 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Algorithms with Unreliable Guidance
Feb 24, 2026This paper introduces a new model for ML-augmented online decision making, called online algorithms with unreliable guidance (OAG). This model completely separates between the predictive and algorithmic components, thus offering a single well-defined analysis framework that relies solely on the considered problem. Formulated through the lens of request-answer games, an OAG algorithm receives, with each incoming request, a piece of guidance which is taken from the problem's answer space; ideally, this guidance is the optimal answer for the current request, however with probability $β$, the guidance is adversarially corrupted. The goal is to develop OAG algorithms that admit good competitiveness when $β= 0$ (a.k.a. consistency) as well as when $β= 1$ (a.k.a. robustness); the appealing notion of smoothness, that in most prior work required a dedicated loss function, now arises naturally as $β$ shifts from $0$ to $1$. We then describe a systematic method, called the drop or trust blindly (DTB) compiler, which transforms any online algorithm into a learning-augmented online algorithm in the OAG model. Given a prediction-oblivious online algorithm, its learning-augmented counterpart produced by applying the DTB compiler either follows the incoming guidance blindly or ignores it altogether and proceeds as the initial algorithm would have; the choice between these two alternatives is based on the outcome of a (biased) coin toss. As our main technical contribution, we prove (rigorously) that although remarkably simple, the class of algorithms produced via the DTB compiler includes algorithms with attractive consistency-robustness guarantees for three classic online problems: for caching and uniform metrical task systems our algorithms are optimal, whereas for bipartite matching (with adversarial arrival order), our algorithm outperforms the state-of-the-art.
Online Paging with a Vanishing Regret
Nov 19, 2020This paper considers a variant of the online paging problem, where the online algorithm has access to multiple predictors, each producing a sequence of predictions for the page arrival times. The predictors may have occasional prediction errors and it is assumed that at least one of them makes a sublinear number of prediction errors in total. Our main result states that this assumption suffices for the design of a randomized online algorithm whose time-average regret with respect to the optimal offline algorithm tends to zero as the time tends to infinity. This holds (with different regret bounds) for both the full information access model, where in each round, the online algorithm gets the predictions of all predictors, and the bandit access model, where in each round, the online algorithm queries a single predictor. While online algorithms that exploit inaccurate predictions have been a topic of growing interest in the last few years, to the best of our knowledge, this is the first paper that studies this topic in the context of multiple predictors for an online problem with unbounded request sequences. Moreover, to the best of our knowledge, this is also the first paper that aims for (and achieves) online algorithms with a vanishing regret for a classic online problem under reasonable assumptions.
Deterministic Leader Election in Programmable Matter
May 02, 2019
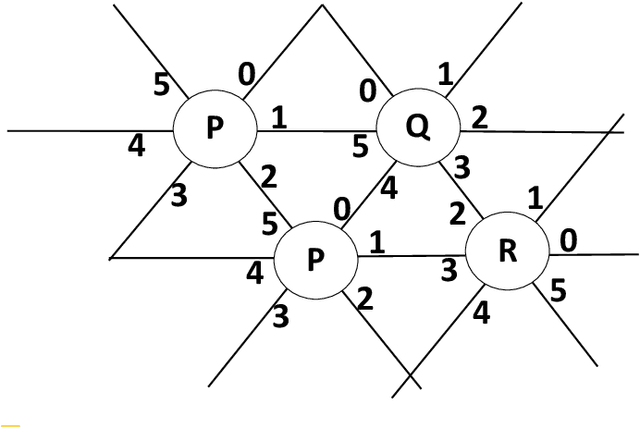
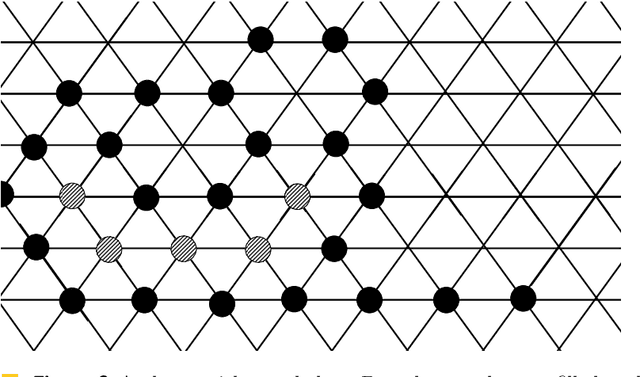
Addressing a fundamental problem in programmable matter, we present the first deterministic algorithm to elect a unique leader in a system of connected amoebots assuming only that amoebots are initially contracted. Previous algorithms either used randomization, made various assumptions (shapes with no holes, or known shared chirality), or elected several co-leaders in some cases. Some of the building blocks we introduce in constructing the algorithm are of interest by themselves, especially the procedure we present for reaching common chirality among the amoebots. Given the leader election and the chirality agreement building block, it is known that various tasks in programmable matter can be performed or improved. The main idea of the new algorithm is the usage of the ability of the amoebots to move, which previous leader election algorithms have not used.