 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-IT-VQA: From Brain Signals to Answers
May 28, 2026Decoding visual content from fMRI signals recorded while a person views images, and specifically answering questions about the seen images, is a long-standing challenge. While significant progress has been made in recent years in visual question answering (VQA) from fMRI, performance remains limited. Moreover, although recent models can make increasingly accurate predictions, they have rarely been used as tools for understanding the structure of visual representations in the brain. We present Brain-IT-VQA, a framework for visual question answering from fMRI. Building on the Brain Interaction Transformer (Brain-IT), our method decodes language tokens from brain activity and integrates them with a language model to answer visual questions. Our model substantially outperforms previous fMRI-based captioning and VQA approaches. We further introduce NSD-VQA, a new dataset and benchmark for visual question answering from fMRI. Unlike existing image-fMRI VQA datasets, which typically provide only a few broad and weakly controlled questions per image, NSD-VQA provides on average 20 question-answer pairs per image across 20 controlled question categories that disentangle multiple levels of visual understanding. This enables more reliable and interpretable evaluation despite limited fMRI test data. Together, Brain-IT-VQA and NSD-VQA provide both a strong predictive framework and a tool for studying brain representations. Using this benchmark, we quantify which forms of visual and semantic information can be reliably decoded from fMRI responses to natural images. We further analyze the contributions of different brain regions across question types.
DocReRank: Single-Page Hard Negative Query Generation for Training Multi-Modal RAG Rerankers
May 28, 2025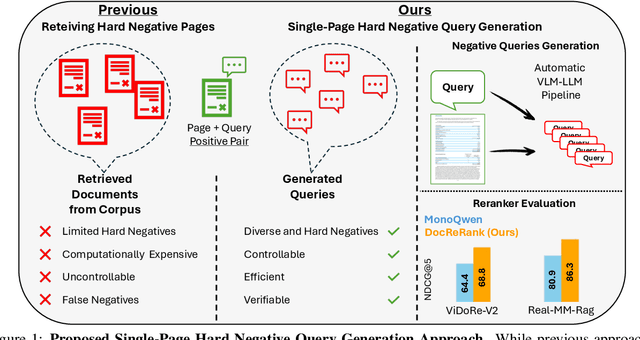
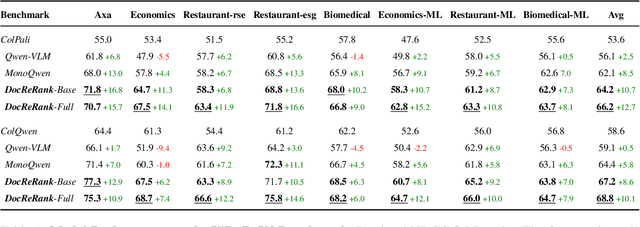

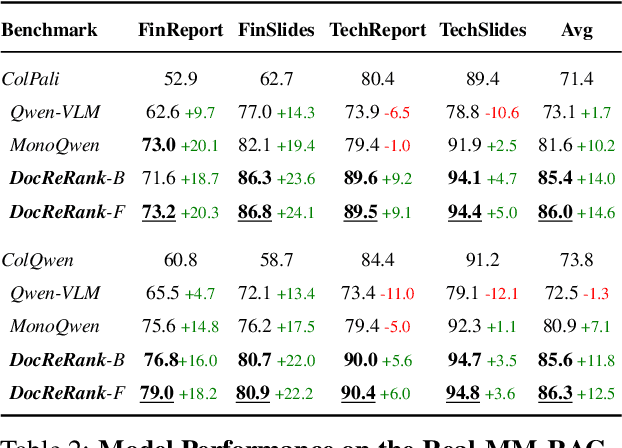
Rerankers play a critical role in multimodal Retrieval-Augmented Generation (RAG) by refining ranking of an initial set of retrieved documents. Rerankers are typically trained using hard negative mining, whose goal is to select pages for each query which rank high, but are actually irrelevant. However, this selection process is typically passive and restricted to what the retriever can find in the available corpus, leading to several inherent limitations. These include: limited diversity, negative examples which are often not hard enough, low controllability, and frequent false negatives which harm training. Our paper proposes an alternative approach: Single-Page Hard Negative Query Generation, which goes the other way around. Instead of retrieving negative pages per query, we generate hard negative queries per page. Using an automated LLM-VLM pipeline, and given a page and its positive query, we create hard negatives by rephrasing the query to be as similar as possible in form and context, yet not answerable from the page. This paradigm enables fine-grained control over the generated queries, resulting in diverse, hard, and targeted negatives. It also supports efficient false negative verification. Our experiments show that rerankers trained with data generated using our approach outperform existing models and significantly improve retrieval performance.
KernelFusion: Assumption-Free Blind Super-Resolution via Patch Diffusion
Mar 27, 2025Traditional super-resolution (SR) methods assume an ``ideal'' downscaling SR-kernel (e.g., bicubic downscaling) between the high-resolution (HR) image and the low-resolution (LR) image. Such methods fail once the LR images are generated differently. Current blind-SR methods aim to remove this assumption, but are still fundamentally restricted to rather simplistic downscaling SR-kernels (e.g., anisotropic Gaussian kernels), and fail on more complex (out of distribution) downscaling degradations. However, using the correct SR-kernel is often more important than using a sophisticated SR algorithm. In ``KernelFusion'' we introduce a zero-shot diffusion-based method that makes no assumptions about the kernel. Our method recovers the unique image-specific SR-kernel directly from the LR input image, while simultaneously recovering its corresponding HR image. KernelFusion exploits the principle that the correct SR-kernel is the one that maximizes patch similarity across different scales of the LR image. We first train an image-specific patch-based diffusion model on the single LR input image, capturing its unique internal patch statistics. We then reconstruct a larger HR image with the same learned patch distribution, while simultaneously recovering the correct downscaling SR-kernel that maintains this cross-scale relation between the HR and LR images. Empirical results show that KernelFusion vastly outperforms all SR baselines on complex downscaling degradations, where existing SotA Blind-SR methods fail miserably. By breaking free from predefined kernel assumptions, KernelFusion pushes Blind-SR into a new assumption-free paradigm, handling downscaling kernels previously thought impossible.
Don't Judge Before You CLIP: A Unified Approach for Perceptual Tasks
Mar 17, 2025



Visual perceptual tasks aim to predict human judgment of images (e.g., emotions invoked by images, image quality assessment). Unlike objective tasks such as object/scene recognition, perceptual tasks rely on subjective human assessments, making its data-labeling difficult. The scarcity of such human-annotated data results in small datasets leading to poor generalization. Typically, specialized models were designed for each perceptual task, tailored to its unique characteristics and its own training dataset. We propose a unified architectural framework for solving multiple different perceptual tasks leveraging CLIP as a prior. Our approach is based on recent cognitive findings which indicate that CLIP correlates well with human judgment. While CLIP was explicitly trained to align images and text, it implicitly also learned human inclinations. We attribute this to the inclusion of human-written image captions in CLIP's training data, which contain not only factual image descriptions, but inevitably also human sentiments and emotions. This makes CLIP a particularly strong prior for perceptual tasks. Accordingly, we suggest that minimal adaptation of CLIP suffices for solving a variety of perceptual tasks. Our simple unified framework employs a lightweight adaptation to fine-tune CLIP to each task, without requiring any task-specific architectural changes. We evaluate our approach on three tasks: (i) Image Memorability Prediction, (ii) No-reference Image Quality Assessment, and (iii) Visual Emotion Analysis. Our model achieves state-of-the-art results on all three tasks, while demonstrating improved generalization across different datasets.