 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
May 22, 2026Identifying which brain regions represent a visual concept in the human brain is a central challenge in neuroscience. Existing approaches have localized coarse functional regions (e.g., faces, places) through activation maximization, identifying regions that activate strongly for a target concept relative to other concepts. Yet strong activation alone does not establish that a region represents the concept itself, as responses may instead be driven by correlated visual or semantic cues. We introduce BrainCause, an automated framework that combines generative and brain models to synthesize controlled stimuli and validate neural representations through targeted causal testing. Given a query specifying a concept of interest, our framework constructs targeted stimulus sets comprising concept images, counterfactual edits that remove the target concept while preserving other image content, and images with candidate correlated distractors. It then uses an image-to-fMRI encoding model to predict brain responses and searches for representations that respond specifically to the target concept over correlated alternatives. BrainCause returns validated candidate representations and proposes follow-up fMRI experiments to further test or extend its discoveries. Our approach successfully recovers known functional localizations and identifies new candidate representations across dozens of concepts, validated on both predicted and measured fMRI data. Critically, we show that without causal validation, a large fraction of localizations would be false positives, confirming that activation alone is insufficient evidence of representation.
BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain
Dec 12, 2025



Understanding how the human brain represents visual concepts, and in which brain regions these representations are encoded, remains a long-standing challenge. Decades of work have advanced our understanding of visual representations, yet brain signals remain large and complex, and the space of possible visual concepts is vast. As a result, most studies remain small-scale, rely on manual inspection, focus on specific regions and properties, and rarely include systematic validation. We present a large-scale, automated framework for discovering and explaining visual representations across the human cortex. Our method comprises two main stages. First, we discover candidate interpretable patterns in fMRI activity through unsupervised, data-driven decomposition methods. Next, we explain each pattern by identifying the set of natural images that most strongly elicit it and generating a natural-language description of their shared visual meaning. To scale this process, we introduce an automated pipeline that tests multiple candidate explanations, assigns quantitative reliability scores, and selects the most consistent description for each voxel pattern. Our framework reveals thousands of interpretable patterns spanning many distinct visual concepts, including fine-grained representations previously unreported.
DocReRank: Single-Page Hard Negative Query Generation for Training Multi-Modal RAG Rerankers
May 28, 2025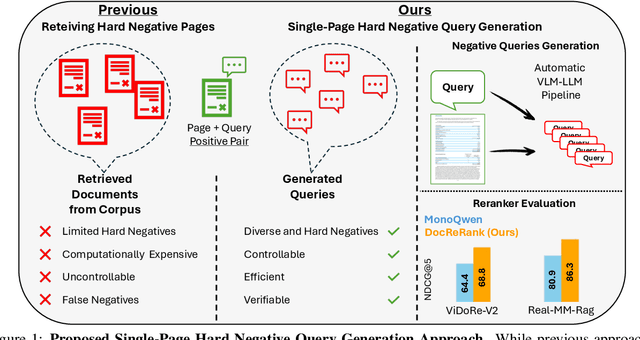
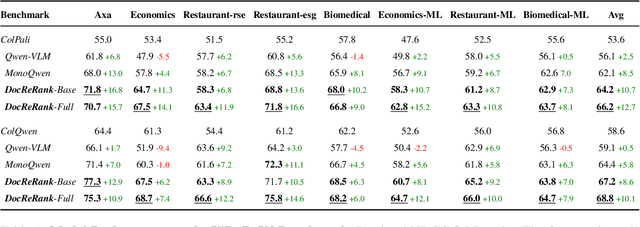

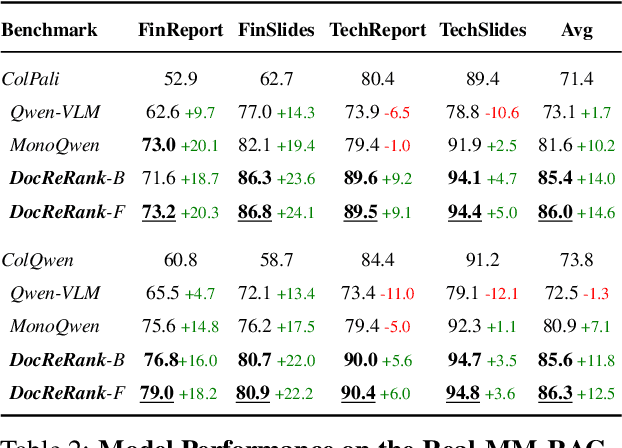
Rerankers play a critical role in multimodal Retrieval-Augmented Generation (RAG) by refining ranking of an initial set of retrieved documents. Rerankers are typically trained using hard negative mining, whose goal is to select pages for each query which rank high, but are actually irrelevant. However, this selection process is typically passive and restricted to what the retriever can find in the available corpus, leading to several inherent limitations. These include: limited diversity, negative examples which are often not hard enough, low controllability, and frequent false negatives which harm training. Our paper proposes an alternative approach: Single-Page Hard Negative Query Generation, which goes the other way around. Instead of retrieving negative pages per query, we generate hard negative queries per page. Using an automated LLM-VLM pipeline, and given a page and its positive query, we create hard negatives by rephrasing the query to be as similar as possible in form and context, yet not answerable from the page. This paradigm enables fine-grained control over the generated queries, resulting in diverse, hard, and targeted negatives. It also supports efficient false negative verification. Our experiments show that rerankers trained with data generated using our approach outperform existing models and significantly improve retrieval performance.