 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferability Ranking of Adversarial Examples
Aug 23, 2022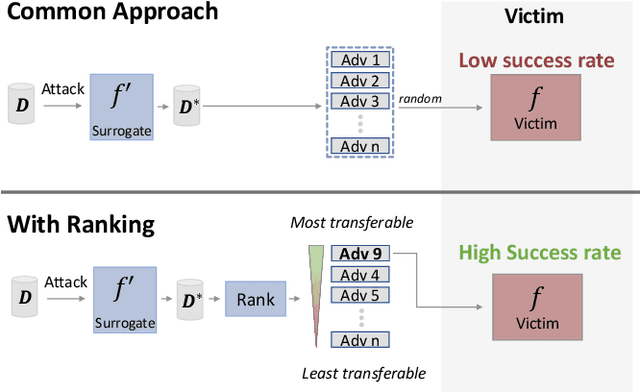

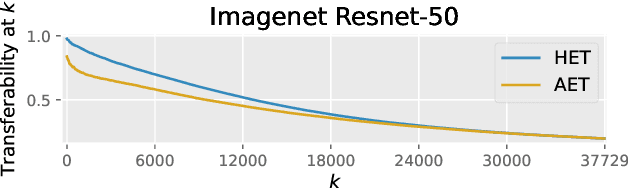
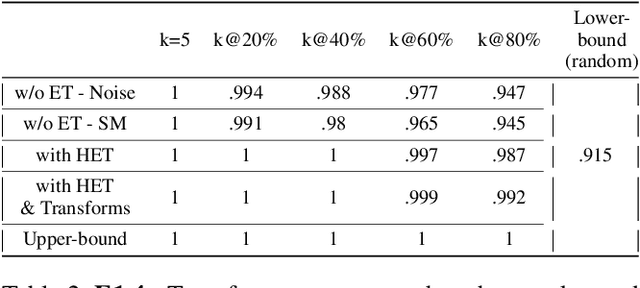
Adversarial examples can be used to maliciously and covertly change a model's prediction. It is known that an adversarial example designed for one model can transfer to other models as well. This poses a major threat because it means that attackers can target systems in a blackbox manner. In the domain of transferability, researchers have proposed ways to make attacks more transferable and to make models more robust to transferred examples. However, to the best of our knowledge, there are no works which propose a means for ranking the transferability of an adversarial example in the perspective of a blackbox attacker. This is an important task because an attacker is likely to use only a select set of examples, and therefore will want to select the samples which are most likely to transfer. In this paper we suggest a method for ranking the transferability of adversarial examples without access to the victim's model. To accomplish this, we define and estimate the expected transferability of a sample given limited information about the victim. We also explore practical scenarios: where the adversary can select the best sample to attack and where the adversary must use a specific sample but can choose different perturbations. Through our experiments, we found that our ranking method can increase an attacker's success rate by up to 80% compared to the baseline (random selection without ranking).
WinoGAViL: Gamified Association Benchmark to Challenge Vision-and-Language Models
Jul 25, 2022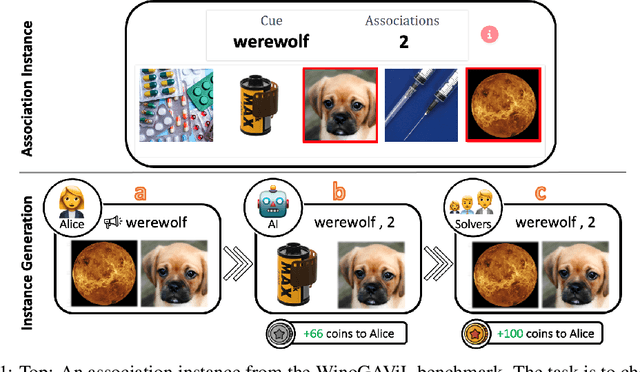
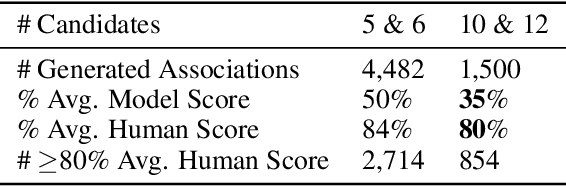

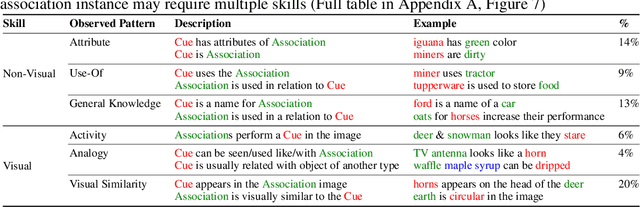
While vision-and-language models perform well on tasks such as visual question answering, they struggle when it comes to basic human commonsense reasoning skills. In this work, we introduce WinoGAViL: an online game to collect vision-and-language associations, (e.g., werewolves to a full moon), used as a dynamic benchmark to evaluate state-of-the-art models. Inspired by the popular card game Codenames, a spymaster gives a textual cue related to several visual candidates, and another player has to identify them. Human players are rewarded for creating associations that are challenging for a rival AI model but still solvable by other human players. We use the game to collect 3.5K instances, finding that they are intuitive for humans (>90% Jaccard index) but challenging for state-of-the-art AI models, where the best model (ViLT) achieves a score of 52%, succeeding mostly where the cue is visually salient. Our analysis as well as the feedback we collect from players indicate that the collected associations require diverse reasoning skills, including general knowledge, common sense, abstraction, and more. We release the dataset, the code and the interactive game, aiming to allow future data collection that can be used to develop models with better association abilities.
EyeDAS: Securing Perception of Autonomous Cars Against the Stereoblindness Syndrome
May 13, 2022
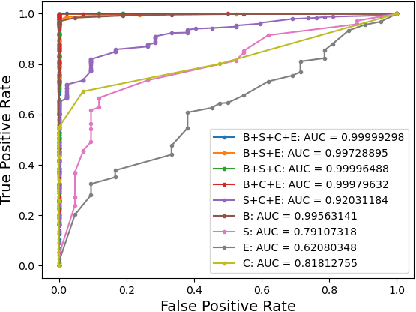
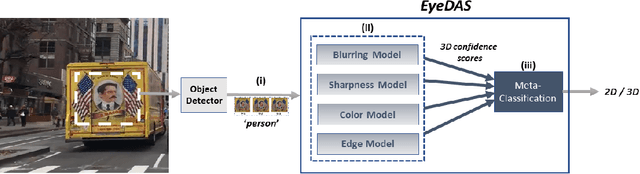

The ability to detect whether an object is a 2D or 3D object is extremely important in autonomous driving, since a detection error can have life-threatening consequences, endangering the safety of the driver, passengers, pedestrians, and others on the road. Methods proposed to distinguish between 2 and 3D objects (e.g., liveness detection methods) are not suitable for autonomous driving, because they are object dependent or do not consider the constraints associated with autonomous driving (e.g., the need for real-time decision-making while the vehicle is moving). In this paper, we present EyeDAS, a novel few-shot learning-based method aimed at securing an object detector (OD) against the threat posed by the stereoblindness syndrome (i.e., the inability to distinguish between 2D and 3D objects). We evaluate EyeDAS's real-time performance using 2,000 objects extracted from seven YouTube video recordings of street views taken by a dash cam from the driver's seat perspective. When applying EyeDAS to seven state-of-the-art ODs as a countermeasure, EyeDAS was able to reduce the 2D misclassification rate from 71.42-100% to 2.4% with a 3D misclassification rate of 0% (TPR of 1.0). We also show that EyeDAS outperforms the baseline method and achieves an AUC of over 0.999 and a TPR of 1.0 with an FPR of 0.024.
The Security of Deep Learning Defences for Medical Imaging
Jan 21, 2022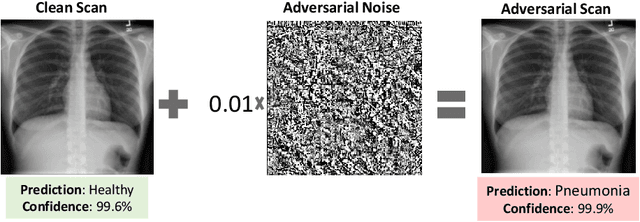
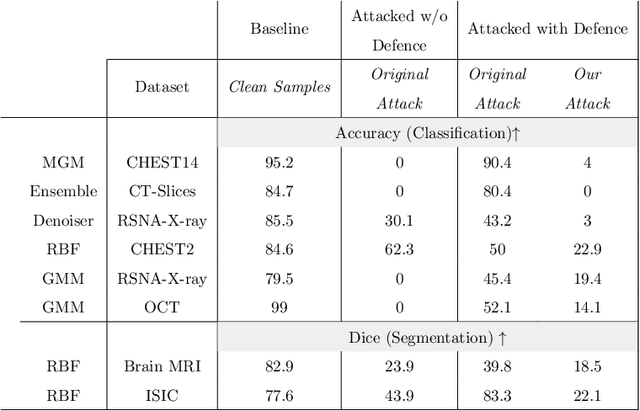
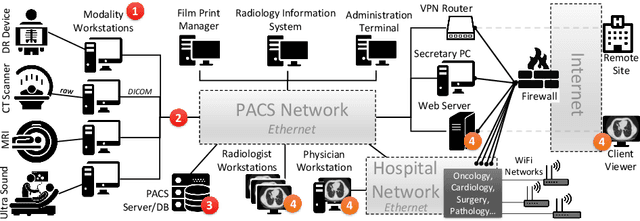
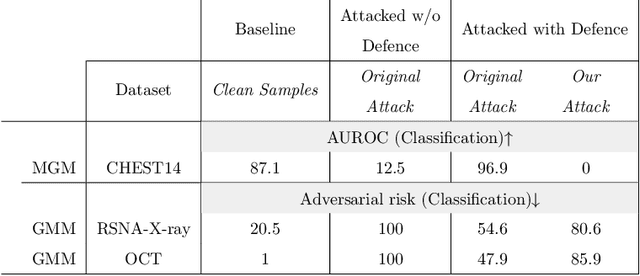
Deep learning has shown great promise in the domain of medical image analysis. Medical professionals and healthcare providers have been adopting the technology to speed up and enhance their work. These systems use deep neural networks (DNN) which are vulnerable to adversarial samples; images with imperceivable changes that can alter the model's prediction. Researchers have proposed defences which either make a DNN more robust or detect the adversarial samples before they do harm. However, none of these works consider an informed attacker which can adapt to the defence mechanism. We show that an informed attacker can evade five of the current state of the art defences while successfully fooling the victim's deep learning model, rendering these defences useless. We then suggest better alternatives for securing healthcare DNNs from such attacks: (1) harden the system's security and (2) use digital signatures.
Adversarial Machine Learning Threat Analysis in Open Radio Access Networks
Jan 16, 2022The Open Radio Access Network (O-RAN) is a new, open, adaptive, and intelligent RAN architecture. Motivated by the success of artificial intelligence in other domains, O-RAN strives to leverage machine learning (ML) to automatically and efficiently manage network resources in diverse use cases such as traffic steering, quality of experience prediction, and anomaly detection. Unfortunately, ML-based systems are not free of vulnerabilities; specifically, they suffer from a special type of logical vulnerabilities that stem from the inherent limitations of the learning algorithms. To exploit these vulnerabilities, an adversary can utilize an attack technique referred to as adversarial machine learning (AML). These special type of attacks has already been demonstrated in recent researches. In this paper, we present a systematic AML threat analysis for the O-RAN. We start by reviewing relevant ML use cases and analyzing the different ML workflow deployment scenarios in O-RAN. Then, we define the threat model, identifying potential adversaries, enumerating their adversarial capabilities, and analyzing their main goals. Finally, we explore the various AML threats in the O-RAN and review a large number of attacks that can be performed to materialize these threats and demonstrate an AML attack on a traffic steering model.
Adversarial Mask: Real-World Adversarial Attack Against Face Recognition Models
Nov 21, 2021
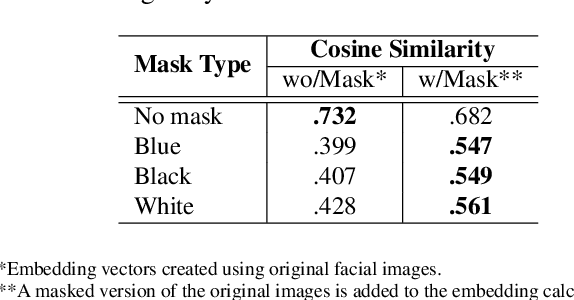
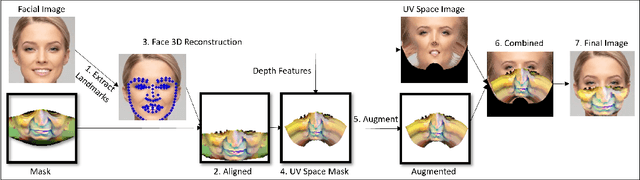
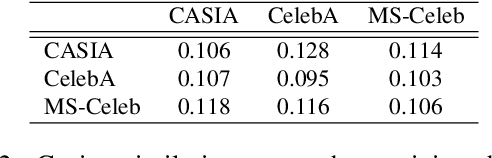
Deep learning-based facial recognition (FR) models have demonstrated state-of-the-art performance in the past few years, even when wearing protective medical face masks became commonplace during the COVID-19 pandemic. Given the outstanding performance of these models, the machine learning research community has shown increasing interest in challenging their robustness. Initially, researchers presented adversarial attacks in the digital domain, and later the attacks were transferred to the physical domain. However, in many cases, attacks in the physical domain are conspicuous, requiring, for example, the placement of a sticker on the face, and thus may raise suspicion in real-world environments (e.g., airports). In this paper, we propose Adversarial Mask, a physical adversarial universal perturbation (UAP) against state-of-the-art FR models that is applied on face masks in the form of a carefully crafted pattern. In our experiments, we examined the transferability of our adversarial mask to a wide range of FR model architectures and datasets. In addition, we validated our adversarial mask effectiveness in real-world experiments by printing the adversarial pattern on a fabric medical face mask, causing the FR system to identify only 3.34% of the participants wearing the mask (compared to a minimum of 83.34% with other evaluated masks).
Towards A Conceptually Simple Defensive Approach for Few-shot classifiers Against Adversarial Support Samples
Oct 24, 2021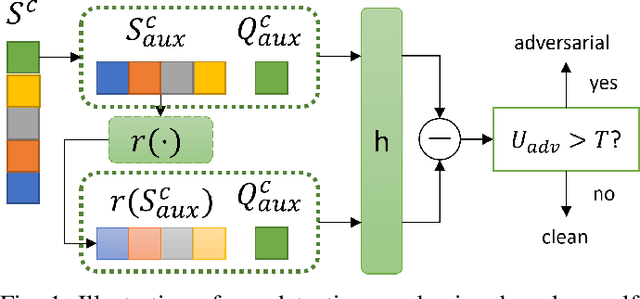
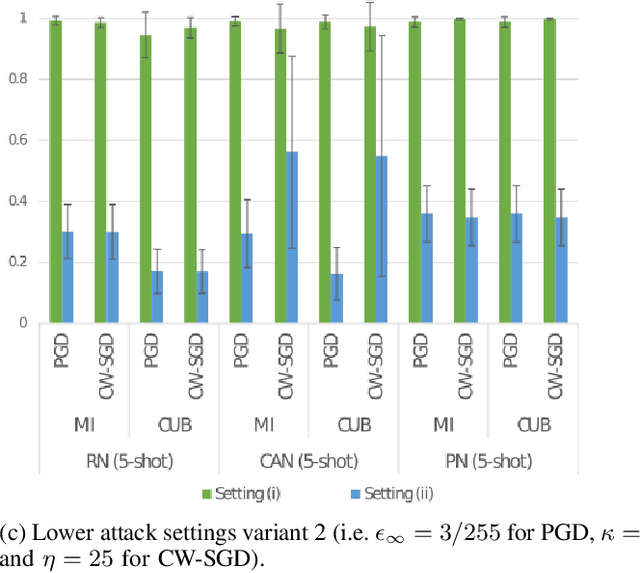
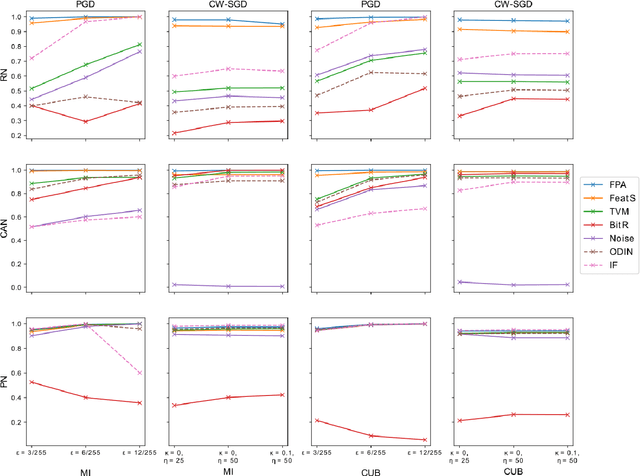
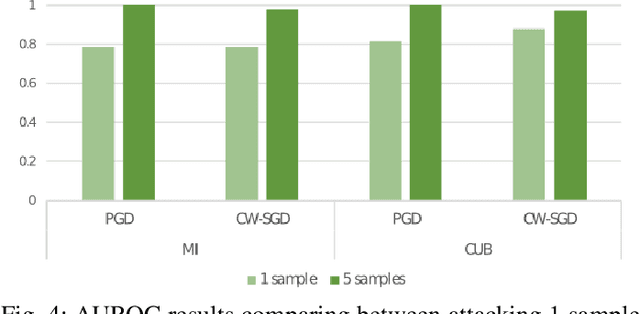
Few-shot classifiers have been shown to exhibit promising results in use cases where user-provided labels are scarce. These models are able to learn to predict novel classes simply by training on a non-overlapping set of classes. This can be largely attributed to the differences in their mechanisms as compared to conventional deep networks. However, this also offers new opportunities for novel attackers to induce integrity attacks against such models, which are not present in other machine learning setups. In this work, we aim to close this gap by studying a conceptually simple approach to defend few-shot classifiers against adversarial attacks. More specifically, we propose a simple attack-agnostic detection method, using the concept of self-similarity and filtering, to flag out adversarial support sets which destroy the understanding of a victim classifier for a certain class. Our extended evaluation on the miniImagenet (MI) and CUB datasets exhibit good attack detection performance, across three different few-shot classifiers and across different attack strengths, beating baselines. Our observed results allow our approach to establishing itself as a strong detection method for support set poisoning attacks. We also show that our approach constitutes a generalizable concept, as it can be paired with other filtering functions. Finally, we provide an analysis of our results when we vary two components found in our detection approach.
Dodging Attack Using Carefully Crafted Natural Makeup
Sep 14, 2021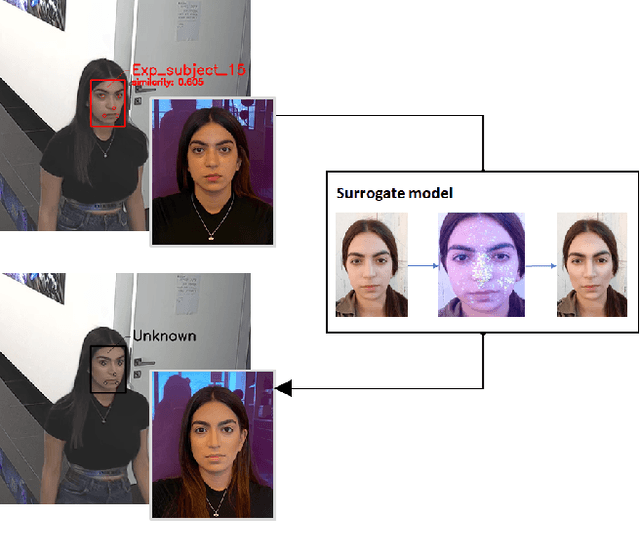

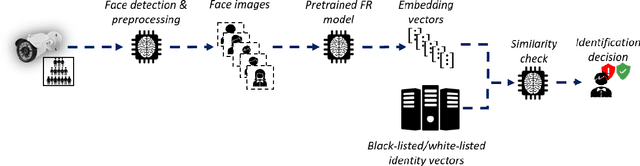
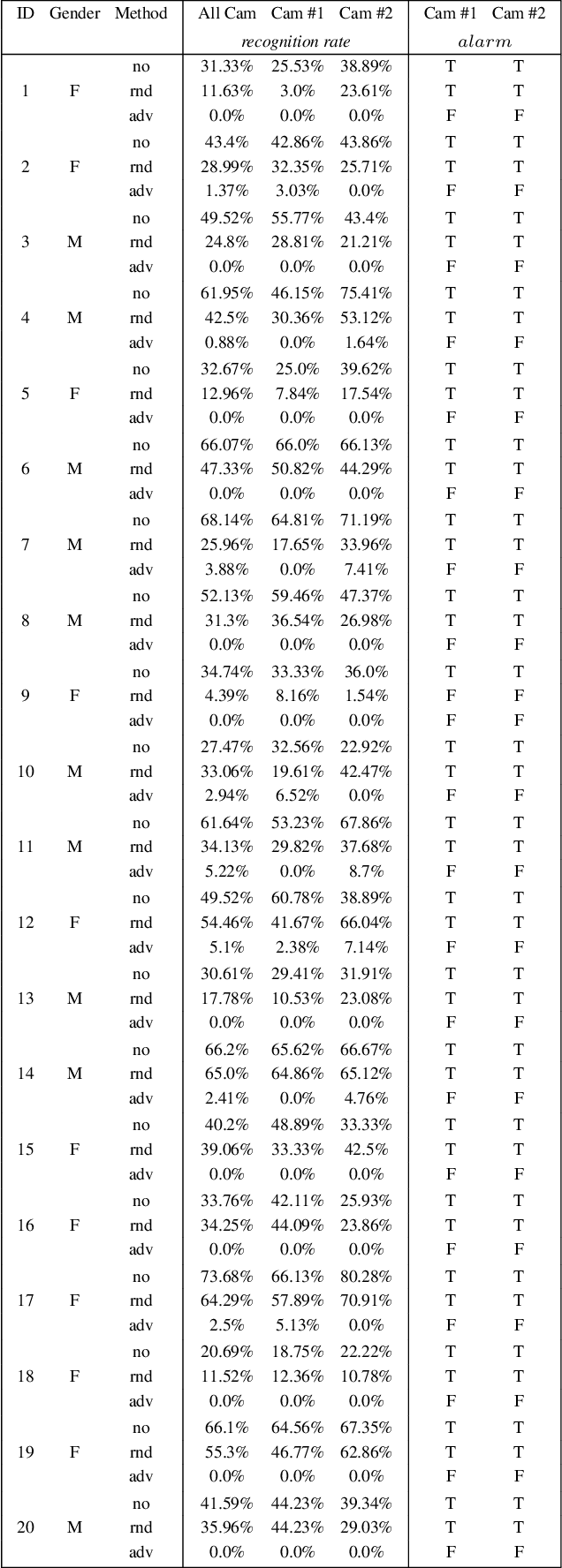
Deep learning face recognition models are used by state-of-the-art surveillance systems to identify individuals passing through public areas (e.g., airports). Previous studies have demonstrated the use of adversarial machine learning (AML) attacks to successfully evade identification by such systems, both in the digital and physical domains. Attacks in the physical domain, however, require significant manipulation to the human participant's face, which can raise suspicion by human observers (e.g. airport security officers). In this study, we present a novel black-box AML attack which carefully crafts natural makeup, which, when applied on a human participant, prevents the participant from being identified by facial recognition models. We evaluated our proposed attack against the ArcFace face recognition model, with 20 participants in a real-world setup that includes two cameras, different shooting angles, and different lighting conditions. The evaluation results show that in the digital domain, the face recognition system was unable to identify all of the participants, while in the physical domain, the face recognition system was able to identify the participants in only 1.22% of the frames (compared to 47.57% without makeup and 33.73% with random natural makeup), which is below a reasonable threshold of a realistic operational environment.
A Framework for Evaluating the Cybersecurity Risk of Real World, Machine Learning Production Systems
Jul 05, 2021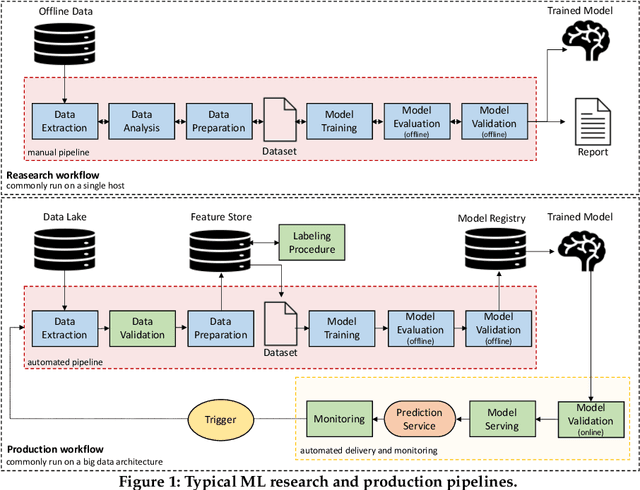

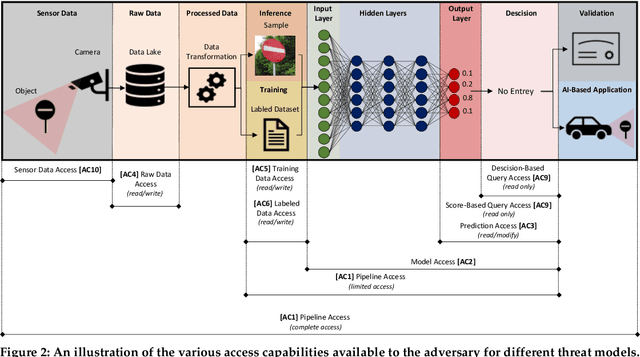
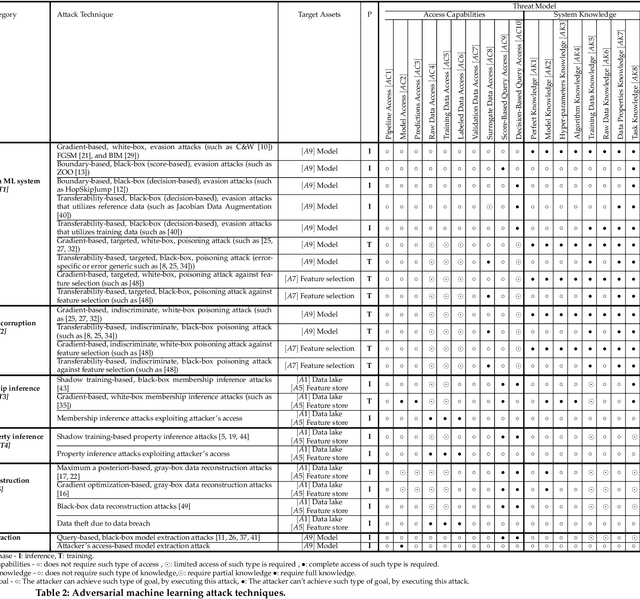
Although cyberattacks on machine learning (ML) production systems can be destructive, many industry practitioners are ill equipped, lacking tactical and strategic tools that would allow them to analyze, detect, protect against, and respond to cyberattacks targeting their ML-based systems. In this paper, we take a significant step toward securing ML production systems by integrating these systems and their vulnerabilities into cybersecurity risk assessment frameworks. Specifically, we performed a comprehensive threat analysis of ML production systems and developed an extension to the MulVAL attack graph generation and analysis framework to incorporate cyberattacks on ML production systems. Using the proposed extension, security practitioners can apply attack graph analysis methods in environments that include ML components, thus providing security experts with a practical tool for evaluating the impact and quantifying the risk of a cyberattack targeting an ML production system.
The Threat of Offensive AI to Organizations
Jun 30, 2021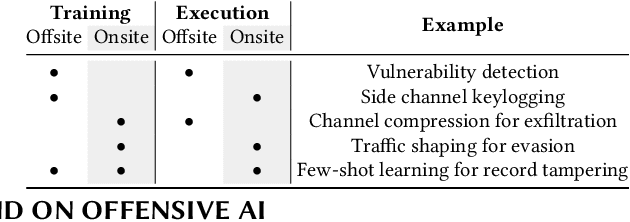
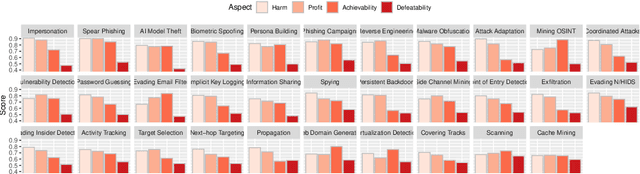
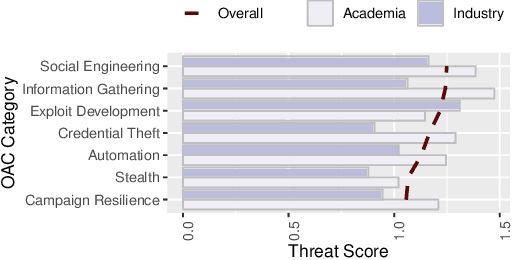
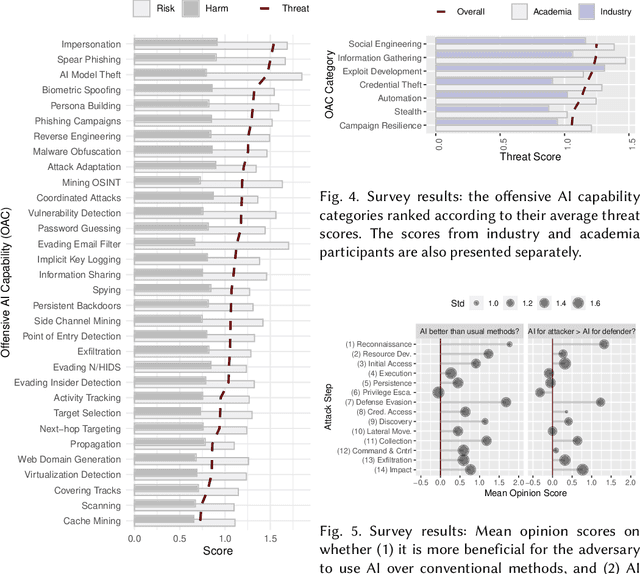
AI has provided us with the ability to automate tasks, extract information from vast amounts of data, and synthesize media that is nearly indistinguishable from the real thing. However, positive tools can also be used for negative purposes. In particular, cyber adversaries can use AI (such as machine learning) to enhance their attacks and expand their campaigns. Although offensive AI has been discussed in the past, there is a need to analyze and understand the threat in the context of organizations. For example, how does an AI-capable adversary impact the cyber kill chain? Does AI benefit the attacker more than the defender? What are the most significant AI threats facing organizations today and what will be their impact on the future? In this survey, we explore the threat of offensive AI on organizations. First, we present the background and discuss how AI changes the adversary's methods, strategies, goals, and overall attack model. Then, through a literature review, we identify 33 offensive AI capabilities which adversaries can use to enhance their attacks. Finally, through a user study spanning industry and academia, we rank the AI threats and provide insights on the adversaries.