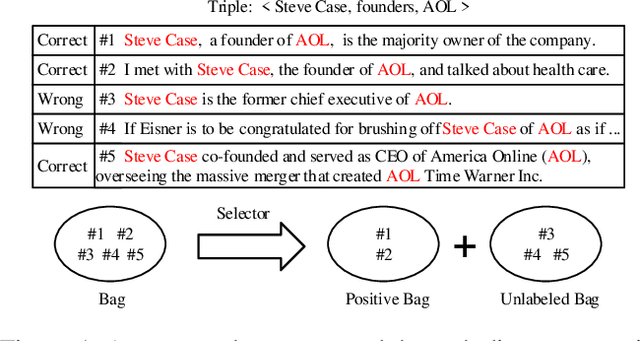
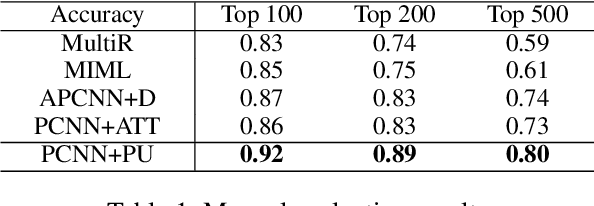
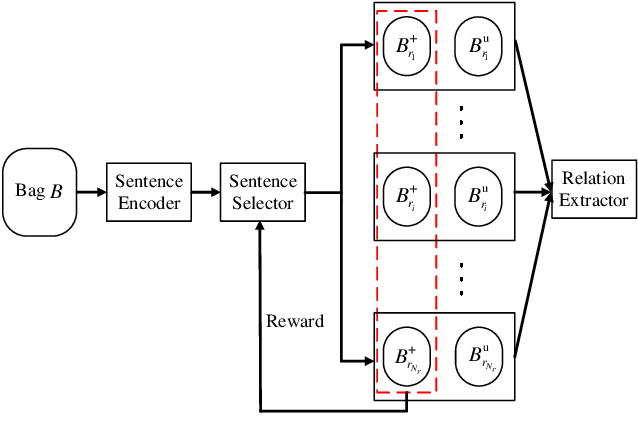
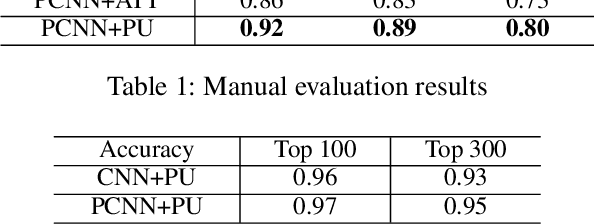
We present a novel approach to improve the performance of distant supervision relation extraction with Positive and Unlabeled (PU) Learning. This approach first applies reinforcement learning to decide whether a sentence is positive to a given relation, and then positive and unlabeled bags are constructed. In contrast to most previous studies, which mainly use selected positive instances only, we make full use of unlabeled instances and propose two new representations for positive and unlabeled bags. These two representations are then combined in an appropriate way to make bag-level prediction. Experimental results on a widely used real-world dataset demonstrate that this new approach indeed achieves significant and consistent improvements as compared to several competitive baselines.
McDiarmid-Type Inequalities for Graph-Dependent Variables and Stability Bounds
Sep 09, 2019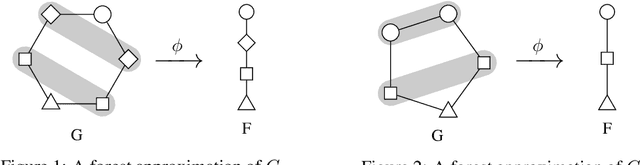
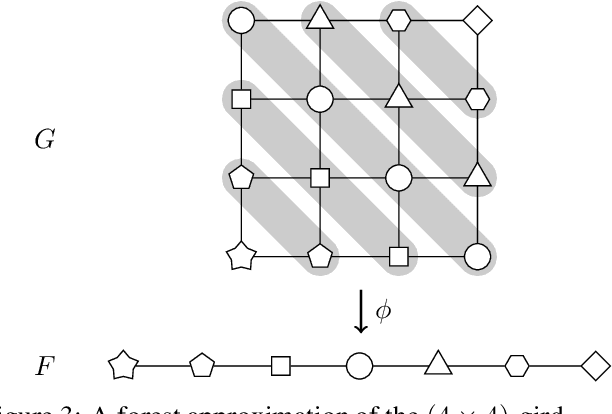
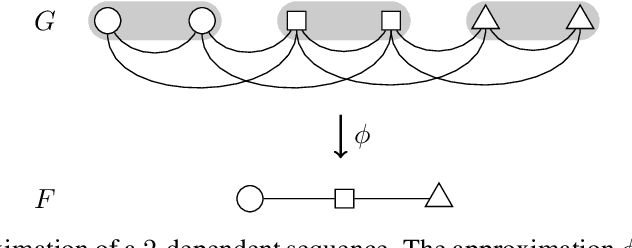
A crucial assumption in most statistical learning theory is that samples are independently and identically distributed (i.i.d.). However, for many real applications, the i.i.d. assumption does not hold. We consider learning problems in which examples are dependent and their dependency relation is characterized by a graph. To establish algorithm-dependent generalization theory for learning with non-i.i.d. data, we first prove novel McDiarmid-type concentration inequalities for Lipschitz functions of graph-dependent random variables. We show that concentration relies on the forest complexity of the graph, which characterizes the strength of the dependency. We demonstrate that for many types of dependent data, the forest complexity is small and thus implies good concentration. Based on our new inequalities we are able to build stability bounds for learning from graph-dependent data.
Variational Quantum Circuit Model for Knowledge Graphs Embedding
Feb 19, 2019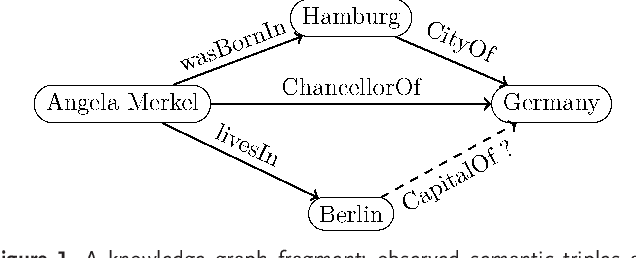
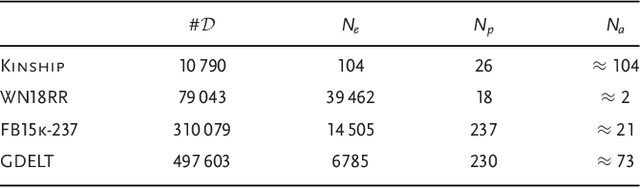
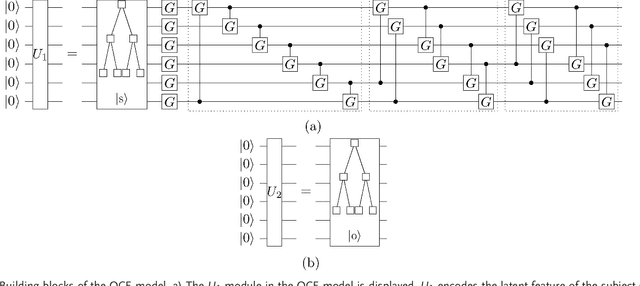
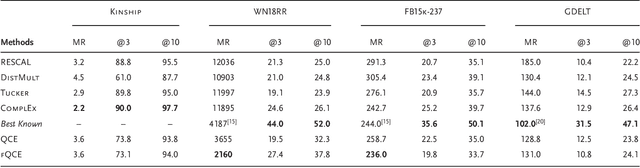
In this work, we propose the first quantum Ans\"atze for the statistical relational learning on knowledge graphs using parametric quantum circuits. We introduce two types of variational quantum circuits for knowledge graph embedding. Inspired by the classical representation learning, we first consider latent features for entities as coefficients of quantum states, while predicates are characterized by parametric gates acting on the quantum states. For the first model, the quantum advantages disappear when it comes to the optimization of this model. Therefore, we introduce a second quantum circuit model where embeddings of entities are generated from parameterized quantum gates acting on the pure quantum state. The benefit of the second method is that the quantum embeddings can be trained efficiently meanwhile preserving the quantum advantages. We show the proposed methods can achieve comparable results to the state-of-the-art classical models, e.g., RESCAL, DistMult. Furthermore, after optimizing the models, the complexity of inductive inference on the knowledge graphs might be reduced with respect to the number of entities.
MIDI-VAE: Modeling Dynamics and Instrumentation of Music with Applications to Style Transfer
Sep 20, 2018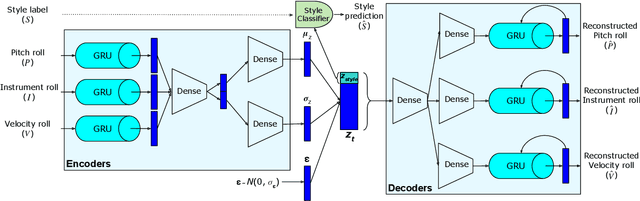
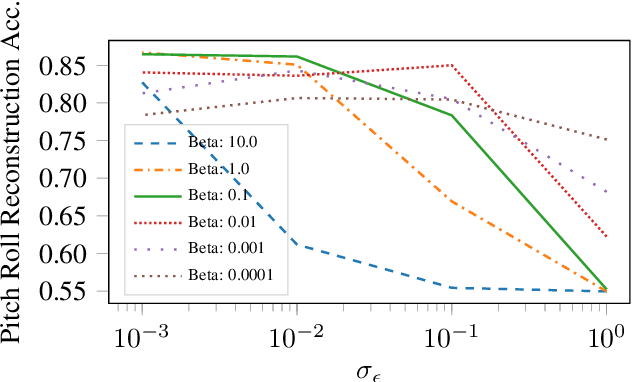
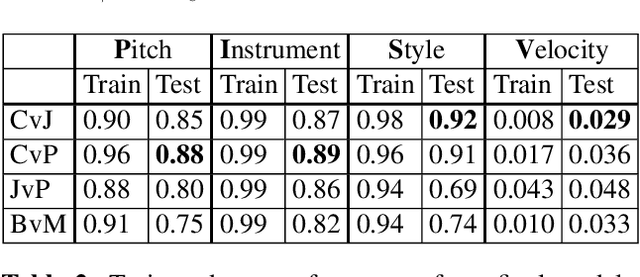
We introduce MIDI-VAE, a neural network model based on Variational Autoencoders that is capable of handling polyphonic music with multiple instrument tracks, as well as modeling the dynamics of music by incorporating note durations and velocities. We show that MIDI-VAE can perform style transfer on symbolic music by automatically changing pitches, dynamics and instruments of a music piece from, e.g., a Classical to a Jazz style. We evaluate the efficacy of the style transfer by training separate style validation classifiers. Our model can also interpolate between short pieces of music, produce medleys and create mixtures of entire songs. The interpolations smoothly change pitches, dynamics and instrumentation to create a harmonic bridge between two music pieces. To the best of our knowledge, this work represents the first successful attempt at applying neural style transfer to complete musical compositions.
Symbolic Music Genre Transfer with CycleGAN
Sep 20, 2018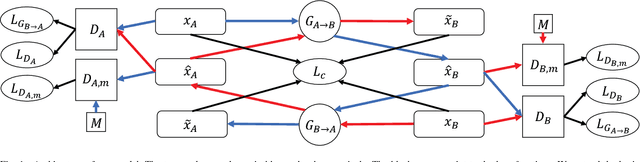

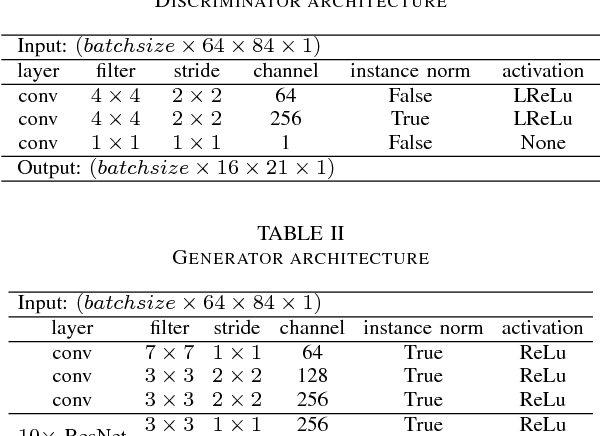
Deep generative models such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) have recently been applied to style and domain transfer for images, and in the case of VAEs, music. GAN-based models employing several generators and some form of cycle consistency loss have been among the most successful for image domain transfer. In this paper we apply such a model to symbolic music and show the feasibility of our approach for music genre transfer. Evaluations using separate genre classifiers show that the style transfer works well. In order to improve the fidelity of the transformed music, we add additional discriminators that cause the generators to keep the structure of the original music mostly intact, while still achieving strong genre transfer. Visual and audible results further show the potential of our approach. To the best of our knowledge, this paper represents the first application of GANs to symbolic music domain transfer.
PAC-Reasoning in Relational Domains
Jul 04, 2018We consider the problem of predicting plausible missing facts in relational data, given a set of imperfect logical rules. In particular, our aim is to provide bounds on the (expected) number of incorrect inferences that are made in this way. Since for classical inference it is in general impossible to bound this number in a non-trivial way, we consider two inference relations that weaken, but remain close in spirit to classical inference.
VC-Dimension Based Generalization Bounds for Relational Learning
Jul 04, 2018In many applications of relational learning, the available data can be seen as a sample from a larger relational structure (e.g. we may be given a small fragment from some social network). In this paper we are particularly concerned with scenarios in which we can assume that (i) the domain elements appearing in the given sample have been uniformly sampled without replacement from the (unknown) full domain and (ii) the sample is complete for these domain elements (i.e. it is the full substructure induced by these elements). Within this setting, we study bounds on the error of sufficient statistics of relational models that are estimated on the available data. As our main result, we prove a bound based on a variant of the Vapnik-Chervonenkis dimension which is suitable for relational data.
Relational Marginal Problems: Theory and Estimation
Apr 25, 2018In the propositional setting, the marginal problem is to find a (maximum-entropy) distribution that has some given marginals. We study this problem in a relational setting and make the following contributions. First, we compare two different notions of relational marginals. Second, we show a duality between the resulting relational marginal problems and the maximum likelihood estimation of the parameters of relational models, which generalizes a well-known duality from the propositional setting. Third, by exploiting the relational marginal formulation, we present a statistically sound method to learn the parameters of relational models that will be applied in settings where the number of constants differs between the training and test data. Furthermore, based on a relational generalization of marginal polytopes, we characterize cases where the standard estimators based on feature's number of true groundings needs to be adjusted and we quantitatively characterize the consequences of these adjustments. Fourth, we prove bounds on expected errors of the estimated parameters, which allows us to lower-bound, among other things, the effective sample size of relational training data.
Natural Language Multitasking: Analyzing and Improving Syntactic Saliency of Hidden Representations
Jan 18, 2018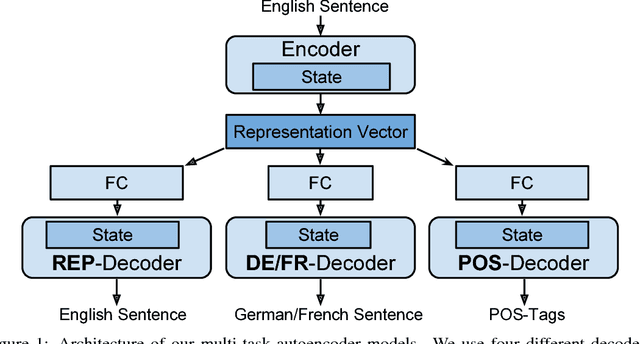
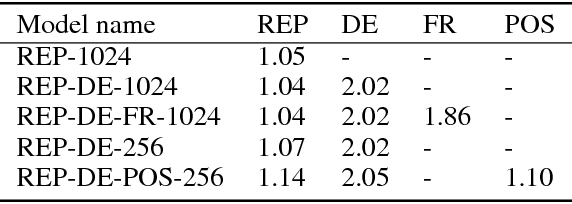


We train multi-task autoencoders on linguistic tasks and analyze the learned hidden sentence representations. The representations change significantly when translation and part-of-speech decoders are added. The more decoders a model employs, the better it clusters sentences according to their syntactic similarity, as the representation space becomes less entangled. We explore the structure of the representation space by interpolating between sentences, which yields interesting pseudo-English sentences, many of which have recognizable syntactic structure. Lastly, we point out an interesting property of our models: The difference-vector between two sentences can be added to change a third sentence with similar features in a meaningful way.