 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAN-LOC: Spoofing Detection and Physical Intrusion Localization on an In-Vehicle CAN Bus Based on Deep Features of Voltage Signals
Jun 15, 2021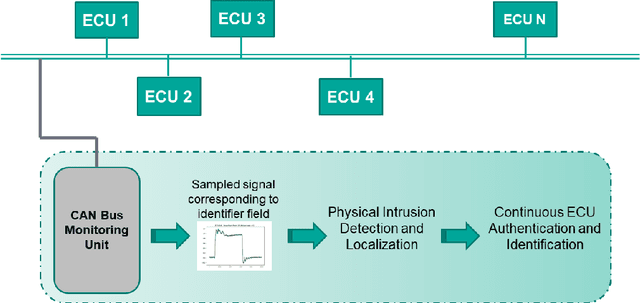

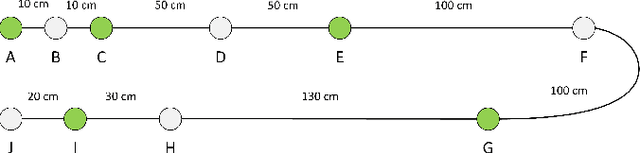
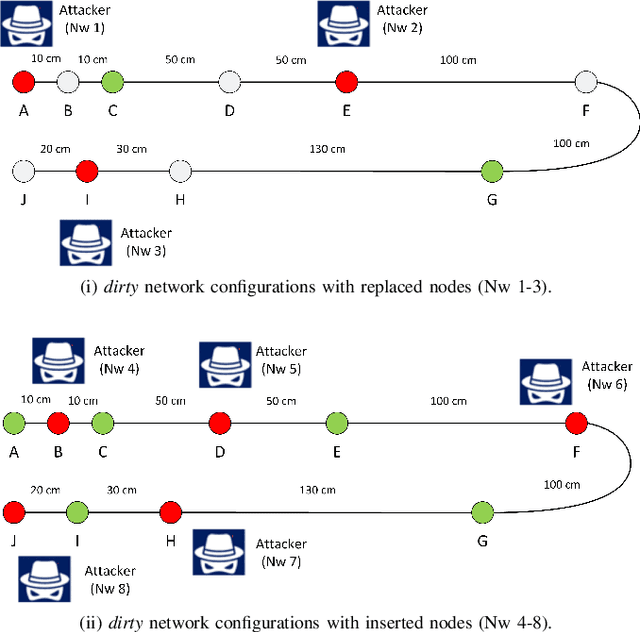
The Controller Area Network (CAN) is used for communication between in-vehicle devices. The CAN bus has been shown to be vulnerable to remote attacks. To harden vehicles against such attacks, vehicle manufacturers have divided in-vehicle networks into sub-networks, logically isolating critical devices. However, attackers may still have physical access to various sub-networks where they can connect a malicious device. This threat has not been adequately addressed, as methods proposed to determine physical intrusion points have shown weak results, emphasizing the need to develop more advanced techniques. To address this type of threat, we propose a security hardening system for in-vehicle networks. The proposed system includes two mechanisms that process deep features extracted from voltage signals measured on the CAN bus. The first mechanism uses data augmentation and deep learning to detect and locate physical intrusions when the vehicle starts; this mechanism can detect and locate intrusions, even when the connected malicious devices are silent. This mechanism's effectiveness (100% accuracy) is demonstrated in a wide variety of insertion scenarios on a CAN bus prototype. The second mechanism is a continuous device authentication mechanism, which is also based on deep learning; this mechanism's robustness (99.8% accuracy) is demonstrated on a real moving vehicle.
RadArnomaly: Protecting Radar Systems from Data Manipulation Attacks
Jun 13, 2021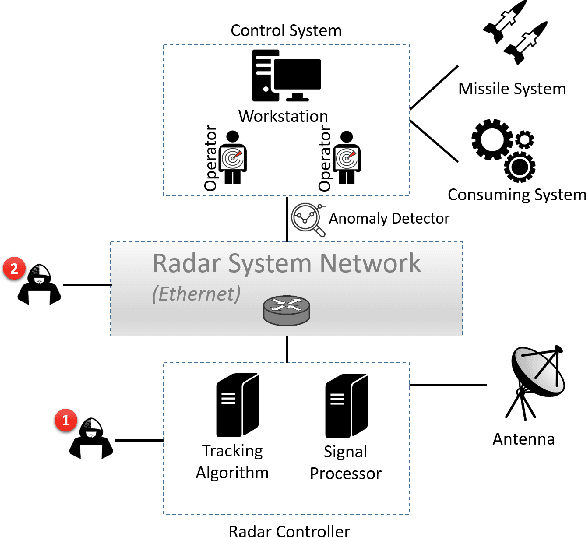
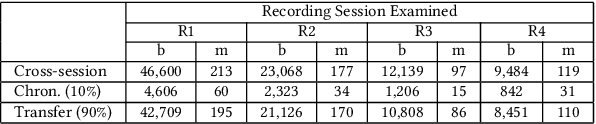
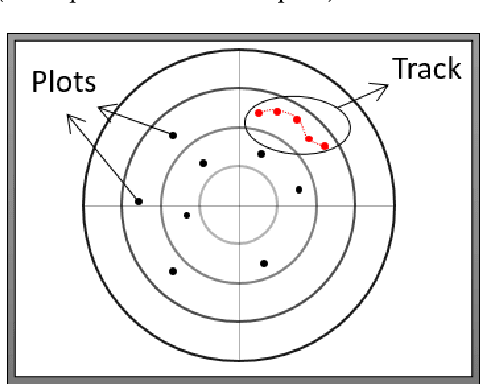
Radar systems are mainly used for tracking aircraft, missiles, satellites, and watercraft. In many cases, information regarding the objects detected by the radar system is sent to, and used by, a peripheral consuming system, such as a missile system or a graphical user interface used by an operator. Those systems process the data stream and make real-time, operational decisions based on the data received. Given this, the reliability and availability of information provided by radar systems has grown in importance. Although the field of cyber security has been continuously evolving, no prior research has focused on anomaly detection in radar systems. In this paper, we present a deep learning-based method for detecting anomalies in radar system data streams. We propose a novel technique which learns the correlation between numerical features and an embedding representation of categorical features in an unsupervised manner. The proposed technique, which allows the detection of malicious manipulation of critical fields in the data stream, is complemented by a timing-interval anomaly detection mechanism proposed for the detection of message dropping attempts. Real radar system data is used to evaluate the proposed method. Our experiments demonstrate the method's high detection accuracy on a variety of data stream manipulation attacks (average detection rate of 88% with 1.59% false alarms) and message dropping attacks (average detection rate of 92% with 2.2% false alarms).
Who's Afraid of Adversarial Transferability?
May 05, 2021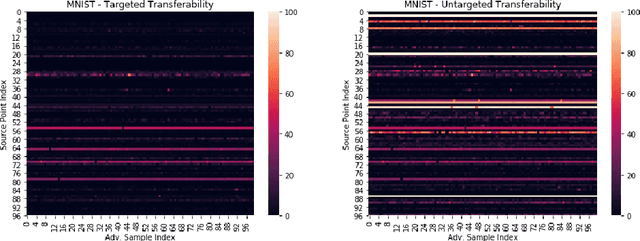

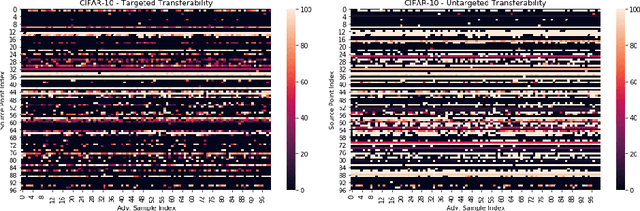
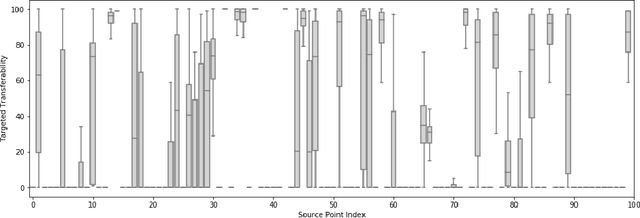
Adversarial transferability, namely the ability of adversarial perturbations to simultaneously fool multiple learning models, has long been the "big bad wolf" of adversarial machine learning. Successful transferability-based attacks requiring no prior knowledge of the attacked model's parameters or training data have been demonstrated numerous times in the past, implying that machine learning models pose an inherent security threat to real-life systems. However, all of the research performed in this area regarded transferability as a probabilistic property and attempted to estimate the percentage of adversarial examples that are likely to mislead a target model given some predefined evaluation set. As a result, those studies ignored the fact that real-life adversaries are often highly sensitive to the cost of a failed attack. We argue that overlooking this sensitivity has led to an exaggerated perception of the transferability threat, when in fact real-life transferability-based attacks are quite unlikely. By combining theoretical reasoning with a series of empirical results, we show that it is practically impossible to predict whether a given adversarial example is transferable to a specific target model in a black-box setting, hence questioning the validity of adversarial transferability as a real-life attack tool for adversaries that are sensitive to the cost of a failed attack.
TANTRA: Timing-Based Adversarial Network Traffic Reshaping Attack
Mar 10, 2021
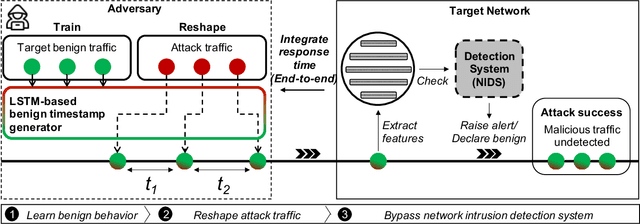
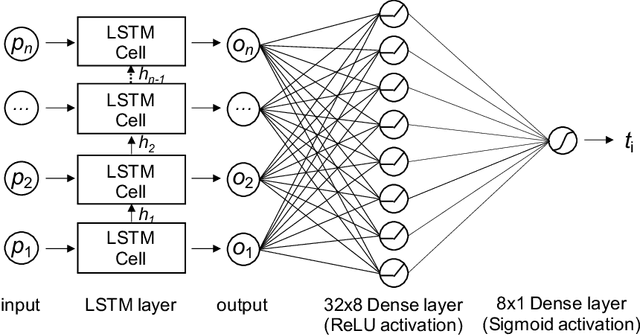
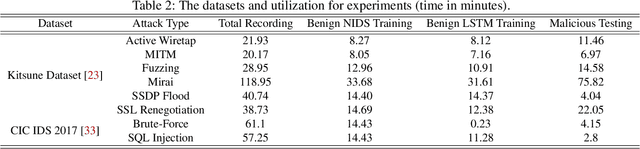
Network intrusion attacks are a known threat. To detect such attacks, network intrusion detection systems (NIDSs) have been developed and deployed. These systems apply machine learning models to high-dimensional vectors of features extracted from network traffic to detect intrusions. Advances in NIDSs have made it challenging for attackers, who must execute attacks without being detected by these systems. Prior research on bypassing NIDSs has mainly focused on perturbing the features extracted from the attack traffic to fool the detection system, however, this may jeopardize the attack's functionality. In this work, we present TANTRA, a novel end-to-end Timing-based Adversarial Network Traffic Reshaping Attack that can bypass a variety of NIDSs. Our evasion attack utilizes a long short-term memory (LSTM) deep neural network (DNN) which is trained to learn the time differences between the target network's benign packets. The trained LSTM is used to set the time differences between the malicious traffic packets (attack), without changing their content, such that they will "behave" like benign network traffic and will not be detected as an intrusion. We evaluate TANTRA on eight common intrusion attacks and three state-of-the-art NIDS systems, achieving an average success rate of 99.99\% in network intrusion detection system evasion. We also propose a novel mitigation technique to address this new evasion attack.
Enhancing Real-World Adversarial Patches with 3D Modeling Techniques
Feb 10, 2021
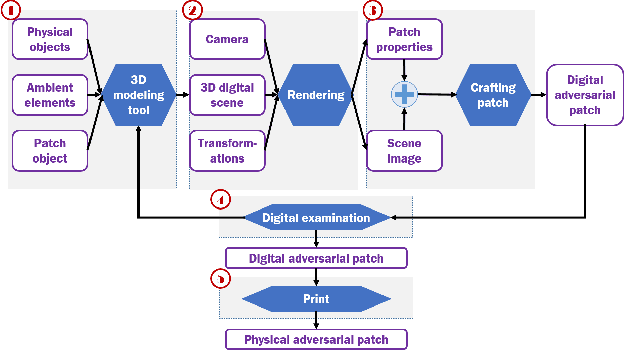


Although many studies have examined adversarial examples in the real world, most of them relied on 2D photos of the attack scene; thus, the attacks proposed cannot address realistic environments with 3D objects or varied conditions. Studies that use 3D objects are limited, and in many cases, the real-world evaluation process is not replicable by other researchers, preventing others from reproducing the results. In this study, we present a framework that crafts an adversarial patch for an existing real-world scene. Our approach uses a 3D digital approximation of the scene as a simulation of the real world. With the ability to add and manipulate any element in the digital scene, our framework enables the attacker to improve the patch's robustness in real-world settings. We use the framework to create a patch for an everyday scene and evaluate its performance using a novel evaluation process that ensures that our results are reproducible in both the digital space and the real world. Our evaluation results show that the framework can generate adversarial patches that are robust to different settings in the real world.
BENN: Bias Estimation Using Deep Neural Network
Dec 23, 2020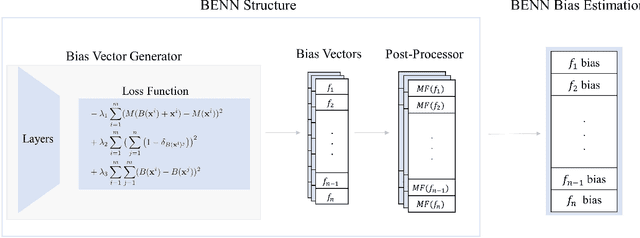

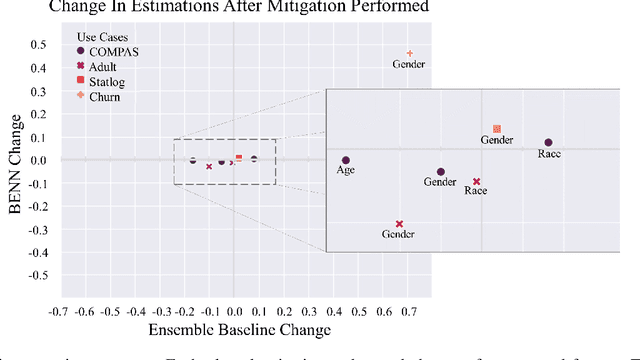
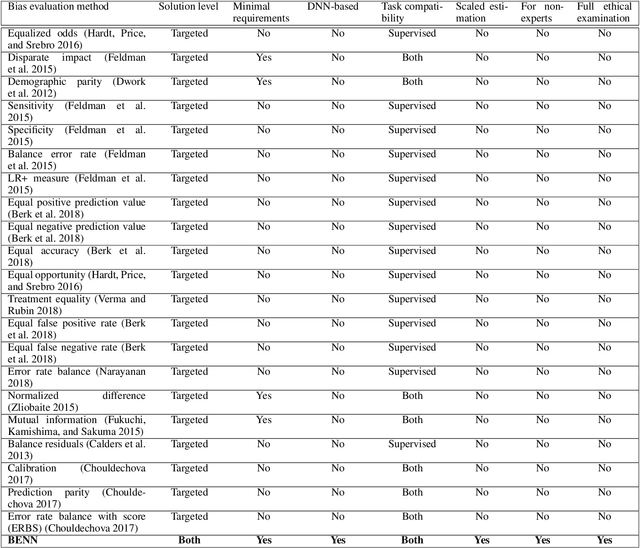
The need to detect bias in machine learning (ML) models has led to the development of multiple bias detection methods, yet utilizing them is challenging since each method: i) explores a different ethical aspect of bias, which may result in contradictory output among the different methods, ii) provides an output of a different range/scale and therefore, can't be compared with other methods, and iii) requires different input, and therefore a human expert needs to be involved to adjust each method according to the examined model. In this paper, we present BENN -- a novel bias estimation method that uses a pretrained unsupervised deep neural network. Given a ML model and data samples, BENN provides a bias estimation for every feature based on the model's predictions. We evaluated BENN using three benchmark datasets and one proprietary churn prediction model used by a European Telco and compared it with an ensemble of 21 existing bias estimation methods. Evaluation results highlight the significant advantages of BENN over the ensemble, as it is generic (i.e., can be applied to any ML model) and there is no need for a domain expert, yet it provides bias estimations that are aligned with those of the ensemble.
The Translucent Patch: A Physical and Universal Attack on Object Detectors
Dec 23, 2020
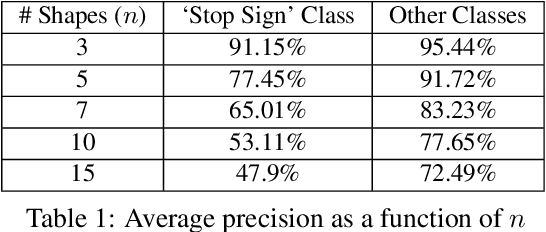

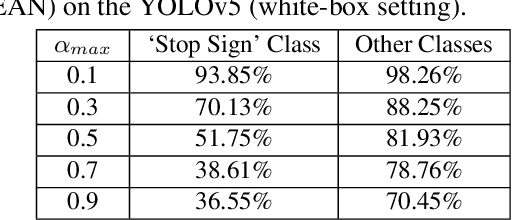
Physical adversarial attacks against object detectors have seen increasing success in recent years. However, these attacks require direct access to the object of interest in order to apply a physical patch. Furthermore, to hide multiple objects, an adversarial patch must be applied to each object. In this paper, we propose a contactless translucent physical patch containing a carefully constructed pattern, which is placed on the camera's lens, to fool state-of-the-art object detectors. The primary goal of our patch is to hide all instances of a selected target class. In addition, the optimization method used to construct the patch aims to ensure that the detection of other (untargeted) classes remains unharmed. Therefore, in our experiments, which are conducted on state-of-the-art object detection models used in autonomous driving, we study the effect of the patch on the detection of both the selected target class and the other classes. We show that our patch was able to prevent the detection of 42.27% of all stop sign instances while maintaining high (nearly 80%) detection of the other classes.
Detection of Adversarial Supports in Few-shot Classifiers Using Feature Preserving Autoencoders and Self-Similarity
Dec 09, 2020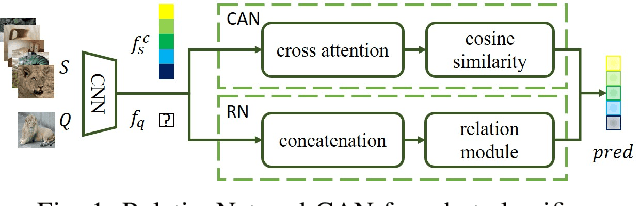
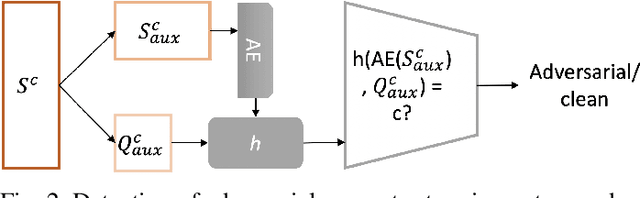
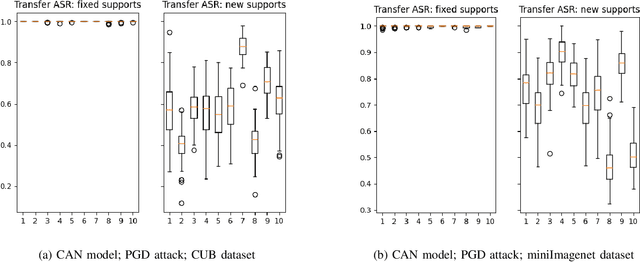
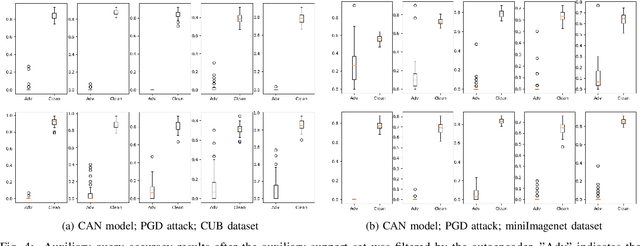
Few-shot classifiers excel under limited training samples, making it useful in real world applications. However, the advent of adversarial samples threatens the efficacy of such classifiers. For them to remain reliable, defences against such attacks must be explored. However, closer examination to prior literature reveals a big gap in this domain. Hence, in this work, we propose a detection strategy to highlight adversarial support sets, aiming to destroy a few-shot classifier's understanding of a certain class of objects. We make use of feature preserving autoencoder filtering and also the concept of self-similarity of a support set to perform this detection. As such, our method is attack-agnostic and also the first to explore detection for few-shot classifiers to the best of our knowledge. Our evaluation on the miniImagenet and CUB datasets exhibit optimism when employing our proposed approach, showing high AUROC scores for detection in general.
Deja vu from the SVM Era: Example-based Explanations with Outlier Detection
Nov 11, 2020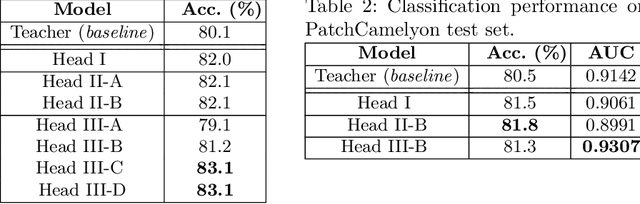
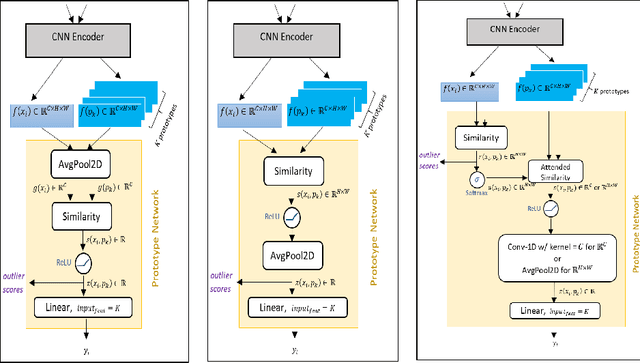
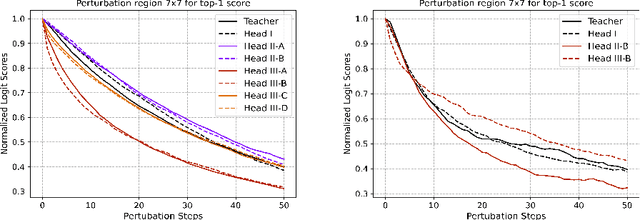
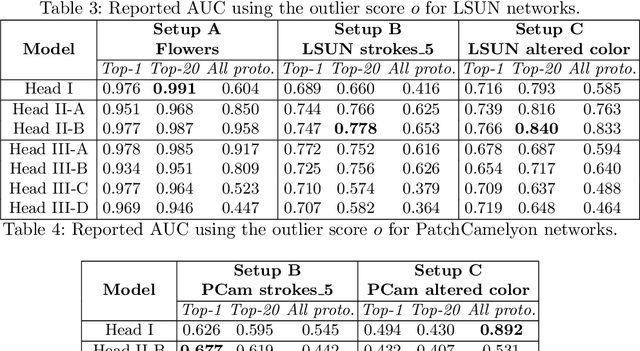
Understanding the features that contributed to a prediction is important for high-stake tasks. In this work, we revisit the idea of a student network to provide an example-based explanation for its prediction in two forms: i) identify top-k most relevant prototype examples and ii) show evidence of similarity between the prediction sample and each of the top-k prototypes. We compare the prediction performance and the explanation performance for the second type of explanation with the teacher network. In addition, we evaluate the outlier detection performance of the network. We show that using prototype-based students beyond similarity kernels deliver meaningful explanations and promising outlier detection results, without compromising on classification accuracy.
Being Single Has Benefits. Instance Poisoning to Deceive Malware Classifiers
Oct 30, 2020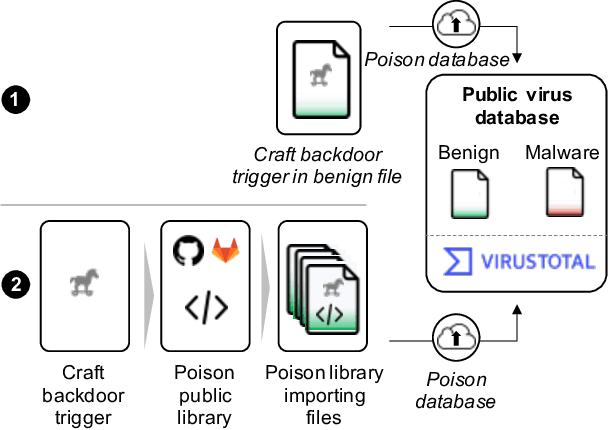
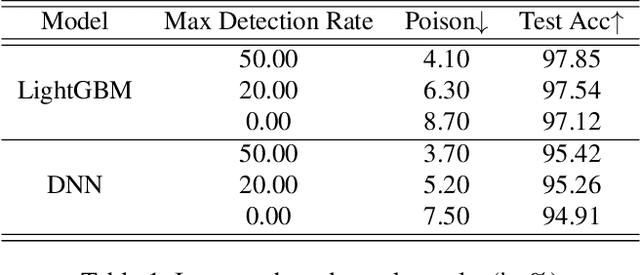
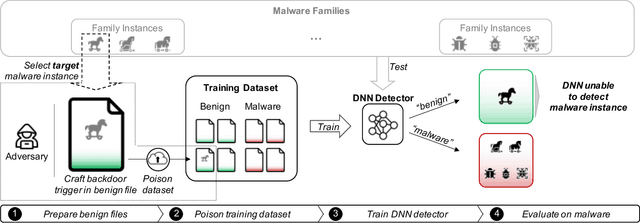
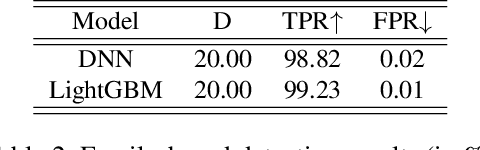
The performance of a machine learning-based malware classifier depends on the large and updated training set used to induce its model. In order to maintain an up-to-date training set, there is a need to continuously collect benign and malicious files from a wide range of sources, providing an exploitable target to attackers. In this study, we show how an attacker can launch a sophisticated and efficient poisoning attack targeting the dataset used to train a malware classifier. The attacker's ultimate goal is to ensure that the model induced by the poisoned dataset will be unable to detect the attacker's malware yet capable of detecting other malware. As opposed to other poisoning attacks in the malware detection domain, our attack does not focus on malware families but rather on specific malware instances that contain an implanted trigger, reducing the detection rate from 99.23% to 0% depending on the amount of poisoning. We evaluate our attack on the EMBER dataset with a state-of-the-art classifier and malware samples from VirusTotal for end-to-end validation of our work. We propose a comprehensive detection approach that could serve as a future sophisticated defense against this newly discovered severe threat.